논문 6편 정규 세션에 채택... 산학협력 논문으로 Oral 세션 발표도
지난 3일에서 7일까지 5일간 홍콩에서 진행된 세계 최고 권위의 자연어처리 분야 학회(EMNLP-IJCNLP 2019)에 네이버와 네이버랩스유럽이 참석해 연구성과를 공개했다.
이번 컨퍼런스에는 네이버 클로바와 네이버랩스유럽에서 연구한 각각 4개, 2개의 논문이 정규 세션에 채택되는 성과를 거뒀다.
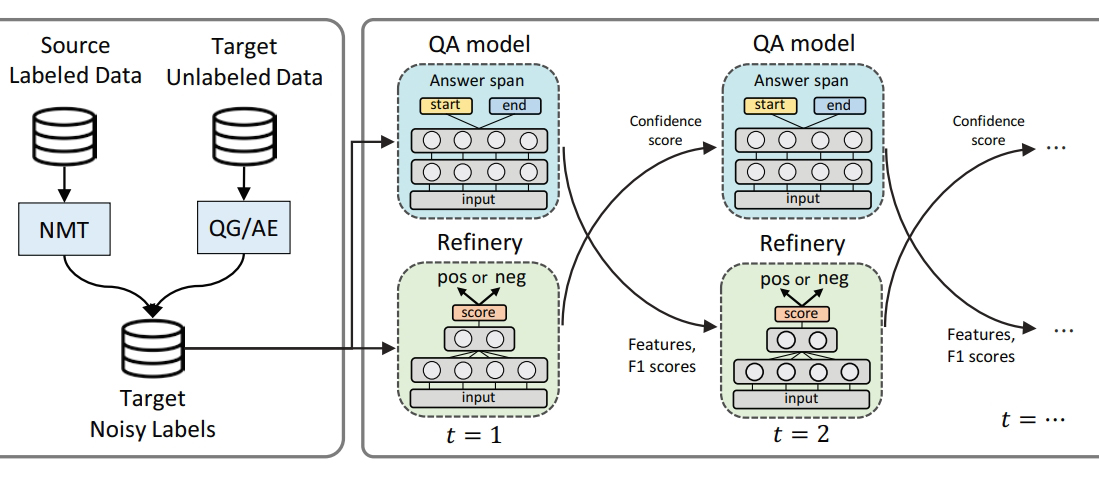
특히, 클로바 소속 박성현 연구원이 연세대학교와 산학협력의 일환으로 제출한 논문은 정규 Oral 세션에서 발표되기도 했다. 논문의 주제는 ‘다국어 읽기 이해도를 위한 제한된 데이터 학습(Learning with Limited Data for Multilingual Reading Comprehension- 논문보기)'으로 충분한 학습데이터가 존재하지 않는 언어에 대해 기계번역 및 자동 레이블링을 통해 데이터를 자동으로 구축하는 방법을 소개했다.
이외에도 DB 정보가 불명확한 상황에서도 적용가능한 자연질의-SQL 변환 방법을 제안하는 '부족한 자연어 질문에서 의사 SQL 쿼리 생성(NL2pSQL: Generating Pseudo-SQL Queries from Under-Specified Natural Language Questions / Fuxiang Chen- 논문보기), 보다 다양한 문장 생성을 위한 모델을 제시하는 '다양한 생성을 위한 혼합 콘텐츠 선택(Mixture Content Selection for Diverse Sequence Generation- 논문보기)', 사용자 질의 자동완성 품질을 향상시키는 방법을 제시하는 '쿼리 자동 완성을 위한 하위 단어 언어 모델(Subword Language Model for Query Auto-Completion- 논문보기)' 등이 발표됐다.