이 시스템은 현재, 시장 예측 생성, 고객 지원 티켓에 응답, 정확한 예상 도착 시간 계산 및 운전자 앱에서 자연어 처리(NLP) 모델을 사용하여 원 클릭 채팅 기능을 강화하고 다양한 사용 사례에 걸친 고전적인 머신러닝, 시계열 예측 및 딥러닝 모델을 지원한다.

엔드 투 엔드(end-to-end) 머신러닝 워크플로우를 커버하도록 설계된 우버(Uber)의 머신러닝 플랫폼인 미켈란젤로(Michelangelo)는 현재, 자사의 수천 개의 모델의 훈련과 서비스를 지원하고 있다.
지난 2017년 9월 5일에 공개된 우버(오픈소스 다운)의 미켈란젤로에 사용되는 주요 오픈 소스 구성 요소는 안정적이고 확장 가능한 분산 컴퓨팅을 위한 'HDFS(Hadoop Distributed File System), 대규모 데이터 처리를 위한 통합 분석 엔진 '스파크(Spark)', 스트리밍 프로세싱 엔진 '삼자(Samza)', 오픈소스 데이터베이스(DB)인 아파치 '카산드라(Cassandra)', 머신러닝 라이브러리인 MLLib , 머신러닝 알고리즘 'XGBoost(eXtreme Gradient Boosting)', 텐서프로우(TensorFlow) 등이다.
일반적으로 오픈 소스 솔루션이 사용 사례에 적합하지 않을 때 시스템을 직접 구축하지만 미켈란젤로는 가능하면 오픈 소스 옵션을 선호하고 필요에 따라 포크, 커스터마이징 등에 기여하고 있다.
이 시스템은 현재, 시장 예측 생성(marketplace forecasts), 고객 지원 티켓에 응답, 정확한 예상 도착 시간 계산(ETA estimated times of arrival) 및 운전자 앱에서 자연어 처리(NLP) 모델을 사용하여 원 클릭 채팅 기능(Connect Ahead of the Pickup with In-App Chat)을 강화하고 다양한 사용 사례에 걸친 고전적인 머신러닝, 시계열 예측 및 딥러닝 모델을 지원한다.
대부분의 미켈란젤 모델은 아파치 스파크를 위한 확장 가능한 머신러닝 라이브러리인 '아파치 스파크 MLlib(Apache Spark MLlib 다운)'를 기반으로 한다. 높은 QPS 온라인 서비스를 처리하기 위해 미켈란젤로는 원래 사내 사용자 지정 모델 직렬화 및 표현 기능이 있는 Spark MLlib 모델의 하위 집합 만 지원하여 고객이 임의로 복잡한 모델 파이프 라인을 유연하게 실험하지 못하고 미켈란젤로의 확장성 속도를 억제했었다.
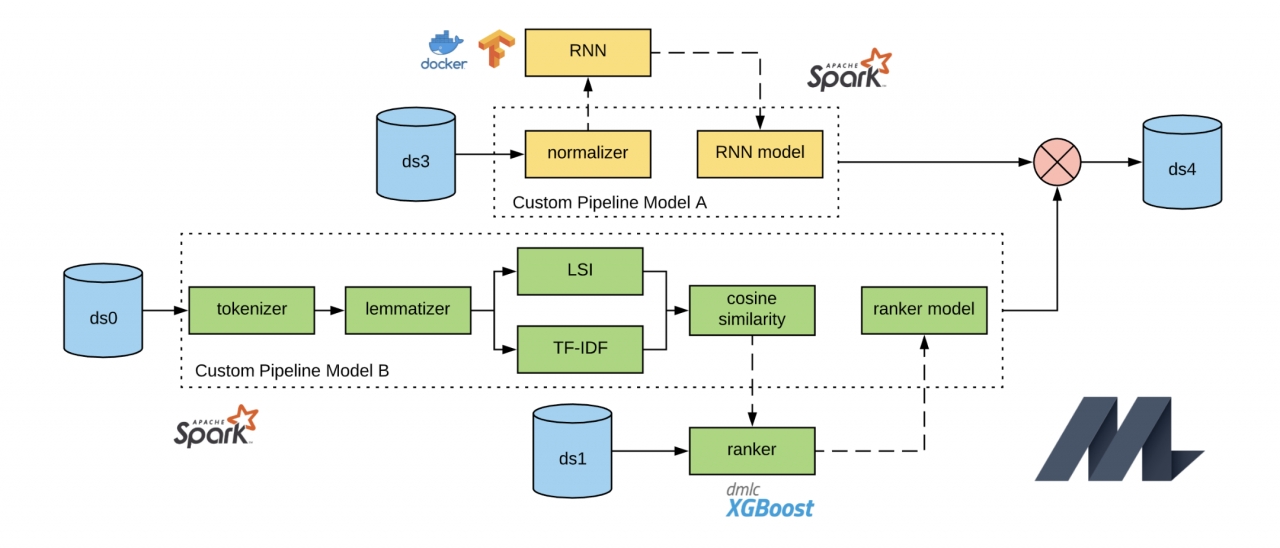
이러한 문제들을 해결하기 위해, 우버는 미켈란젤로에서 스파크 MLlib을 사용하는 것을 진화시켰는데, 특히 모델 표현, 지속성, 온라인 서비스 분야에서 그러했다.
