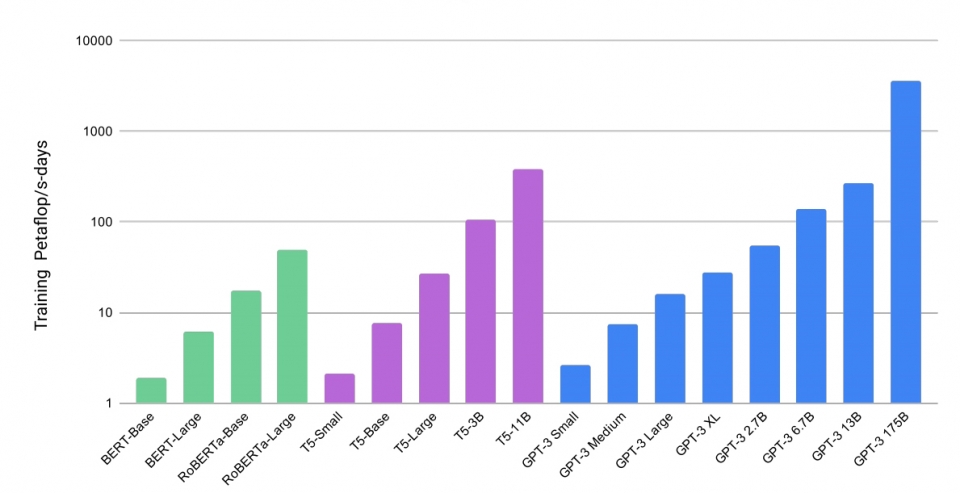
이 모델은 4990억개 데이터셋 중에서 가중치 샘플링해서 3000억(300B)개로 구성된 데이터셋으로 사전 학습을 받았으며, 1750억개(175Billion) 매개 변수로 딥러닝의 한계까지 추진돼

최근 인공지능(AI) 자연어 처리(NLP)에서 가장 화제가 되고 있는 플랫폼으로는 구글의 양방향 언어모델 버트(Bert), OpenAI의 단방향 언어모델 GPT-2, 기계신경망 번역(Transformer) 모델 등을 꼽을 수 있다.
이 가운데 지난 1일(현지시간) OpenAI가 새로운 강력한 언어 모델 'GPT-3(Generative Pre-Training 3)'를 아카이브(arXiv)를 통해 공개했다. 이는 지난해 초에 공개한 소설 쓰는 인공지능 'GPT-2' 보다 훨씬 더 크고 혁신적인 버전으로 진화된 모델이다.
이 모델은 4990억개 데이터셋 중에서 가중치 샘플링해서 3000억(300B)개로 구성된 데이터셋으로 사전 학습을 받았으며, 1750억개(175Billion) 매개 변수로 딥러닝의 한계까지 추진돼 미세 조정없이 여러 자연어 처리 벤치마크에서 최첨단 성능을 달성했다. 발표된 내용이라면 단 몇 개 키워드만 넣으면 작문을 작성해주는 혁신적인 AI 언어생성 모델이자 알고리즘인 것이다.
OpenAI 연구팀(31명의 공동 저자)은 무려 74페이지의 연구 논문(Language Models are Few-Shot Learners)을 통해 이 모델에 대한 여러 기능과 실험에 대해 설명했다. 연구원의 목표는 미세 조정이 거의 없거나 전혀 없는 다양한 작업에서 잘 수행되는 NLP 시스템을 구현하는 것을 목표로 하고 있으며, 모델은 자체 감독학습(self-supervised learning)을 사용하여 공통 크롤링 데이터 세트(보기) 및 영어 위키 백과를 포함한 다양한 데이터 세트를 적용했다.
특히, 뉴스 기사 생성 작업에서 모델을 평가하기 위해 연구팀은 크라우드 소싱 플랫폼인 아마존 메커니컬 터크(Amazon Mechanical Turk)를 사용했다. GPT-3는 인간 평가자가 인간이 작성한 기사와 구별하기 어려운 뉴스 기사 샘플을 생성할 수 있다고 한다.

모델은 트랜스포머(Transformer), 어텐션(Attention) 등의 표준개념과 일반적인 커먼 크롤(Common Crawl), 위키피디아(Wikipedia), 도서 및 일부 추가 데이터 소스를 사용하여 빌드 된다. 다양한 작업에 GPT-3 모델을 사용하기 위해 그라디언트(Gradient) / 매개 변수 업데이트(미세 조정)를 수행 할 필요가 없다. 자연어를 사용하여 모델과 상호 작용하거나 수행하려는 작업의 예를 제공하면 모델이 수행할 수 있다.
작업 별 모델 아키텍처가 필요하지 않을 뿐만 아니라 대규모 사용자 지정 작업 별 데이터 집합이 필요하지 않다는 개념은 최첨단 NLP의 접근성을 높이는 방향으로 나아가는 큰 단계로 GPT-3은 단어 예측, 상식 추론과 같은 많은 NLP 작업에서 뛰어난 성능을 제공을 제공한다.
한편, OpenAI는 훈련된 모델 또는 전체 코드는 공개하지 않았지만, 모델에 의해 생성된 텍스트 샘플 모음뿐만 아니라 일부 테스트 데이터 세트를 포함하는 내용은 깃허브(다운)에 공개 했으며, 관련 연구 논문(Language Models are Few-Shot Learners)은 지난 1일 아카이브(다운)에 공개됐다. 이제, 기자도 곧 AI로 교체될 날이 머지않은 것 같다. 인공지능 자언어 처리가 어떻게 진화할 것인지 또 그 영향은 우리 모두에게 어떻게 파급될지 지켜보는 것이 흥미로울 것으로 보인다.
관련기사
- GPT-3... 휼륭하지만 '다섯 가지' 한계를 짚어본다
- [영상] 초보자도 쉽게 GPT-3를 사용해 혼자서 GPT-3 모델을 구현한다
- OpenAI, GPT-3 언어 모델... 마이크로소프트, 독점 라이선스 확보
- GPT-3, 왜 요금제를 선택했으며... 마이크로소프트에 독점 라이선스를 부여했나?
- 테슬라 일론 머스크, 오픈AI... 마이크로소프트에 GPT-3 독점 라이선스 부여한 것! 공개 비판
- GPT-3는 과연 얼마나 똑똑한 것일까?
- GPT-3, 인류 역사상 가장 뛰어난 '언어 인공지능'이다
- [AI 리뷰] 오픈AI, 글 쓰는 GPT-3에서 진화... 텍스트 읽고 그림 그리는 AI 모델 'DALL·E' 및 'CLIP' 공개
- [이슈] GPT-3 넘었다!... 화웨이, 2천억개 매개변수의 초거대 언어 AI 모델 '판구 알파' 공개
- 현존하는 초거대 언어 인공지능 모델 ‘GPT-3’ 애저에 개방!...마이크로소프트, 애저 오픈AI 서비스 발표