
먼저, 연합학습(federated learning)은 개발자와 조직이 여러 위치에 분산된 훈련 데이터를 사용하여 심층신경망(DNN Deep Neural Networks)을 훈련시킬 수 있는 새로운 학습 패러다임이다. 이를 통해 의료전문가들은 임상 데이터를 직접 공유할 필요없이 공유 모델에 대해 협업할 수 있다.
글로벌 IT 기업들도 연구와 개발에 여념이 없다. 먼저 구글이 지난해 8월에 발표한 연합학습은 일반적으로 모든 데이터를 서버로 모아, AI를 학습하는 방식과 달리, 사용자가 직접 사용하는 스마트폰에서 데이터를 처리하고 모델을 강화하고 이 모델을 한 곳에 모아 더 정교한 모델을 만들어 다시 배포하는 방식이다.
이는 상대적으로 적은 데이터로 최적화한 AI 모델을 개발할 수 있다. 방대한 데이터를 저장하는 스토리지나 이런 데이터를 처리하기 위한 고성능 프로세서를 사용자 개인 디바이스로 분산했으며, 필요 사항만을 공유해 최적화한 모델을 다시 배포하는 만큼 트래픽에 대한 부담도 적다. 또 개인정보 침해 가능성 역시 상대적으로 적어 제도적 장벽 역시 쉽게 넘을 수 있다.
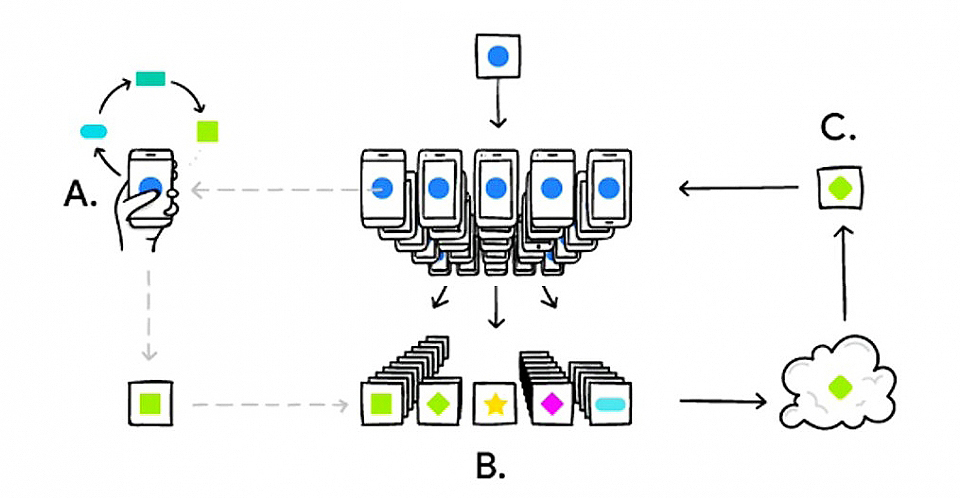
또한 페이스북이 안드로이드와 iOS 환경에서 원활하게 머신러닝을 실행하고 배포할 수 있도록 하는 새로운 프레임워크 ‘파이토치 모바일’(PyTorch Mobile)을 지난 11일(현지시각) 공개했다. 이 새롭게 공개된 프레임워크는 연합학습(Federated Learning)을 지원해 개인정보 유출 우려를 줄이고 보다 개인에 맞춰 AI를 학습시킬 수 있는 것이 특징이다.
즉, 연합학습은 AI 알고리즘이 서로 다른 사이트에 위치한 방대한 범위의 데이터에서 경험을 얻을 수 있느 것으로 이 접근 방식을 통해 여러 조직에서 모델 개발에 대해 공동 작업할 수 있는 것이다.
특히 이 연합학습이 더 주목받는 곳은 의료기관이다.
