GPT-3가 다 잘하는 건 아니며 현실의 물리적인 세계를 잘 모른다. 또 모델이 너무 크며, 기억을 못한다. 그리고 다음 단어 예측에서 한계를...

OpenAI의 3세대 GPT-3(Generation Pre-traination Transformer)는 최근 AI 커뮤니티에 단연 최고의 이슈이다. 많은 전문가들은 텍스트와 심지어 코드까지 작성하는 직관적인 능력을 갖추고 있다고 찬사를 아끼지 않고 있다.
이처럼 GPT-3는 이슈의 한가운데 있지만 GPT-3는 아직 실험 단계에 있다. 모든 스타일의 언어를 만들어낼 수 있는 뛰어난 능력을 가지고 있지만, 다수의 전문가들이 지적한 문제들이 있다. 심지어 오픈AI CEO 샘 알트만(Sam Altman)도 트위터를 통해 “GPT-3에 대한 과대한 평가가 너무 지나치다"라며, "AI는 세상을 바꿀 것입니다. 하지만 GPT-3는 아주 초기 단계에 불과합니다”라고 밝혔다.(아래는 샘 알트만 트위터 계정)
필자는 지난 글(본지 2020.08.14 GPT-3, 인류 역사상 가장 뛰어난 '언어 인공지능'이다.)에서 GPT-3가 무엇이고 어떤 일을 할 수 있는지 알아봤다. GPT-3가 워낙 범용적으로 뛰어난 언어 능력을 보여줬기에 API를 처음 써본 사람들은 인간 수준의 AI가 코앞에 있는 것 아니냐는 말을 하기도 했다.
샘 알트만이 말했듯이, GPT-3도 극복해야 할 여러 한계를 지닌다. 오늘은 GPT-3의 다섯 가지 한계를 이야기를 해보려고 한다.
첫 번째 한계: GPT-3가 다 잘하는 건 아니다.
GPT-3 논문에서는 42개의 언어 문제를 대상으로 테스트를 진행했다. GPT-3는 대부분의 테스트에서 훌륭한 성능을 보였지만, 이전 연구의 성능을 뛰어넘은 것은 일부에 불과했다. 즉, 해당 문제에 최적화된 모델에 비해서는 성능이 떨어지는 경우가 꽤 있었다는 의미다. 각 문제에서 사람의 능력에 못 미치는 것은 물론이다.
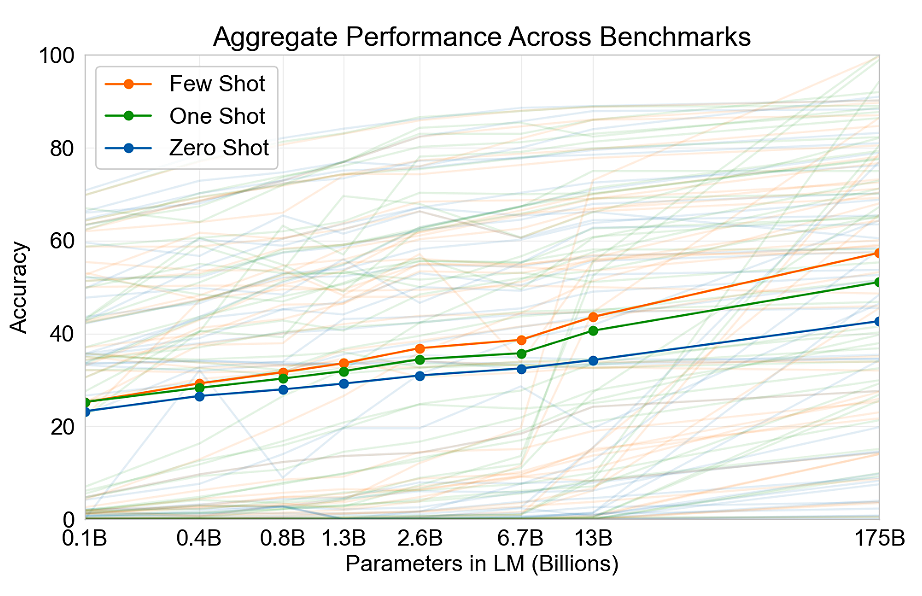
GPT-3가 멋진 건 하나의 모델이 다양한 문제를 범용적으로 잘 풀기 때문이지 모두 최고 수준으로 풀기 때문은 아니다. GPT-3보다 더 멋진 언어 모델이 나온다면 범용적일 뿐만 아니라 모든 문제에서 최고의 성능을 보일 수도 있는 것이다.
두 번째 한계: 현실의 물리적인 세계를 잘 모른다.
