머신러닝과 딥러닝 중 무엇을 선택할지 고민되는 경우에는 고성능 GPU와 대량의 레이블이 지정된 학습용 이미지를 보유하고 있는지를 중점적으로 고려해야 한다
객체 인식이란? 이미지 또는 비디오 상의 객체를 식별하는 컴퓨터 비전 기술로 객체 인식은 딥러닝과 머신러닝 알고리즘을 통해 산출되는 핵심 기술이다. 사람은 사진 또는 비디오를 볼 때 인물, 물체, 장면 및 시각적 세부 사항을 쉽게 알아볼 수 있다. 이처럼 사람이라면 당연히 할 수 있는 일을 컴퓨터가 할 수 있도록 학습시키는 것을 말한다. 본고에서는 매트랩(MATLAB)을 활용한 객체인식에서 반드시 알아야 할 3가지를 알아본다.
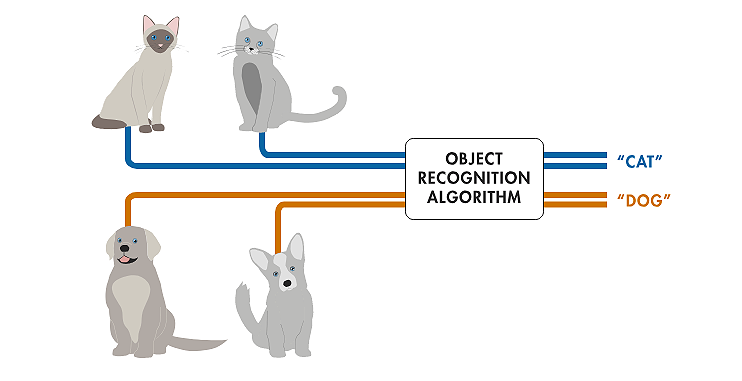
객체 인식 기술은 의료 이미징에서의 질병 식별과 산업 검사 및 로봇비전 등과 같은 다양한 분야에서 활용할 수 있다. 특히, 무인 자동차에서 가장 많이 활용되는 핵심 기술로 자동차가 정지 신호를 인식하고 보행자와 가로등을 구별할 수 있도록 한다.
그럼, 객체 인식과 객체 감지의 차이점은 무엇인가? 객체 감지(Object detection)와 객체 인식(Object recognition)은 서로 유사한 객체 식별 기술이지만, 실행 방식은 서로 다르다. 객체 감지는 이미지에서 객체의 인스턴스를 찾아내는 프로세스로 딥러닝의 경우 객체 감지는 이미지에서 객체를 식별할 뿐만 아니라 위치까지 파악되는 객체 인식의 서브셋이다. 이를 통해 하나의 이미지에서 여러 객체를 식별하고 각 위치를 파악할 수 있다.