또한 최근에는 미켈란젤로 외부에서 훈련된 모델을 제공하는 등 더 많은 사용 사례를 처리하도록 진화했다. 예를 들어, 딥러닝 모델의 엔드-투-엔드 교육을 확장 및 가속화하려면 분산 딥러닝 교육뿐만 아니라 CPU에서 스파크 파이프 라인(다운)의 분산 및 스파크 파이프 라인의 낮은 지연 시간 제공을 활용하기 위해 다양한 환경에서 수행되는 운영 단계가 필요하기 때문이다.
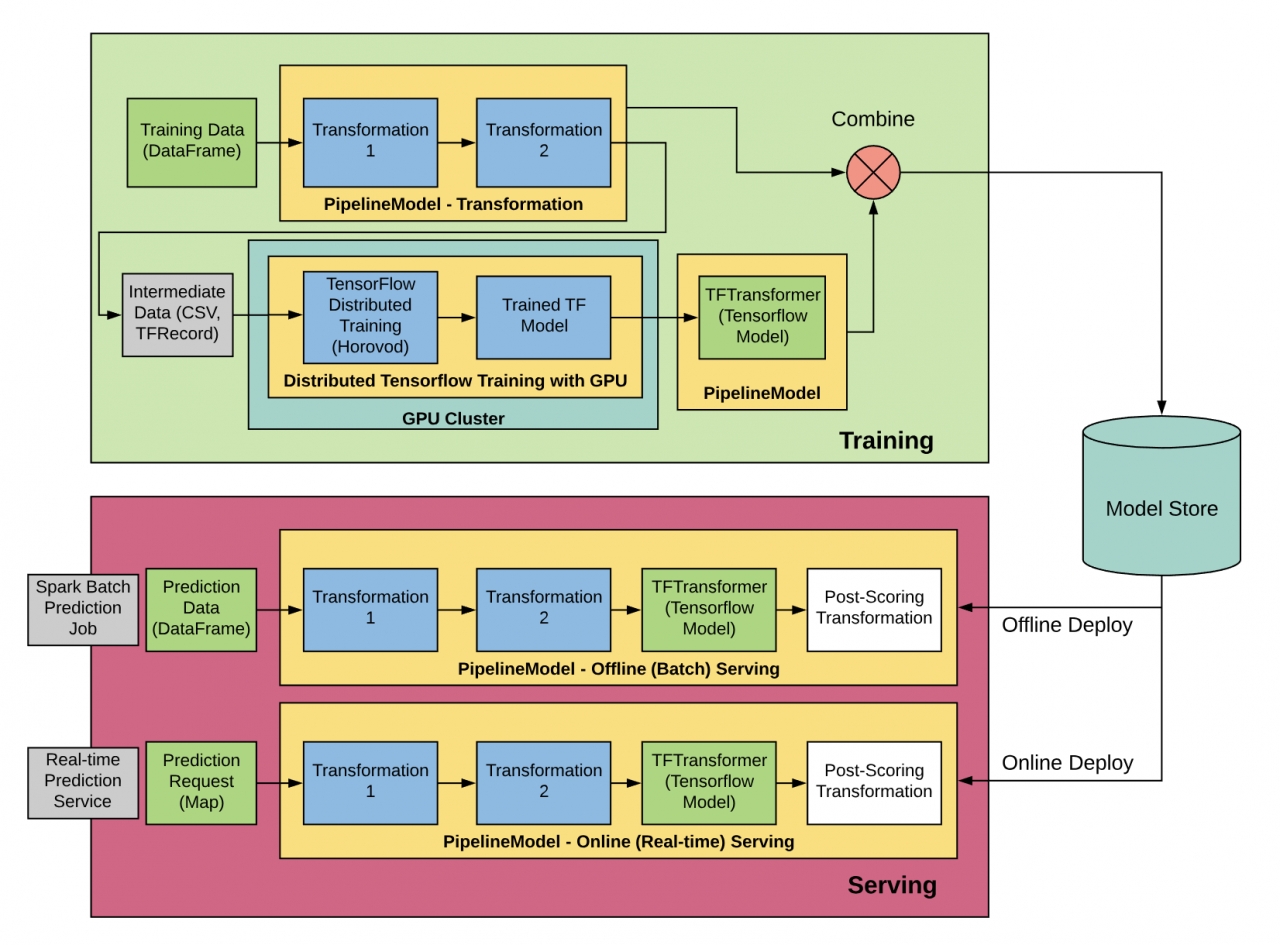
이는 텐서플로우를 위한 우버의 오픈 소스 분산 딥러닝 프레임 워크 Horovod(다운)를 사용하는 GPU 클러스터로 이러한 요구 사항을 촉진하고 교육 및 서비스 일관성을 보장하려면 기존의 짧은 대기 시간의 JVM 기반 모델 서비스 인프라를 활용하면서 요구 사항을 캡슐화하기 위한 올바른 추론을 제공 할 수 있는 일관된 아키텍처 및 모델 표현을 유지하는 것이 중요하기 때문이다.