GPT-3가 특히 약한 영역은 현실의 물리적인 상식을 다루는 언어 문제이다. 예를 들어, “치즈를 냉장고에 넣으면 녹을까?” 같은 문제에 사람이라면 당연히 안 녹는다고 답하겠지만 GPT-3는 녹는다고 답한다.

왜 이런 문제가 생기는지 명확히 알 수는 없지만, 그럴 듯한 가설은 GPT-3가 세상을 글로 배웠기 때문이라는 것이다. 세상에는 직접 눈으로 보거나 경험해야 알 수 있는 것이 있다. 또한 그런 사실들은 너무 당연해서 명시적으로 언급하지 않는 경우가 대부분이다. GPT-3로서는 그런 사실을 학습할 기회가 없는 것이다.
그런 의미에서 GPT-3를 ‘집에서 엄청난 양의 정보를 습득한 장님’에 비유할 수도 있겠지만, 똑똑하지만 시각적인 정보와 경험 부족으로 놓치는 게 있는 것으로 앞으로 단순히 텍스트뿐 아니라 이미지나 비디오 등 시각적인 정보도 함께 습득한다면 이런 문제를 극복할 것으로 보인다. 혹은 로봇이 실제로 세상을 경험하면서 학습할 수도 있을 것이다. (GPT-3가 물리적인 세계를 아예 모른다는 건 아니고 상대적으로 약하다는 것으로 이해하는 게 정확하다. 글로도 물리적인 세계에 관해 꽤 많은 걸 학습할 수 있다.)
세 번째 한계: 모델이 너무 크다
GPT-3는 세계에서 가장 규모가 큰 언어처리 모델로 1,750억 개의 파라미터를 자랑한다. GPT-2(15억 개)보다는 100배 이상 크고 GPT-3 이전에 가장 큰 모델이었던 구글의 T5나 마이크로소프트의 튜링NLG(Turing-NLG)보다도 10배 이상 크다. 반면, 많은 파라미터는 엄청난 성능의 근간이 되기도 하지만 학습과 활용면에서 여러 어려움을 낳기 때문이다.
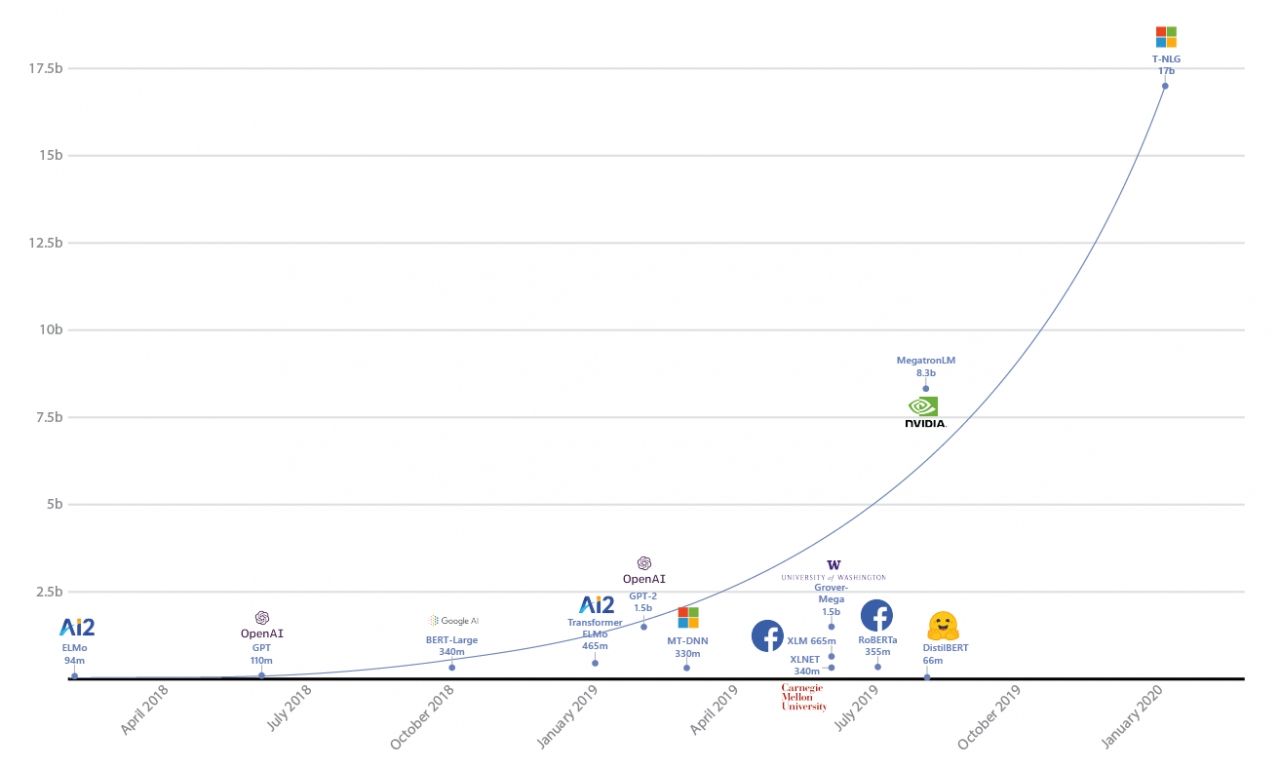
모델이 크면 당연히 학습시키는 데 시간과 비용이 엄청나게 많이 든다. GPT-3를 학습시키는 데 드는 비용을 정확히 추산할 수는 없지만 약 50억 원 정도가 소요되는 것으로 추정된다. 이는 단순히 GPT-3의 최종 모델을 학습시키는 데만 드는 비용을 계산한 것이며 그 과정에서 부가적으로 드는 비용은 정확히 계산하기도 어렵다.
