작업 당 한 번의 데모에서 1,000 번까지 다양한 데모 데이터 세트에 대해 트랜스포터 네트워크를 학습하고, 13 명의 인간 작업자로부터 모든 작업에 대해 총 11,633 개의 픽앤 플레이스 작업으로 학습 된 트랜스포터 네트워크는 병에 든 구강 청결제 키트를 조립하는 데 98.9 %의 성공률을 달성했다.
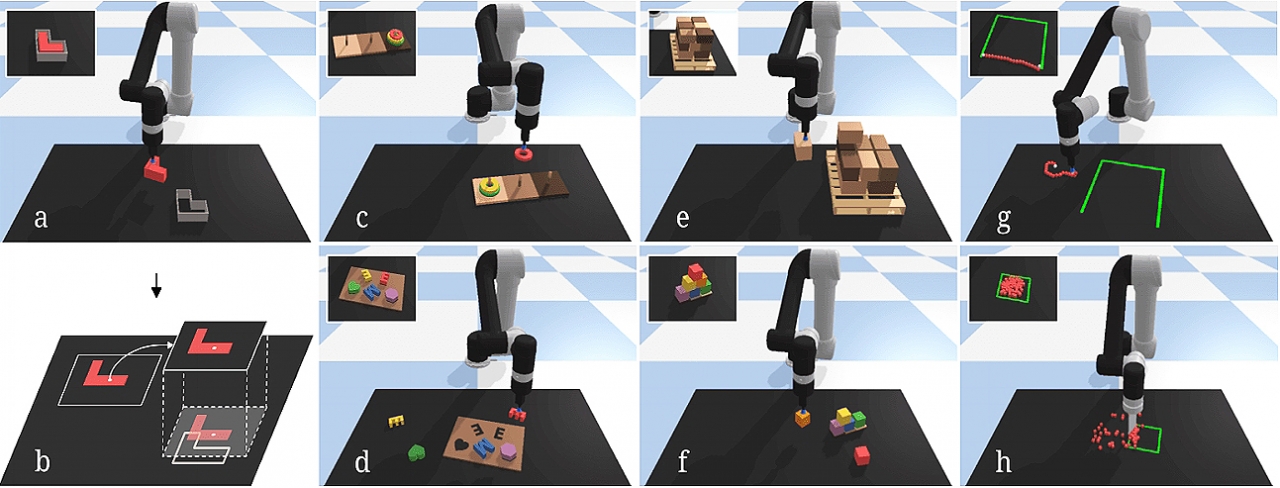
구글 로봇 연구팀이 물체를 잡는 로봇들이 어떤 시각적 조건이 중요한지, 그리고 어떤 장면에서 어떻게 재배치되어야 하는지를 추론할 수 있도록 하는 인공지능(AI) 모델 아키텍처 '트랜스포터 네트워크(Transporter Network)'를 개발하고 이 결과를 아카이브를 통해 지난 27일(현지시간) 발표했다. 이 모델은 로봇이 블록 피라미드 쌓기, 키트 조립, 밧줄 조작, 작은 물체 밀기 등 여러 가지 작업에서 우수한 성능을 달성했다고 밝혔다.
또한 오는 11월 14일부터 16일까지 MIT 샘버그 컨퍼런스 센터(MIT Samberg Conference Center)에서 가상으로 개최되는 '로봇 학습 컨퍼런스 2020(CoRL. Conference on Robot Learning)'에서 이 연구 결과 발표와 시연을 예정하고 있다.
로봇의 시각 인식은 늘 도전 과제이다. 예를 들어, 로봇은 다양한 종류의 물체 더미에서 각 물체를 식별하고 집어내야 하는 '기계적 검색(Mechanical Search)'을 수행하는 데 어려움을 겪는다. 대부분의 로봇은 이 환경에 특별히 적응할 수 없으며 기계 검색에서 로봇 집게를 안내하는 데는 아직 충분한 AI 모델이 부족하다. 또 이 문제는 코로나19 대유행으로 인해 기업이 생산 및 제조 현장에서 자동화 채택을 고려하게 되면서 더 표면화되었다.
