각종 분야에서 인공지능 모델 효율적 사용 기대... 12월 인공지능 분야 최고 학회 뉴립스서 발표 예정

서울대학교 공과대학(학장 차국헌) 컴퓨터공학부 전병곤 교수 연구팀이 그래픽 처리 장치(GPU)를 활용하여 인공지능(AI) 학습과 추론 수행시 기존 시스템 대비 최대 22배 빠른 님블(Nimble) 시스템을 개발했다고 30일 밝혔다.
해당 시스템을 통해 응용 서비스에서 인공지능 모델을 곧바로 고속 수행하는 것이 가능해져, 다양한 분야에서 인공지능 모델의 효율적 사용이 가능할 것으로 기대된다.
현재 수많은 기업과 연구소에서 인공지능 계산의 편의성을 위해 파이토치(PyTorch), 텐서플로우(TensorFlow) 등의 딥러닝 오픈 소스 플랫폼을 사용하고 있다. 이러한 시스템들은 인공지능 학습과 추론 수행 속도 향상을 위해 GPU를 이용한다. GPU에 연산 수행을 요청하기 전에는 이를 위한 준비를 하는 스케줄링(scheduling) 과정을 매번 진행한다.
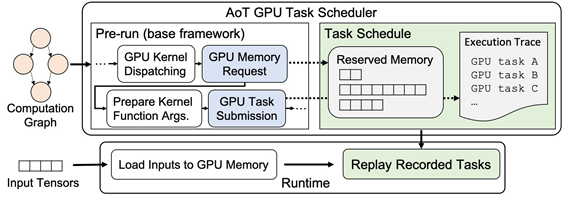
전병곤 교수 연구팀은 현 인공지능 시스템들이 스케줄링 과정의 오버헤드로 인해 GPU를 효율적으로 활용하지 못하고, 또한 GPU에서 병렬로 수행할 수 있는 연산들을 병렬로 수행하지 못한다는 것을 밝혀냈다.
연구팀은 이러한 문제를 해결하기 위해, 사전에 스케줄링 과정을 한 번만 하고 여러 개의 GPU 스트림을 사용하여 다수의 GPU 연산을 동시에 수행하는 인공지능 시스템 님블을 개발하였다.
님블은 파이토치 대비 인공지능 추론을 22.3배, 학습을 3.6배 빠르게 수행하며, 인공지능 추론 특화 시스템인 엔비디아(NVIDIA)사의 텐서RT(TensorRT)보다 2.8배 빠르게 인공지능 추론을 수행한다. 또한 님블은 개발 시 사용자 편의성을 고려해 설계되었다. 코드를 몇 줄만 수정하면 기존에 사용하던 파이토치 모델을 님블을 이용해 수행할 수 있다.

이번 연구 결과는 오는 12월 온라인 개최 예정인 인공지능 분야 세계 최고 학회 뉴립스(Neural Information Processing Systems·신경정보처리시스템학회)의 스포트라이트(spotlight) 세션에서 '님블: 딥러닝 GPU 연산 스케줄링의 경량화 및 병렬화(Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning)'이란 제목으로 발표될 예정이다. 이 스포트라이트 세션은 올해 뉴립스에 제출된 9467편의 논문 중 약 상위 4%의 논문에만(구두 세션: 105편, 스포트라이트 세션: 280편) 주어지는 발표 기회이다.
전병곤 교수는 이번 개발에 대해 “세계를 선도할 인공지능 플랫폼 기술을 발표하게 되어 기쁘다"며, "앞으로 활발히 인공지능 플랫폼 기술을 연구하고 사업화하는데 주력하겠다“라고 소감을 전했다.