제한된 데이터 학습만으로 정형화되지 않은 장문의 음성 인식… AI가 자동으로 자막도 생성
네이버가 세계적인 수준의 자체 음성 기술 연구 성과를 바탕으로, 한 단계 진화한 음성인식 엔진 ‘NEST’(Neural End-to-end Speech Transcriber)를 13일 공개했다.
‘NEST’는 제한된 데이터 학습만으로도, 복잡하고 다양한 장문의 음성 표현을 정확하게 인식하고, 텍스트로 변환할 수 있는 기술이다. 대량의 정제된 데이터를 사전에 학습하지 않고도, 예상치 못한 표현에 대해 정확한 음성인식이 가능한 것이 장점이다.
음향 정보와 언어 정보를 별도로 학습하는 기존의 모델링 방식을 통합 모델링 방식(end-to-end)으로 개선해, 학습에 필요한 데이터의 양과 시간은 기존의 1/10 수준으로 단축시키면서도, 인식의 정확도는 오히려 높였다.
네이버의 새로운 음성인식 기술은 AI가 전화로 코로나19의 능동감시자를 확인하는 ‘클로바 케어콜’ 서비스에 적용되어 있으며, 지난 1월에는 네이버 동영상 뉴스의 자동 자막 서비스에도 도입된 바 있다. 네이버는 'NEST' 기술을 적용한 자동 자막을 다양한 동영상 및 오디오 서비스로 확대하고, 동영상 검색 및 에디터에도 해당 기술을 활용할 예정이다.
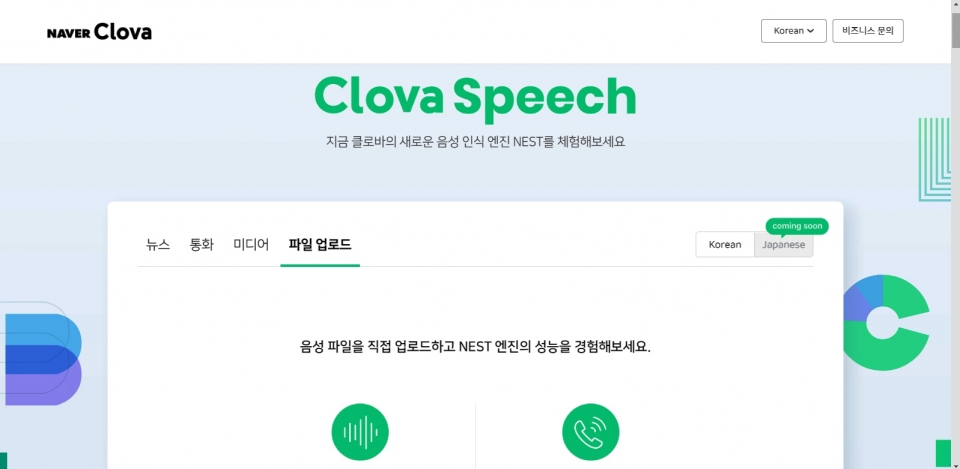
일반 사용자들은 클로바 스피치 홈페이지에서 ‘NEST’ 기술을 무료로 체험해볼 수 있으며, 기업 및 단체도 제휴 제안을 통해 사용이 가능하다. 하반기 일본어 출시를 시작으로, 영어, 중국어 등으로 제공 언어도 확대한다는 계획이다.
한편, 네이버 한익상 리더는 “’NEST’는 동영상 및 오디오 콘텐츠의 자막 제작이나 아카이빙, 고객센터의 통화 데이터 관리 등 다양한 분야에서 활용 가치가 높을 것으로 기대된다”며, “앞으로도 AI 핵심 기술 연구에 더욱 집중하며, 음성인식의 품질과 효율을 더욱 고도화해 나가겠다”고 밝혔다.