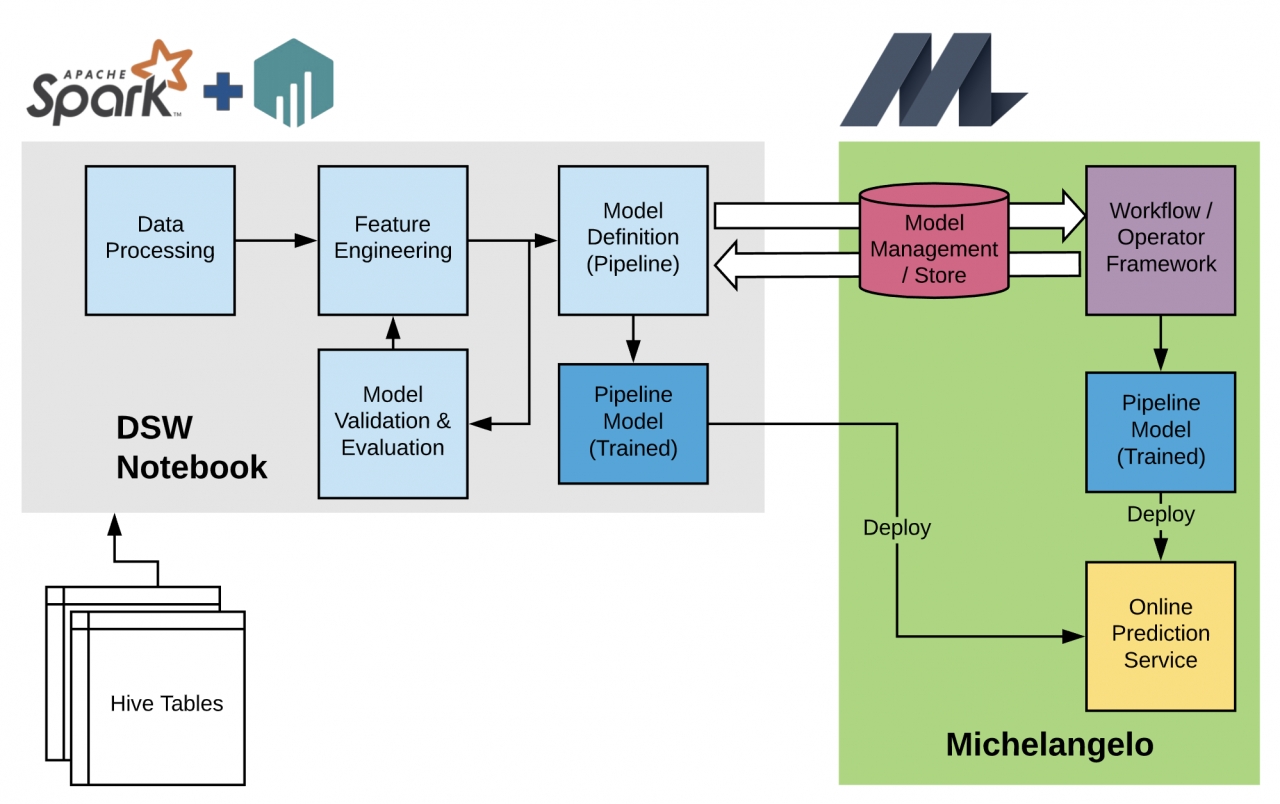
또 다른 동기는 데이터 과학자가 PySpark를 사용하여 익숙한 Jupyter Notebook 환경(Data Science Workbench ) 에서 임의로 복잡한 모델을 구축하고 실험 할 수 있도록하는 동시에 미켈란젤로 생태계를 활용하여 분산 교육, 배포 및 서비스를 안정적으로 수행 할 수 있도록하는 것입니다. 또한 앙상블 학습(Ensemble learning) 또는 다중 작업 학습(Multi-task learning) 기술에 필요한 보다 복잡한 모델 구조의 가능성을 열어 주면서 사용자가 데이터 조작 및 사용자 지정 평가를 동적으로 수행할 수 있다.
