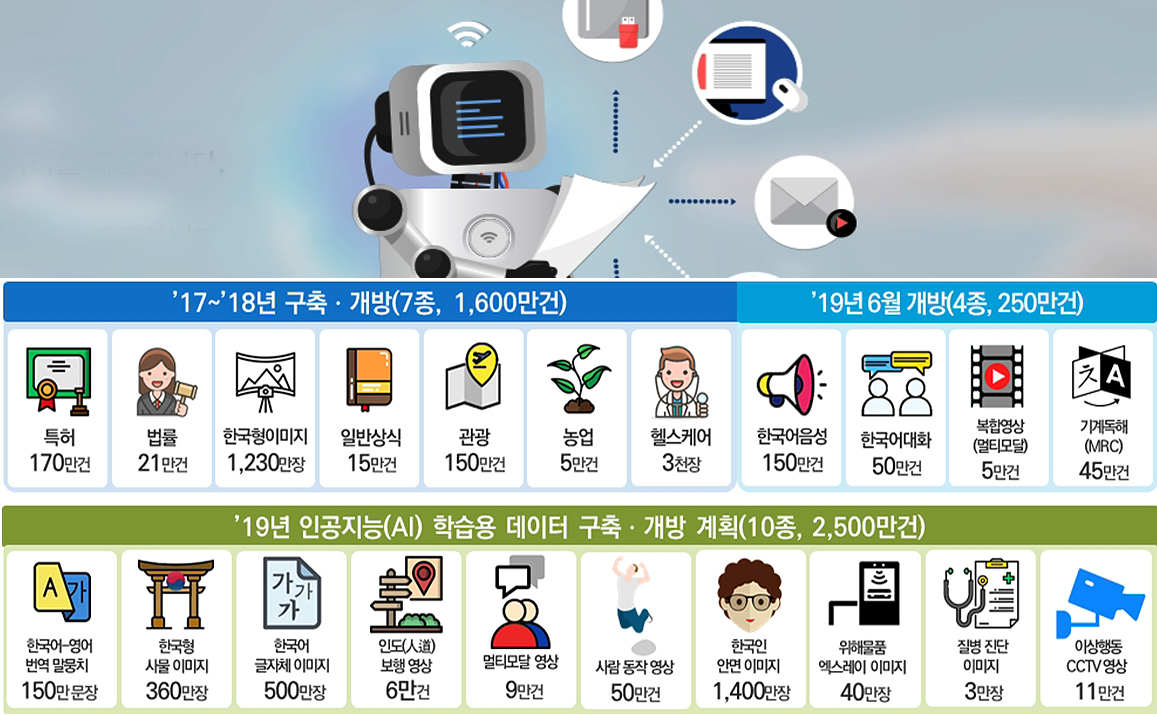
NIA, 공개되는 데이터는 '감정, 상황, 대화내용을 담고 있는 복합 영상 데이터', '자연스러운 한국어 대화 음성 데이터', '한국어 챗봇용 대화 및 시나리오 데이터', '한국어 기계독해 데이터' 등 4종이다.
한국 사람의 감정에 대한 영상 정보, 한국어의 자연스러운 발성정보를 담고 있는 인공지능(AI)용 데이터가 개방된다. 이번 데이터 개방이 인공지능기술의 활용 스펙트럼을 넓히고, 관련 AI 서비스의 상용화를 촉진하는 계기가 될 것으로 전망된다.
한국정보화진흥원(원장 문용식, 이하 NIA)은 250만개의 인공지능 학습용 데이터를 공개했다고 14일 밝혔다. 공개되는 데이터는 '감정, 상황, 대화내용을 담고 있는 복합 영상 데이터', '자연스러운 한국어 대화 음성 데이터', '한국어 챗봇용 대화 및 시나리오 데이터', '한국어 기계독해 데이터' 등 4종이다. 데이터는 NIA가 운영하는 AI허브(바로가기)에서 간단한 회원가입을 통해 누구나 내려 받아 사용할 수 있다.
“데이터의 확보가 AI 경쟁력”이지만 대다수의 중소․벤처․스타트업은 많은 비용과 시간이 소요되는 데이터 구축에 어려움을 겪고 있다. 따라서 ‘인공지능 데이터 구축‧공개 사업’은 AI 시장에 막 진입하고자 하는 신생기업들에게 특히 매력도가 높은 사업이다. NIA는 지난 `17년부터 법률, 특허, 일반상식, 한국형 이미지 4종의 데이터셋 구축을 시작해 `19년 1월에는 관광, 농업, 헬스케어 등 7종을 개방했고, 이번에 한국어 음성 등 4종을 추가 개방한 것이다.
또한 국가 R&D 과제로 음성‧언어‧영상 등 다양한 정보를 복합적으로 학습하여 사람과 상호작용하는 대화형 에이전트 기술 및 서비스를 개발하는 AI분야 연구개발(R&D) 사업인 '지능정보 플래그십 사업'' 등을 통해 만들어진 인공지능 학습용 데이터 다수를 금년 7월 AI허브에 공개할 예정이며, 금년 말에는 한-영 번역말뭉치, 한국형 사물이미지, 한글 글자체 이미지, 이상행동 영상 등 10종 2,500여만건의 데이터셋을 대량 공개할 예정이다.
한편, NIA 문용식 원장은 “인공지능 제품과 서비스가 활발히 개발되고 출시될 수 있도록 수요에 꼭 맞는 데이터셋을 대량 구축‧공개해 국내 인공지능 산업과 시장의 경쟁력을 강화하는데 역량을 집중하겠다”고 밝혔다