또한 모델이 크면 활용하기도 어렵다. 모델을 서버에 올려놓고 사용할 때마다 계산을 해야하는데, 이때 필요한 시간과 비용도 만만치 않을 것이다. 지금 GPT-3의 API가 어떤 식으로 구현되어 있는지 정확히 알 수는 없지만(개인적으로 매우 궁금하다) GPT-3의 1/100 정도의 모델도 현재 서버의 스펙과 비용으로는 맘 놓고 쓸 수 있는 수준이 아닌 것을 고려하면 쉽게 쓸 수있는 수준은 아닐 것이다.
시간이 흘러 새로운 데이터가 많이 생기고 GPT-3를 재학습해야하는 시점이 오면 어떨까? 이전보다 시행착오는 줄어들겠지만 역시나 학습 비용은 어쩔 수 없이 많이 들것이다.
이처럼 GPT-3의 엄청난 크기는 많은 현실적인 어려움을 초래한다. 물론, 앞으로 학습 효율이 높아지고 GPU의 비용이 낮아지면 이 문제는 서서히 해결될 것으로 보인다.
네 번째 한계: 기억을 못한다
GPT-3의 기반이 되는 트랜스포머(Transformer) 구조에는 ‘기억’이라는 개념이 없다. 현재 문맥을 입력으로 주고 그에 따른 출력을 얻을 뿐이다.
물론, 그 ‘입력’에 기억해야 되는 요소를 넣어줄 수는 있다. 하지만 GPT-3도 그 입력의 크기는 2048 토큰(단어와 유사하지만 그보다는 약간 작은 단위라고 생각하면 된다)에 불과하다. 즉, GPT-3가 생성하는 모든 결과는 가장 최근의 2048 토큰만 보고 생성하는 것으로 보인다.
일반적인 경우라면 2048 토큰도 충분할 수 있지만, 장기적인 기억을 필요로 하는 언어 문제라면 이러한 구조는 한계가 있다. 아직 딥러닝으로 기억의 문제를 어떻게 풀 것인지는 명확한 해답이 나와있지 않지만 앞으로 자연어처리(NLP)의 발전을 위해 지속적으로 연구되어야 할 분야인 것으로 생각된다.
마지막으로 다음 단어 예측의 한계(?)
지난 글에서 설명했듯이 GPT-3는 방대한 양의 텍스트를 대상으로 끊임없이 다음 단어를 예측하는 단순무식한 방법으로 학습했다.
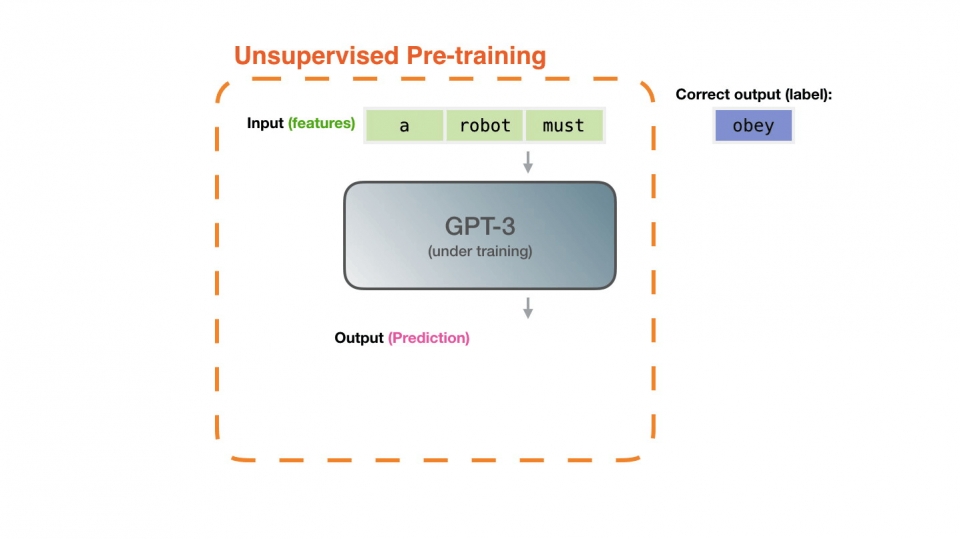
하지만 생각해보면 이러한 학습 방법은 상당히 어색한 것이다. 사람은 뭔가 학습을 할 때 텍스트를 보고 다음 단어를 예측하는 방식으로 학습 않고 사람은 텍스트를 읽고 이해하고 원리를 이해한다.