일반적으로 건강관리 AI 알고리즘의 경우 경험은 크고 다양한 고품질 데이터 세트의 형태로 제공된다. 그러나 이러한 데이터 세트는 수집에 매우 어렵다고 한다. 예를 들어, 의료기관은 환자 인구 통계, 사용된 도구 또는 임상 전문화에 의해 편향될 수 있는 자체 데이터 소스에 의존해야 했으며, 다른 기관의 데이터를 모아서 필요한 모든 정보를 수집해야만 한다.(이상 본지 2019.10.18. 새로운 AI학습 패러다임...'연합학습'은 의료에서 어떤 영향을 미치나?- 인용)
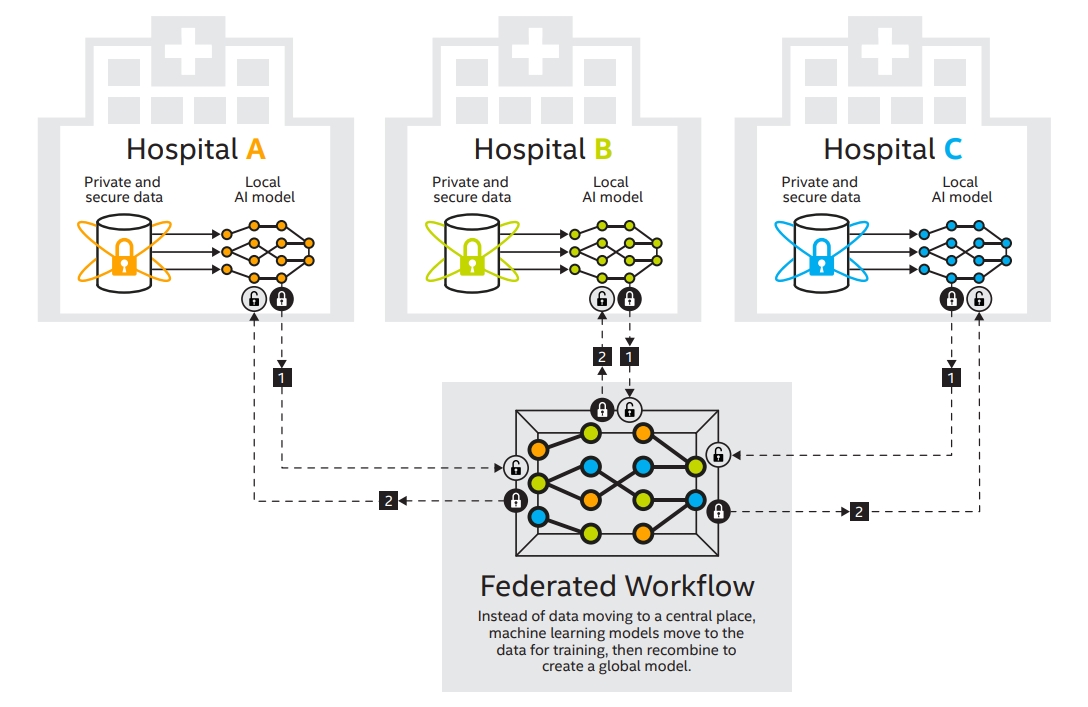
인텔 랩(Intel Labs)이 美 펜실베니아 대학교 페럴만 의과대학(펜 메디슨, Perelman School of Medicine at the University of Pennsylvania, Penn Medicine)과 협력해 펜 메디슨이 이끄는 29개 국제 보건 의료 및 연구 기관 연합이 AI 모델을 훈련시킬 수 있도록 공동 개발 중이라고 11일(현지시간) 밝혔다.
이 AI 모델은 프라이버시를 지키는 기술인 연합학습을 활용해 뇌종양을 식별한다.
펜 메디슨의 연구는 3년 동안 펜실베니아 대학교 '바이오 이미지 컴퓨팅 및 분석 센터(Center for Biomedical Image Computing and Analytics, CBICA)'의 스피리돈 바카스 박사(Dr. Spyridon Bakas)에게 120만 달러의 연구 보조금을 수여하는 형태로 지원된다. 이 지원금은 국립 보건원(National Institutes of Health (NIH)) 산하 국립 암 연구소(National Cancer Institute (NCI))의 '암 연구를 위한 정보 기술학(Informatics Technology for Cancer Research, ITCR)' 프로그램의 일부다.
제이슨 마틴(Jason Martin) 인텔 랩 수석 엔지니어는 “AI는 뇌종양 조기 발견에 큰 가능성을 보여주고 있지만, 잠재력을 최대한 발휘하기 위해서는 어떤 단일 의료기관보다 더 많은 데이터가 필요”하다며, “인텔의 소프트웨어와 하드웨어를 활용하고 인텔 랩의 지원을 받아, 인텔은 펜실베니아 대학, 29 개의 공동 의료 센터와 협력해 민감한 환자 데이터를 보호하면서 뇌종양 식별을 앞당기고 있다”고 밝혔다.
펜 메디슨과 미국, 캐나다, 영국, 독일, 네덜란드, 스위스, 인도 등 29 개의 의료 및 연구 기관들은 환자 데이터를 공유하지 않고도 딥 러닝 프로젝트에 협력할 수 있는 분산형 머신 러닝 접근법인 연합 학습을 사용할 예정이다.