따라서 미켈란젤로의 스파크MLlib 및 스파크ML 파이프 라인 사용을 검토하여 확장성을 손상시키지 않으면서 확장성과 상호 운용성을 달성하기 위한 모델 지속성 및 온라인 서비스 메커니즘을 일반화했다.
미켈란젤로는 처음에는 교육 및 서비스를 위해 밀접하게 연결된 워크 플로우 및 Spark 작업을 관리하는 모놀리식(monolithic) 아키텍처로 시작되었다. 또 지원되는 각 모델 유형에 대해 특정 파이프 라인 모델 정의를 제공했으며, 서비스를 위해 훈련된 모델을 사내 사용자 정의 프로토콜 버퍼(Protobuf)으로 표시했다. 오프라인 배포는 스파크를 통해 처리되었으며, 효율적인 단일 행 예측을 위해 내부 버전의 스파크에 추가된 사용자 지정 API를 사용하여 온라인 배포를 처리했다.
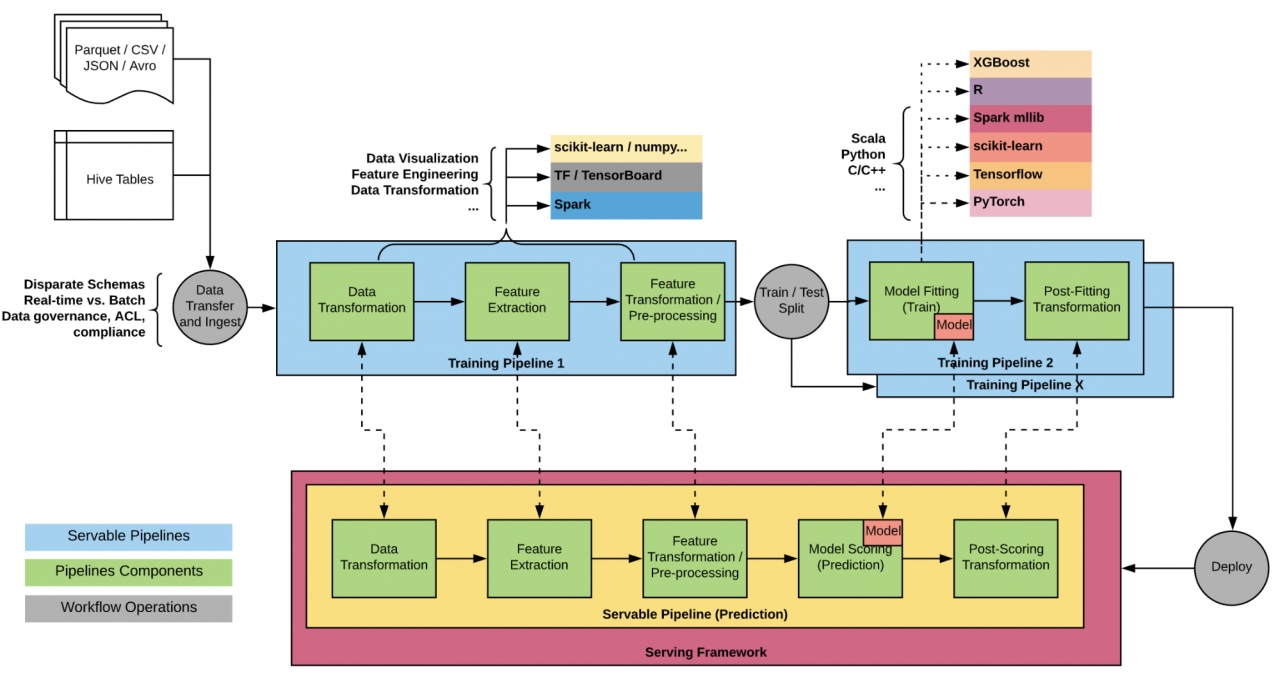
본래 아키텍처를 사용하면 GLM(Generalized Linear Model) 및 GBDT(Gradiation Boosting Decision Tree) 모델과 같은 일반적인 머신러닝 모델을 교육하고 제공 할 수 있었지만, 맞춤형 프로토 타입 표현은 새로운 스파크 트랜스포머에 대한 지원을 추가하는 것을 어려워 미켈란젤로 밖에서 훈련했다.