그래서 많은 사람들이 이런 비판을 하기도 한다. GPT-3가 엄청 똑똑한 것처럼 보이지만, 사실 GPT-3는 아는 게 아무 것도 없고 그저 통계적으로 가장 그럴듯한 다음 단어를 차례차례 생성하는 것일 뿐이며, 뭔가 알고 이해하고 말을 하는 게 아니라 마치 이해하고 말하는 것처럼 보일 뿐이라고. 그렇기 때문에 단순히 모델 크기와 데이터를 키우는 것만으로는 한계에 부딪힐 것이라고. 비판은 분명 타당한 면이 있으며 GPT-3 논문에서도 언급하는 바이다.
하지만 정말 그럴까요? 솔직히 필자는 잘 모르겠다. 그럼 GPT-3가 생각을 하는 걸까요 아니면 통계적 예측을 하는 걸까요? 둘 중 하나에 속한다는 걸 어떻게 증명할까요? 둘이 정말 큰 차이가 있거나 확실히 구분되는 걸까요? 과연 ‘생각’을 한다는 건 정확히 무슨 의미일까요? 이러한 질문에 확실한 정답을 말해줄 수 있는 사람은 아마 없을 것이다.
결론적으로 어찌보면 어느 쪽이든 확실히 논증될 수 없을지도 모른다. 그냥 그렇기 때문에 더욱 재미있는 논쟁거리다. 그런 의미에서 다음 글에서는 GPT-3를 둘러싼 논쟁에 관해서 써보려고 한다. 다른 분들의 생각도 매우 궁금하다.
필자 김종윤은 현재, 스캐터랩 코파운더 및 대표이사로 2013년 카카오톡 대화를 통한 감정분석 ‘텍스트앳’ 출시, 2015년 커플 메신저 비트윈과의 협업으로 사랑을 이해하는 인공지능 ‘진저’ 출시, 2016년 심리학 기반의 연애 컨텐츠와 데이터 기반의 연애 분석을 제공하는 ‘연애의 과학’ 출시(출시 후 현재까지 한국에서 250만, 일본에서 40만 다운로드 달성), 2019년 손쉽게 인공지능의 일상대화를 빌드할 수 있는 솔루션, 핑퐁 빌더 공개 등과 2018년 NCSOFT, 소프트뱅크벤처스, 코그니티브 인베스트먼트, ES인베스터로부터 50억 원 시리즈 B 투자를 성공적으로 유치했으며, 2017년, 2018년 포브스 코리아 '2030 Power Leader'로 선정되기도 했다.(편집자 주)
관련기사
- GPT-3, 인류 역사상 가장 뛰어난 '언어 인공지능'이다
- [이슈] OpenAI, 혁신적인 AI 자연어처리(NLP) 모델 'GPT-3' 공개
- [영상] 초보자도 쉽게 GPT-3를 사용해 혼자서 GPT-3 모델을 구현한다
- OpenAI, GPT-3 언어 모델... 마이크로소프트, 독점 라이선스 확보
- GPT-3, 왜 요금제를 선택했으며... 마이크로소프트에 독점 라이선스를 부여했나?
- 테슬라 일론 머스크, 오픈AI... 마이크로소프트에 GPT-3 독점 라이선스 부여한 것! 공개 비판
- GPT-3는 과연 얼마나 똑똑한 것일까?
- [AI 리뷰] 오픈AI, 글 쓰는 GPT-3에서 진화... 텍스트 읽고 그림 그리는 AI 모델 'DALL·E' 및 'CLIP' 공개
- [이슈] GPT-3 넘었다!... 화웨이, 2천억개 매개변수의 초거대 언어 AI 모델 '판구 알파' 공개
- 현존하는 초거대 언어 인공지능 모델 ‘GPT-3’ 애저에 개방!...마이크로소프트, 애저 오픈AI 서비스 발표