모든 워크로드가 높은 정밀도를 필요로하는 것은 아니기 때문에 인공지능(AI) 및 고성능 컴퓨팅(HPC) 연구원은 다른 수준의 정밀도를 혼합하고 일치시킴으로써 추구하는 것을 얻을 수 있다.

원주율(圓周率)이라고 하는 파이에 대해 생각하는 방법은 몇 가지가 있다.
기호 'π'로 나타내며, 그 값은 무리수이며 초월수이다. 무리수이기 때문에 근사값만이 상세히 계산되어 있으며, 그 값은 약 3.14159265이다. 20세기에는 컴퓨터로 파이를 소수점 아래 9번째 자리를 넘게 구할 수 있게 되었다.
3.14159의 수학적 상수를 나타내는 다른 방법은 이진법으로 1과 0의 긴 선을 나타낸다. 비이성적인 숫자인 파이는 반복하지 않고 영원히 지속되는 소수점을 가지고 있다. 따라서 파이로 계산할 때 인간과 컴퓨터 모두 숫자를 자르거나 반올림하기 전에 몇 개의 소수 자릿수를 포함해야 한다.
초등학교 수학의 경우는 3.14로 멈춘다. 고등학생의 그래프 계산기는 10개의 소수점까지 갈 수 있다. 더 높은 수준의 세부 사항을 사용하여 동일한 숫자를 표현한다.
컴퓨터 과학에서는 이를 정밀도라고 한다. 십진법이 아니라 보통 비트나 이진수로 측정된다. 복잡한 과학적 시뮬레이션을 위해 개발자들은 빅뱅을 이해하거나 수백만 개의 원자의 상호 작용을 예측하기 위해 고정밀 수학에 오래 전부터 의존해 왔다.
각 숫자를 나타내는 더 많은 비트 또는 소수점을 갖는 것은 과학자들에게 계산 과정에서 소수점의 양쪽에 변동하는 숫자의 여지가 있는 더 큰 범위의 값을 나타낼 수 있는 유연성을 제공하기도 한다. 이 범위를 사용하면 가장 큰 은하와 가장 작은 입자에 대한 정확한 계산을 수행할 수 있다.
그러나 기계가 사용하는 정밀도가 높을수록 계산 자원, 데이터 전송 및 메모리 저장이 더 많이 필요하다. 더 많은 비용이 들고 더 많은 전력을 소비한다.
모든 워크로드가 높은 정밀도를 필요로 하는 것은 아니기 때문에 인공지능(AI) 및 고성능 컴퓨팅(HPC) 연구원은 다른 수준의 정밀도를 혼합하고 일치시킴으로써 추구하는 것을 얻을 수 있다.
예를 들어, 엔비디아 Tensor Core GPU는 다중 및 혼합 정밀도(mixed precision) 기술을 지원하므로 개발자는 계산 리소스를 최적화하고 AI 응용 프로그램 및 해당 앱의 추론 기능을 가속화할 수 있다.
단일 정밀도(Single-Precision), 배 정밀도(Double-Precision) 및 반 정밀도(Half-Precision), 부동 소수점(Floating-Point) 형식의 차이점
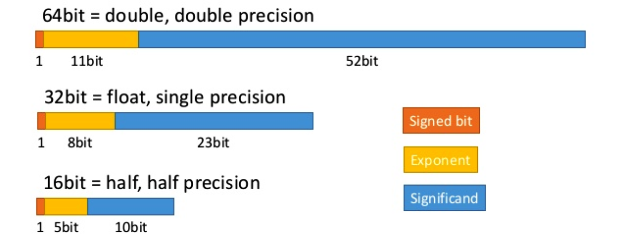
부동 소수점 산술을 위한 IEEE 표준은 컴퓨터에서 이진수로 숫자를 표현하는 일반적인 관례이다. 이중정밀 형식으로 각 숫자는 64비트를 차지한다. 단일 정밀도 형식은 32비트를 사용하는 반면, 반 정밀도는 16비트에 불과하다.
어떻게 작동하는지 보려면 파이로 돌아가 본다. 전통적인 과학적 표기법에서 파이는 3.14 x 100으로 기록된다. 그러나 컴퓨터는 이 정보를 부동 소수점, 숫자 및 해당 지수(이 경우 1.1001001 x 21)를 나타내는 일련의 1과 0으로 이진으로 저장한다.
단일 정밀도 32 비트 형식에서는 숫자가 양수인지 음수인지를 나타내는 데 1 비트가 사용된다. 8 비트는 지수를 위해 예약되어 있는데, 이진수이기 때문에 2의 거듭제곱(exponentiation)이 된다. 나머지 23 비트는 숫자를 구성하는 숫자를 나타내는 데 사용되며, 기호라고 한다.
배 정밀도는 지수의 경우 11 비트, 유효의 경우 52 비트를 예약하여 표시 할 수 있는 숫자의 범위와 크기를 크게 확장한다. 반 정밀도는 파이의 조각이 더 작으며 지수의 경우 5 비트, 유효 비트의 경우 10 비트이다.

