GPT-3는 완벽하지 않으며, 공학 및 자연과학 분야에 약하다. 또한 모델 크기가 중요하며, 특화된 모델은 효율이 높으며 AI의 벤치마크와 인간의 벤치마크가 같아진다... 그래도 GPT-3는 놀랍다.

필자 김종윤은 현재, 스캐터랩 코파운더 및 대표이사로 2013년 카카오톡 대화를 통한 감정분석 ‘텍스트앳’ 출시, 2015년 커플 메신저 비트윈과의 협업으로 사랑을 이해하는 인공지능 ‘진저’ 출시, 2016년 심리학 기반의 연애 컨텐츠와 데이터 기반의 연애 분석을 제공하는 ‘연애의 과학’ 출시(출시 후 현재까지 한국에서 250만, 일본에서 40만 다운로드 달성), 2019년 손쉽게 인공지능의 일상대화를 빌드할 수 있는 솔루션, 핑퐁 빌더 공개 등과 2018년 NCSOFT, 소프트뱅크벤처스, 코그니티브 인베스트먼트, ES인베스터로부터 50억 원 시리즈 B 투자를 성공적으로 유치했으며, 2017년, 2018년 포브스 코리아 '2030 Power Leader'로 선정되기도 했다.(편집자 주)
GPT-3가 공개된 지 5개월이 지났다. 놀라운 성능만큼 유명세도 대단했다.
아직은 머신러닝이 대중적인 분야가 아님에도 불구하고 언론까지 나서 GPT-3를 앞다퉈 다룰 정도였다. 이로써 GPT-3는 역사상 가장 뛰어난 언어 AI가 되었을 뿐 아니라, 역사상 가장 유명한 언어 AI가 된 것이다. 이런 현상은 GPT-3가 타 모델과 차원이 다른 언어 생성 성능을 보여주었기 때문이다.
그럼 과연 GPT-3는 정확히 얼마나 똑똑한 걸까?
벤치마크(benchmark)라는 용어가 있다. 어떤 대상의 성능을 측정할 때 기준이 되는 테스트이자 지표다. 당연히 언어 AI에도 벤치마크가 있다. 글루(GLUE)와 슈퍼블루(SuperGLUE)가 바로 그것이다.
GLUE는 2018년에 뉴욕대, 워싱턴대, 딥마인드의 자연어처리(NLP) 연구자들이 함께 만든 언어 벤치마크로 언어 능력을 측정하는 9가지 테스트셋을 포함하고 있다. 예를 들어, 해당 문장이 문법적으로 맞는지 판단하는 CoLA, 두 문장의 의미가 유사한지 판단하는 STS-B, 두 문장의 논리적 상관관계를 판단하는 MNLI 이 있다.
문제는 불과 1년 만에 언어 모델의 성능이 인간 수준을 넘어버렸다는 것이다.