펜 메디슨과 인텔 랩은 의학 영상 영역에서 연합 학습에 대한 논문을 최초로 발표했으며, 특히 연합 학습법이 기존의 프라이버시를 지키지 않는 방식으로 훈련된 모델 정확도의 99% 이상으로 모델을 훈련시킬 수 있다는 것을 입증했다. 연구 논문은 스페인 그라나다에서 열린 2018년 의료 영상 기술 학회(Medical Image Computing and Computer Assisted Intervention, MICCAI)에서 발표됐다.
새로운 연구는 모델과 데이터 모두에 추가적인 프라이버시 보호를 제공하는 방식으로 연합 학습을 구현하기 위해 인텔 소프트웨어와 하드웨어를 활용할 것이다.
펜실베니아 대학교 생물학적 이미지 컴퓨팅 및 분석 센터의 스피리돈 바카스 박사는 “머신 러닝 훈련에 필요한 풍부하고 다양한 데이터는 하나의 기관이 처리하는 데는 어려움이 있다. 우리는 29 개의 세계적인 의료 및 연구 기관 연합체를 조직화하고 있으며, 이를 통해 연합 학습을 포함한 프라이버시를 보존하는 머신러닝 기술을 사용해 의료용 최첨단 AI 모델을 훈련시키고 있다”고 밝혔다.
그는 “올해, 연합체는 크게 확장된 국제 뇌종양 분할 시험(International Brain Tumor Segmentation (BraTS) challenge) 데이터셋에서 확장된 버전 상에서 뇌종양을 식별하는 알고리즘을 개발할 예정이다. 이 연합체는 의료 연구원들이 방대한 양의 의료 데이터에 접속하는 동시에 해당 데이터의 보안을 유지할 수 있도록 할 것”이라고 덧붙였다.
한편, 미국 뇌종양 협회(American Brain Tumor Association (ABTA))에 따르면, 올해 뇌종양 진단을 받는 사람은 8만 명에 육박할 것이며, 이중 4,600 명 이상이 어린아이일 것이라고 예상했다. 뇌종양의 조기 발견과 더 나은 예후에 도움이 될 수 있도록 뇌종양을 감지하는 모델을 훈련하고, 구축하기 위해서 연구자들은 많은 양의 관련 의료 데이터를 활용해야 할 필요가 있다.
그러나 데이터는 비공개이며, 보호되어야 하기 때문에 인텔 기술 기반 연합 학습이 필요하다. 이 접근법을 활용함으로써 모든 협력 기관의 연구자들은 민감한 의료 데이터를 보호하면서 뇌종양을 감지하는 알고리즘을 구축하고 훈련하는데 협력할 수 있게 된다.
2020년에 펜 메디슨과 29개 국제 의료 및 연구 기관은 인텔의 연합 학습 하드웨어와 소프트웨어를 사용해 현재까지 가장 많은 양의 뇌종양 데이터 세트에서 훈련된 새로운 최첨단 AI 모델을 만들 것이다.
이 모든 것은 개별 협력자를 필요로 하지 않으며 민감한 환자 데이터 또한 사용하지 않는다.
이 연합체의 첫 번째 단계를 시작하는데 참여가 예정된 협력 기관은 펜실베니아 대학 병원(Hospital of the University of Pennsylvania), 세인트 루이스에 위치한 워싱턴 대학교(Washington University), 피츠버그 대학 메디컬 센터(University of Pittsburgh Medical Center), 밴더발트 대학교(Vanderbilt University), 퀸스대학교(Queen’s University), 뮌헨공과대(Technical University of Munich), 베른대학교(University of Bern), 킹스칼리지런던(King’s College London), 타타메모리얼 병원(Tata Memorial Hospital) 등이다.
결론적으로 연합학습을 현재의 데이터 중심 시스템과 비교할 때 제안된 접근 방식은 기관 데이터를 공유하지 않고도 비슷한 세그멘테이션(segmentation) 성능을 달성할 수 있었으며, 희소 벡터 기술(the sparse vector technique)을 사용하는 연합학습 시스템은 상당히 적은 비용으로 엄격한 개인 정보를 보호할 수 있다.
또한 개인 데이터를 통해 로컬로 학습된 의료기관 간에 효과적으로 데이터를 집계할 수 있어 심층 모델의 정확성, 견고성 및 일반화 능력을 더욱 향상시킬 수 있는 것이다. 이번 연구는 안전한 연합학습 구축을 위한 중요한 단계로 보이며, 이는 광대한 데이터 중심의 정밀의학을 대규모로 가능하게 할 것으로 예상된다.