스파크의 사용자 정의 내부 버전은 새로운 버전의 스파크를 사용할 수 있을 때 업그레이드 할 때마다 복잡하다. 새로운 변환기에 대한 지원 속도를 개선하고 고객이 자신의 모델을 미켈란젤로로 가져올 수 있도록 하기 위해 모델 표현을 발전시키고 온라인 서빙 인터페이스를 보다 매끄럽게 추가하는 방법을 고려했다.
우버의 머신러닝 워크 플로우는 종종 복잡하며 다양한 팀, 라이브러리, 데이터 형식 및 언어에 걸쳐 있다. 모델 표현과 온라인 서비스 인터페이스를 올바르게 발전시키기 위해서는 이러한 모든 차원을 고려해야 된다는 것이다.
머신러닝 모델을 배포하려면 모델로 이어지는 변환 워크 플로를 포함하여 전체 파이프라인을 배포해야 되며 패키징해야 하는 데이터 변환, 기능 추출, 전처리 및 예측 후 변환도 종종 있다. 원시 예측은 일반적으로 레이블로 해석되거나 일부 경우 다운 스트림 서비스에 의해 소비될 수 있는 로그 공간과 같은 다른 차원 공간으로 변환되어야 한다. 또 확률적 캘리브레이션(Platt scaling)을 통해 신뢰 구간 및 캘리브레이션 된 확률과 같은 추가 데이터로 원시 예측을 보강하는 것과 스파크 MLlib 모델 고유의 파이프라인 단계를 반영하고 미켈란젤로 외부의 도구와 원활하게 교환할 수 있는 모델 표현이 필요했다.
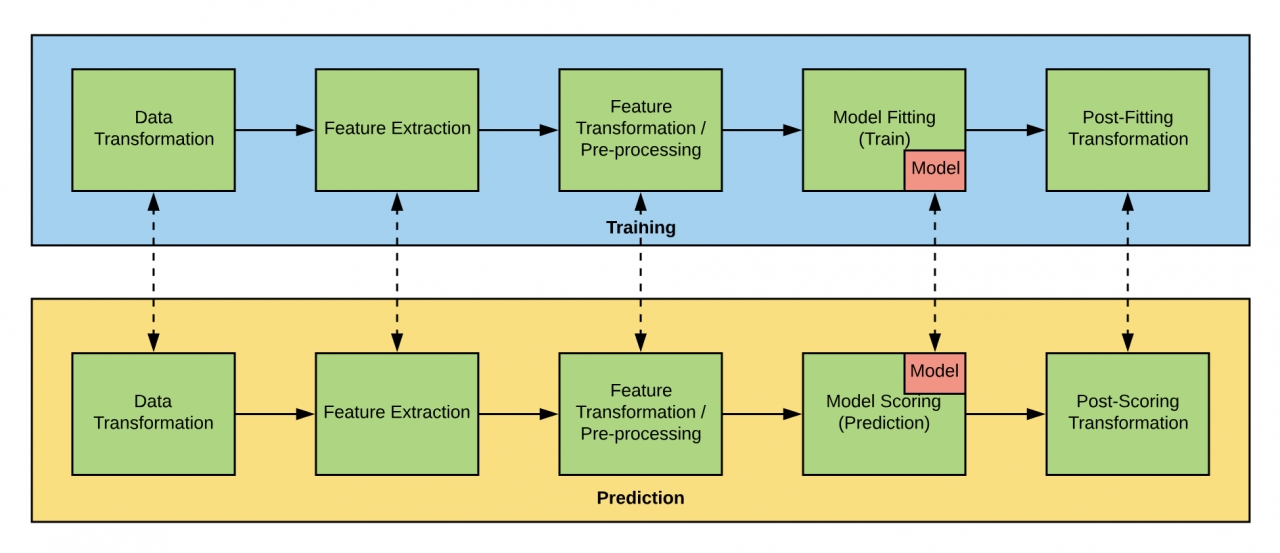
특히 우버가 고려한 한 가지 접근법은 파이프 라인 및 모델 직렬화(Bundle.ML)를 제공하고 파이프 라인을 실행하기 위한 전용 런타임으로 직렬화 해제를 제공하는 독립형 라이브러리인 MLeap을 사용 하는 것이다. MLeap(다운)은 원하는 표현력과 가벼운 온라인 서비스를 지원하지만 고유한 지속성 형식이 있어 일반 스파크 MLlib 모델을 직렬화하고 역 직렬화하는 도구 세트와의 상호 운용성을 제시한다.
