플랫폼 'Wav2letter@anywhere'는 온라인 추론을 위해 훈련된 심층신경망(DNN) 모듈을 구성해야 하는 연구원, 생산 엔지니어, 개발자, 학생 등을 대상으로 하는 다중 스레드 및 다중 플랫폼 라이브러리이다.

페이스북의 AI 리서치(FAIR)가 지난 13일(현지시간) 온라인 음성 인식을 위한 추론 프레임 워크 'wav2letter@anywhere' 를 오픈 소스로 공개했다.
이 릴리스는 FAIR의 이전 릴리스 인 wav2letter 및 wav2letter ++를 기반으로 한다.
Wav2letter@anywhere는 온라인 추론을 위해 훈련된 심층신경망(DNN) 모듈을 구성해야 하는 연구원, 생산 엔지니어, 개발자, 학생 등을 대상으로 하는 다중 스레드 및 다중 플랫폼 라이브러리이다.
'온라인 음성 인식'은 입력 오디오 스트림에서 음성을 실시간으로 전사하는 프로세스이다. FAIR 연구원 비넬 프라탑(Vineel Pratap)과 로난 콜로베르(Ronan Collobert)는 일반적인 ASR(Automatic Speech Recognition) 시스템에서 다루지 않은 '실시간'측면이라고 블로그 포스트를 통해 설명했다
그는 "라이브 비디오 캡션 또는 장치 내 녹음 방송과 같은 응용 프로그램의 경우 오디오와 해당 녹음 방송 간의 대기 시간을 줄이는 것이 중요하다"며, "대부분의 기존 온라인 음성 인식 솔루션은 반복적인 신경망(RNN)만 지원하지만 'wav2letter@anywhere'의 경우 전체 컨볼루션 어쿠스틱 모델을 대신 사용하므로 특정 추론 모델의 처리량이 3 배 향상되고 전세계 최대 음성인식 데이터베이스 '리브리스피(Librispeech)'의 최첨단 성능이 향상됩니다"라고 전했다.
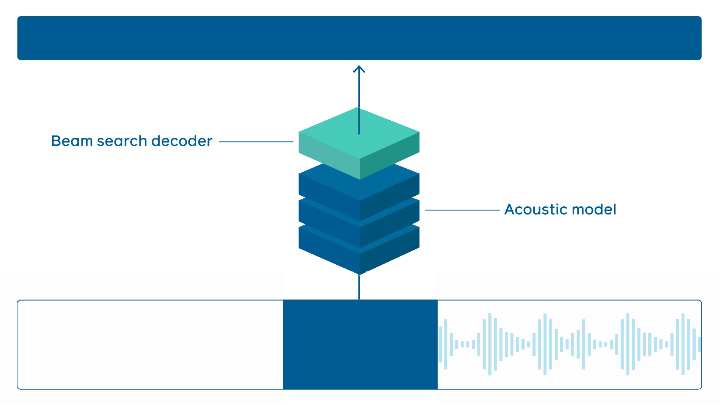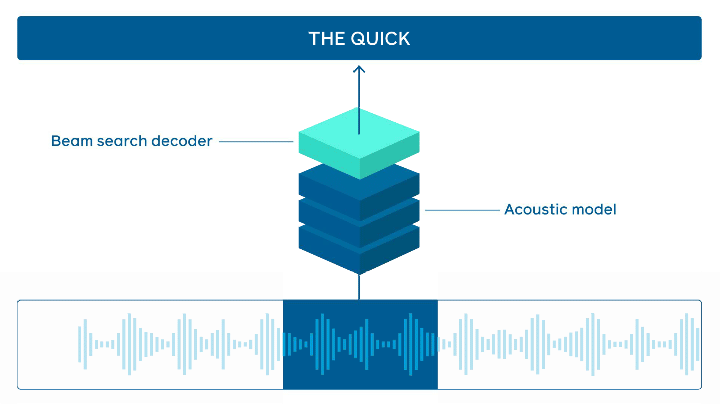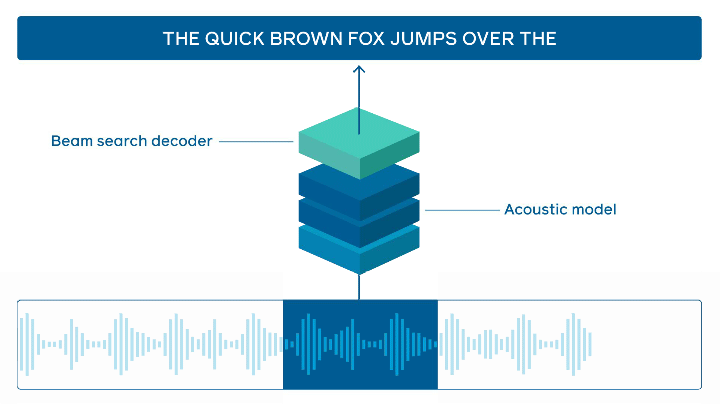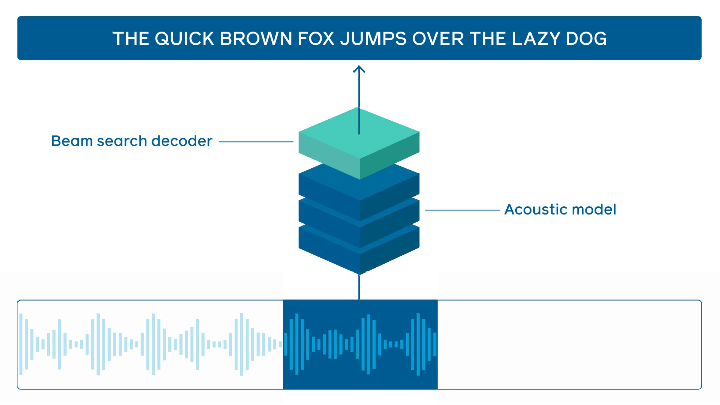
특히 이 프레임 워크는 다양한 유형의 음성 인식 모델을 처리할 수있는 효율적이지만 모듈식 스트리밍 API 추론을 제공한다. 프로덕션 규모로 작업을 수행할 때 높은 처리량에 필요한 동시 오디오 스트림을 지원하며, API는 다른 플랫폼(개인용 컴퓨터, iOS, Android 등)에서 쉽게 사용할 수있을 정도로 유연하다.
C ++로 작성된 wav2letter@anywhere는 wav2letter ++ 저장소의 일부로 프레임 워크가 더 빠른 순환신경망(RNN, Recurrent Neural Network) 및 CNN(Convolutional Neural Network)을 포함한 다양한 모델을 지원할 수있는 모듈식 스트리밍 API가 제공된다. 연구원들은 어디에나 내장 될 수있는 독립형 저장소라고 말했다. 또 파이토치/FBGEMM(다운)과 같은 효율적인 백엔드 및 iOS 및 Android 용 특정 루틴을 사용한다.
한편, 이 플랫폼은 처음부터 스트리밍을 염두에 두고 개발되었으며, 일반적인 추론 파이프 라인에 의존하는 다른 대안과 달리 효율적인 메모리 할당 설계를 구현할 수 있으며 더 자세한 내용은 지난 10일 발표된 관련 논문(다운)을 참고하면 된다.
참고: 온라인 음성 인식을 위한 추론 프레임 워크 'wav2letter@anywhere' (다운)