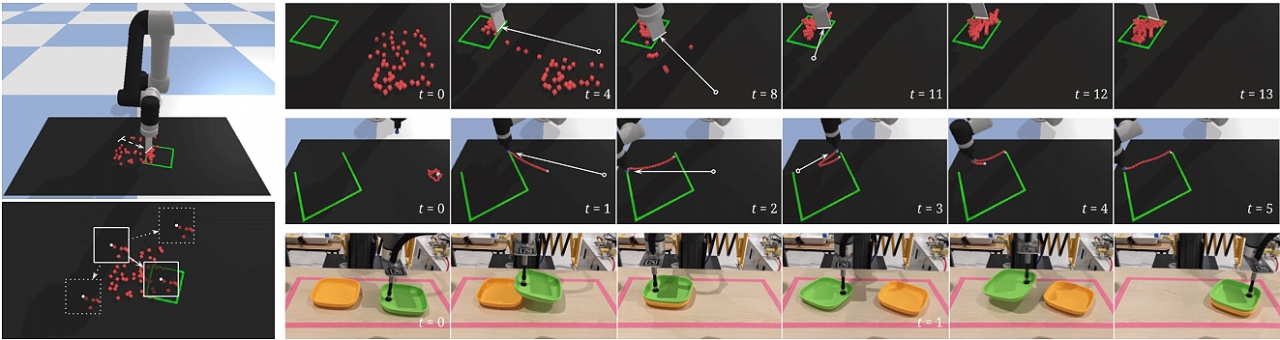
연구팀은 트랜스포터 네트워크가 조작할 대상에 대한 이전의 3D 모델, 포즈 또는 클래스 카테고리 지식을 요구하지 않고 대신 부분 깊이 카메라(Partial Depth Camera) 데이터에 포함된 정보에만 의존한다고 말한다. 또한 새로운 물체와 구성을 일반화할 수 있고, 어떤 작업에서는 하나의 시연을 통해 학습할 수 있다. 실제로 10개의 독특한 테이블 작업에서 표면상으로는 100개의 전문가의 비디오 데모를 사용하여 새로운 구성의 객체를 가진 대부분의 작업에서 90% 이상의 성공을 거두었다고 한다.
연구팀은 작업 당 한 번의 데모에서 1,000 번까지 다양한 데모 데이터 세트에 대해 트랜스포터 네트워크를 학습시켰다. 먼저 0.5 x 1m 작업 공간을 내려다보는 흡입 그리퍼(로봇 핸드)가 있는 유니버설 로봇(Universal Robot) UR5e으로 구성된 시뮬레이션 벤치마크 학습 환경 인 레이븐스(RAVENS)에 이를 배포했다. 그런 다음 애저 키넥트(Azure Kinect)를 포함한 흡입 그리퍼 및 카메라가 있는 로봇‘UR5e’을 사용하여 키트 조립 작업에서 트랜스포터 네트워크를 검증했다.

여기서, 참고로 마이크로소프트의 애저 키넥트는 촬영한 영상을 내부 컴퓨터에서 처리하여, 피사체가 움직인 것을 감지하거나 카메라의 시야 내에 들어온 물체 등을 자동으로 읽어 들여서 얻어낸 데이터를 서버에 전송한다.
또한 연구팀은 코로나19 펜데믹으로 폐쇄된 현장에서 원격으로 로봇을 원격 조종할 수 있는 유니티(Unity) 기반 프로그램을 사용하여 실험을 수행했다. 실험에서 원격 운영자는 가상현실 헤드셋 또는 마우스와 키보드를 사용하여 5 개의 작은 병에 담긴 구강 청결제 키트 또는 9 개의 독특한 모양의 나무 장난감 키트를 반복적으로 조립하고 분해하는 작업을 수행했다. 13 명의 인간 작업자로부터 모든 작업에 대해 총 11,633 개의 픽앤 플레이스 작업으로 학습 된 트랜스포터 네트워크는 병에 든 구강 청결제 키트를 조립하는 데 98.9 %의 성공률을 달성했다.

연구팀은 이 연구 논문을 통해 “이번 연구에서 우리는 공간적 변위를 추론하는 단순한 모델 아키텍처인 트랜스포터 네트워크를 제시했는데, 이는 시각적 입력으로부터 로봇의 행동을 매개 변수화할 수 있다”고 밝혔다.
또 연구팀은 "객관성을 가정하지 않고 공간 대칭을 이용하며 종단 간의 대안보다 비전 기반 조작 작업을 학습하는 데 더 효율적인 샘플이다. 현재, 한계 측면에서 카메라 - 로봇 교정에 민감하며 토크를 어떻게 통합하고 강제 조치를 스틱으로 통합할 것인지는 여전히 불명확하다. 그러나 전반적으로 우리는 이 컨셉에 흥분하고 있으며, 이를 실시간 고효율 제어와 도구 사용과 관련된 작업으로 확대할 계획이다"라고 덧붙였다.
한편, 이 연구 및 개발 과정은 27일(현지시간) 아카이브(arxiv)를 통해 '트랜스포터 네트워크: 로봇 조작을 위한 시각세계의 재조정(Transporter Networks: Rearranging the Visual Worldfor Robotic Manipulation- 다운)'이란 제목으로 게재됐다. 또한, 구글 로봇 연구팀은 가까운 시일 내에 코드와 오픈소스 레이븐스 및 관련 API을 공개할 계획이라고 밝혔다.