객체 인식에는 다양한 접근 방식을 사용할 수 있다. 최근 머신러닝과 딥러닝 기술이 객체 인식 문제에 접근하는 방식으로 널리 사용되고 있다. 두 기술은 이미지에서 객체를 식별하는 방법을 학습하지만, 실행 방식은 서로 다르다. 그럼, 객체 인식에 사용되는 머신 러닝과 딥러닝의 차이점은 무엇이며, 두 기술을 구현하는 방법을 알아본다.
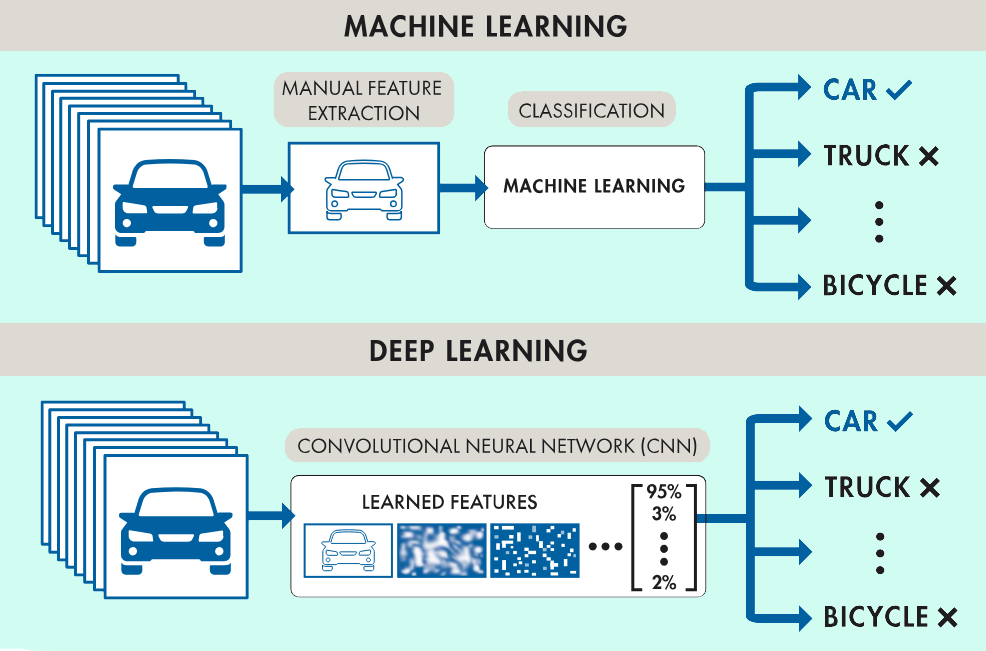
첫번째, 딥러닝을 사용한 객체 인식에는 컨벌루션 뉴럴 네트워크(CNN)과 같은 딥러닝 모델은 객체를 식별하기 위해 해당 객체 고유의 특징을 자동으로 학습하는 데 사용된다. 예를 들어 CNN에서는 수천 장의 훈련용 이미지를 분석하고 고양이와 개를 구분하는 특징을 학습하여 고양이와 개의 차이점을 식별하는 방법을 학습할 수 있으며, 딥러닝을 사용하여 객체 인식을 실시하는 두 가지 접근 방식이 있다.
먼저, 기초부터 딥 네트워크를 훈련시키기 위해서는 레이블이 지정된, 매우 방대한 데이터 세트를 모으고, 네트워크 아키텍처를 설계하여 특징을 학습하고 모델을 완성시킨다. 이를 통해 뛰어난 결과물을 얻을 수 있지만, 이러한 접근 방식을 위해서는 방대한 분량의 훈련 데이터가 필요하고 CNN에 레이어와 가중치를 설정해야 한다.
그리고 사전 훈련된 딥러닝 모델 사용하는 방법으로 대다수 딥러닝 응용 프로그램은 사전 훈련된 모델을 세밀하게 조정하는 방법이 포함된 프로세스인 전이학습 방식을 사용한다. 이 방식에서는 AlexNet 또는 GoogLeNet과 같은 기존 네트워크를 사용하여 이전에 알려지지 않은 클래스를 포함하는 새로운 데이터를 주입한다. 이 방법을 사용하면 수천 또는 수백만 장의 이미지로 모델을 미리 훈련한 덕분에 시간 소모가 줄게 되고 결과물을 빠르게 산출할 수 있다.

두번째, 머신러닝 기술도 객체 인식에 널리 사용되고 있으며, 딥러닝과는 다른 접근 방식으로 머신러닝 기술이 사용되는 일반적인 사례는 SVM(Support vector machine) 머신러닝 모델을 사용한 HOG 특징 추출과 SURF 및 MSER과 같은 특징을 사용한 BoW(Bag of Words) 모델과 경쟁 객체 탐지 속도를 실시간으로 제공하는 최초의 객체 탐지 프레임 워크로 얼굴과 상반신을 포함하여 다양한 객체를 인식하는 데 사용할 수 있는 Viola-Jones 알고리즘 등이 있다.
또한 표준 머신러닝 방식을 사용하여 객체 인식을 수행하려면 이미지(또는 비디오)를 모아 각 이미지에서 주요 특징을 선택한다. 예를 들어 특징 추출 알고리즘을 사용하면 데이터에서 클래스 간의 구분에 사용할 수 있는 가장자리 또는 코너 특징이 추출된다. 그런 다음, 이러한 특징을 머신러닝 모델에 추가하여 각 특징을 고유 카테고리로 나눈 후 새로운 객체를 분석 및 분류할 때 이 정보를 사용하며, 정확한 객체 인식 모델을 만들기 위해 다양한 머신러닝 알고리즘과 특징 추출 방법을 조합하여 사용할 수 있다.

객체 인식에 머신 러닝을 사용하면 다양한 특징과 분류기를 최적으로 조합하여 학습에 사용할 수 있다. 최소의 데이터로도 정확한 결과를 얻을 수 있다.
마지막으로 세번째는, 객체 인식을 위한 머신러닝과 딥러닝의 차이점은 무엇인가?
최적의 객체 인식 접근 방식은 응용 분야와 해결하려는 문제에 따라 다른다. 대다수의 경우, 객체의 클래스를 구분하기 위해 이미지의 어떤 특징을 사용하는 것이 가장 좋은지 알고 있을 때는 머신러닝이 효과적인 기술 일 수 있지만 머신러닝과 딥러닝 중 무엇을 선택할지 고민되는 경우에는 고성능 GPU와 대량의 레이블이 지정된 학습용 이미지를 보유하고 있는지를 중점적으로 고려해야 한다.
이러한 조건이 갖추어지지 않았다면 머신러닝 방식이 보다 나은 선택일 수 있다. 딥러닝 기술은 이미지가 많을 때 더 나은 결과를 보여주는 경향이 있으며, GPU는 모델을 학습시키기 위해 필요한 시간을 줄이는 데 도움이 되기 때문이다.