다중 정밀도(Multi Precision) 컴퓨팅과 혼합 정밀도(Mixed Precision) 컴퓨팅의 차이점
다중 정밀도 컴퓨팅은 필요에 따라 배 정밀도를 사용하고 응용 프로그램의 다른 부분에 대해 반정밀도 또는 단일 정밀도 산술을 사용하여 다양한 정밀도로 계산할 수 있는 프로세서를 사용하는 것을 의미한다.
대단위 정밀도라고도 하는 혼합 정밀도 컴퓨팅은 대신 단일 작업 내에서 다른 정밀도 수준을 사용하여 정확도를 유지하면서 계산 효율성을 달성한다.
혼합 정밀도에서 계산은 빠른 행렬 연산을 위한 반 정밀도 값으로 시작한다. 그러나 숫자가 계산 될 때 기계는 결과를 더 높은 정밀도로 저장한다. 예를 들어, 두 개의 16 비트 행렬을 곱하면 크기는 32 비트이다.
이 방법을 사용하면 응용 프로그램에서 계산이 끝날 때까지 누적 된 답변을 배 정밀도 산술로 전체를 실행하는 것과 정확하게 비교할 수 있다.
이 기술은 기존의 배 정밀도 애플리케이션을 최대 25 배까지 가속화하는 동시에 애플리케이션 실행에 필요한 메모리, 런타임 및 전력 소비를 줄인다. AI 및 시뮬레이션 HPC 워크로드에 사용할 수 있는 것이다.
현대식 슈퍼 컴퓨팅 애플리케이션에서 혼합 정밀도 연산의 인기가 높아짐에 따라 HPC Luminary Jack Dongarra는 혼합 정밀도 계산에서 슈퍼 컴퓨터의 성능을 평가하기 위해 새로운 벤치 마크인 HPL-ML을 설명했다.

엔비디아가 세계에서 가장 빠른 美 슈퍼 컴퓨터 '서밋(Summit)'에서 테스트 실행으로 HPL-ML 계산을 실행했을 때, 시스템은 전례없는 최고 445 페타 플롭의 성능 수준을 달성했으며, 이는 슈퍼 컴퓨터 TOP500 순위에서 공식 성능보다 거의 3 배 더 빠른 것이다.
혼합 정밀도 컴퓨팅을 시작하는 방법
엔비디아 볼타(Volta) 및 튜링(Turing) GPU는 텐서코어 (Tensor Core)를 특징으로 하며, 다중 및 혼합 정밀도 컴퓨팅을 단순화하고 가속화한다. 또한 몇 줄의 코드만으로 개발자가 텐서플로우(TensorFlow), 파이토치(PyTorch), MXNet 등 딥러닝 프레임 워크에서 자동 혼합 정밀도 기능을 활성화 할 수 있다. 이 도구는 AI 학습 속도를 최대 3 배까지 향상시킨다.
엔비디아 GPU 가속 소프트웨어의 NGC(NVIDIA GPU Cloud)에는 HPC 용 혼합 정밀도 응용 프로그램을 쉽게 배포 할 수 있는 반복적 정련 솔버 및 cuTensor 라이브러리도 포함되어 있다. 자세한 내용은 혼합 정밀도 훈련에 대한 개발자 리소스(Training with Mixed Precision-다운)를 확인하면 된다.
혼합 정밀도는 어떤 곳에 사용되나?
혼합 정밀도 기능을 사용하여 과학 시뮬레이션, AI 및 자연어 처리 워크로드를 강화한다. 그 대표적인 사례를 몇 가지 들어본다.
먼저 도쿄 대학, 오크리지 국립연구소 및 스위스 국립슈퍼컴퓨팅센터(National National Supercomputing Center)의 연구원들은 지진 시뮬레이션을 위해 AI와 혼합 정밀 기법을 사용했다.
과학자들은 도쿄시의 3D 시뮬레이션을 사용하여 지진파가 단단한 토양, 부드러운 토양, 지상 건물, 지하 쇼핑몰 및 지하철 시스템에 어떤 영향을 미치는지 모델링했다. 그들은 새로운 모델로 25 배 빠른 속도를 달성했다. 이 모델은 Summit 슈퍼 컴퓨터에서 실행되었으며 배정밀도, 단정밀도 및 반 정밀도 계산의 조합을 사용했다.
의료 연구 및 건강 관리에서는 샌프란시스코에 본사를 둔 파톰(Fathom)은 엔비디아 V100 Tensor Core GPU에서 혼합 정밀도 컴퓨팅을 사용하여 의료 코딩을 자동화하는 딥러닝 알고리즘 학습 속도를 높여 미국에서 가장 큰 의료 코딩 작업과 의사의 유형 메모를 영·숫자 코드로 변환시켰다.
美 오크리지국립연구소(Oak Ridge National Laboratory)의 연구원들은 마약성 진통제 오피오이드(Opioid) 중독에 대한 혁신적인 연구 결과로 고성능 컴퓨팅 세계에서 오스카 상에 해당하는 '고든 벨(Gordon Bell)' 상을 수상했으며, 혼합 정밀 기술을 활용하여 최대 2.31 명의 엑사 옵스(exaops) 처리량을 달성했다. 이 연구는 개체군 내 유전자 변이를 분석하여 복잡한 특성에 기여하는 유전자 패턴을 식별한다.
결론적으로 혼합 정밀도 컴퓨팅은 FP64가 필요하지 않은 응용 프로그램의 일부에서 낮은 정밀도 산술을 사용하여 필요한 리소스를 줄일 수 있다. 그러나 Tensor Cores GPUs와의 혼합 정밀도 컴퓨팅은 FP64 계산을 FP16 계산으로 대체하는 것 이상의 이점을 제공한다.
FP16과 FP32를 사용하는 텐서 코어로 가속된 FP64 솔루션을 제공하고 이를 통해 연구원 또는 개발자가 이중 정밀도에 비해 정확도가 비슷한 수준을 달성할 수 있으며 필요한 메모리, 애플리케이션 런타임 및 시스템 전력 소비를 획기적으로 줄일 수 있는 것이다.
연구자들이 전통적인 FP64 기반 과학 컴퓨팅 애플리케이션을 최대 25배까지 가속화하기 위해 GPU 텐서 코레스와 혼합 정밀 컴퓨팅을 활용하는 사례가 점점 더 많아지고 있다.