MLeap은 또한 서빙 타임 모델이 트레이닝 타임에 메모리에 있던 것과 다른 형식으로 기술적으로 로드되기 때문에 트레이닝 타임 평가에서 서빙 타임 동작 편차에 약간의 위험이 있다. 이를 위해 MLeap은 스파크 MLlib에서 기본적으로 사용하는 것 외에도 각 트랜스포머와 추정기에 별도의 MLeap 저장·부하 방법을 추가해야 하므로 스파크 업데이트 속도에 마찰이 발생한다. 데이터브릭(Databricks)의 머신러닝 모델 내보내기(dbml-local )는 비슷한 접근 방식을 제공한다.
또 다른 접근법은 PMML(Predictive Model Markup Language) 또는 PFA(Portable Format for Analytics) 와 같은 표준 형식으로 훈련된 모델을 내보내는 것이다. 둘 다 원하는 표현력과 스파크와의 상호 작용, PMML과 직접 지원 및 스파크 머신러닝 모델과 파이프 라인을 PFA로 내보내기 위한 라이브러리 Aardpfark(다운)를 제공한다.
그러나 이 역시 서비스 시간 행동 편차의 위험을 가지고 있다. 일반적인 표준은 종종 특정 구현에서 다른 해석을 가질 수 있기 때문에 MLeap보다 더 높을 것으로 예상된다. 또한 표준은 스파크 변경의 특성에 따라 업데이트가 필요할 수 있으므로 스파크 업데이트 속도에서 마찰이 더 높다.
가장 간단한 방법은 모델 표현을 위해 표준 스파크 ML 파이프 라인 직렬화를 사용하는 것입니다. 스파크 ML 파이프라인은 원하는 표현력을 나타내며, 미켈란젤로 외부의 스파크 툴 세트와의 교환을 허용하며, 모델 해석 편차의 위험이 낮고 스파크 업데이트 속도에 대한 마찰이 낮음을 보여준다. 또한 사용자 정의 변환기와 추론을 작성하는 데에도 도움이 된다.
하지만 스파크 파이프 라인 직렬화를 기본적으로 사용하는 데 있어 가장 큰 어려움은 온라인 서비스 요구 사항과의 비 호환성이다. 로컬 스파크 세션을 시작하고 이를 사용하여 스파크 MLlib 학습 모델을 로드하는 이 방법은 메모리 오버 헤드와 대기 시간이 큰 단일 호스트에서 소규모 클러스터를 실행하는 것과 동일하므로 p99 대기 시간이 필요한 많은 온라인 서비스 시나리오에 적합하지 않다. 또 밀리 초 스케일. 배포를 위한 기존의 스파크 API 세트는 우버의 사용 사례에 비해 성능이 충분하지 않았지만, 우버는 요구 사항을 충족시키는 이 즉시 사용 가능한 환경에서 여러 가지 간단한 변경을 수행할 수 있음을 발견했다.
온라인 배포를 위한 가벼운 인터페이스를 제공하기 위해 우버는 저수준 스파크 예측 방법을 활용하는 단일 및 소형 목록 방법을 포함하여 온라인에서 서비스할 수 있는 온라인 트랜스포머(Online Transformer) 특성을 추가했으며, 우버는 목표 오버헤드에 도달하기 위해 모델 로딩의 성능을 조정했다.(본 기사는 10월 16일 우버 블로그에 업로드된 머신러닝 플랫폼 미켈란젤로 최신 기술 자료를 참고해 작성됐다)