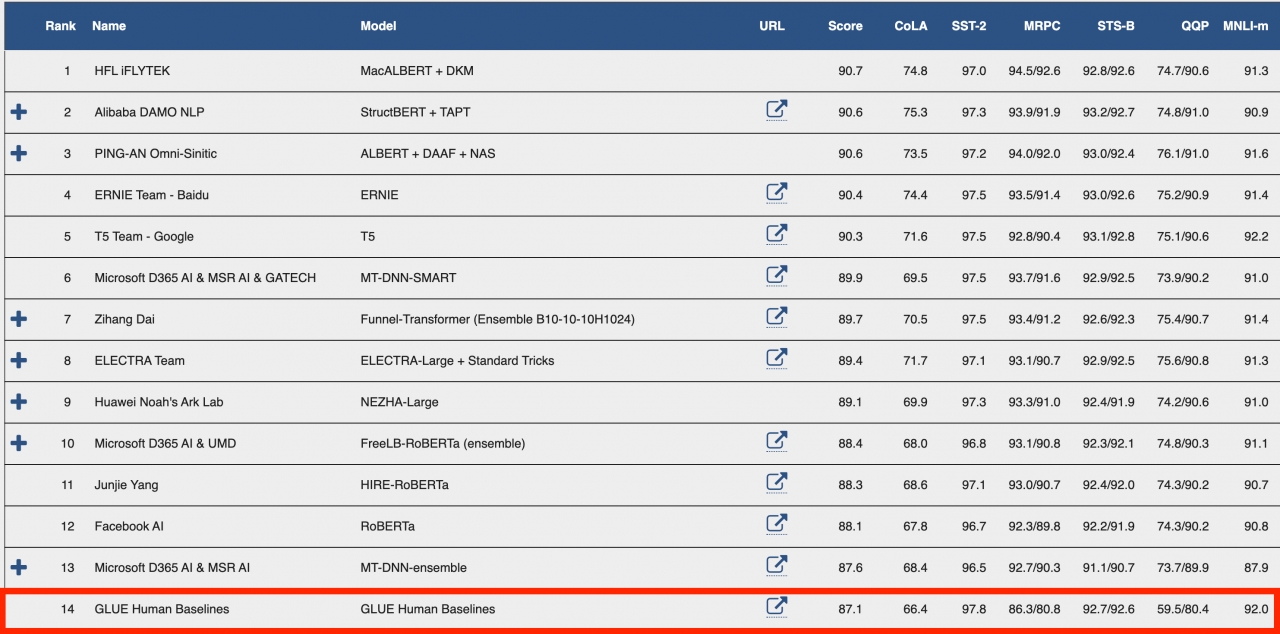
그래서 이들은 다시 모여 2019년에 SuperGLUE라는 벤치마크를 만든다. 이 벤치마크는 유사한 컨셉의 8가지 과제를 포함하며 가장 큰 차이는 앞에 'Super'라는 단어가 붙은 것에서 알 수 있듯이 GLUE보다 더 어렵다.
그러나 SuperGLUE 또한 불과 1년 만에 인간 수준에 0.6점 차이로 근접해 버렸다. 수년간 힘들게 개발한 게임이 불과 6시간 만에 클리어되는 광경을 목도한 디아블로3 개발자들이 이런 심정이었을까?
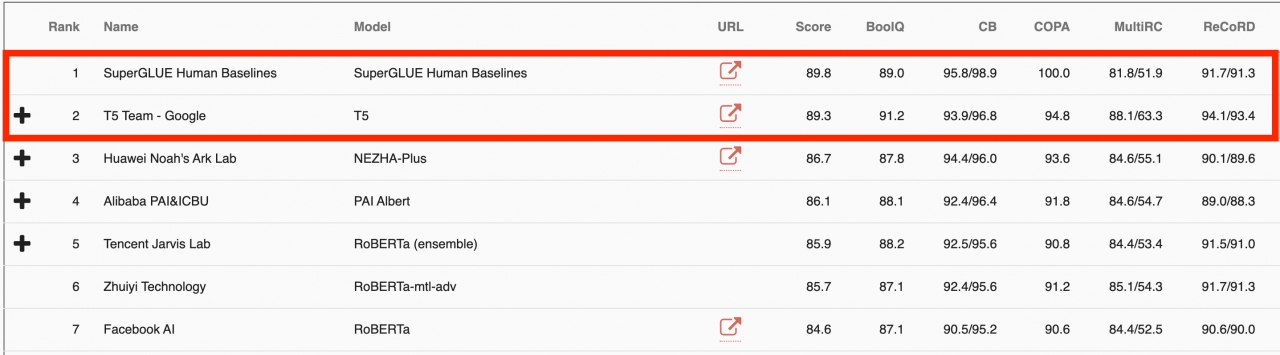
더 큰 문제는 GLUE나 SuperGLUE 같은 벤치마크에서 머신러닝 모델이 인간 수준에 근접하거나 넘어섰음에도 불구하고, 종합적으로 봤을 때 언어 능력이 인간 수준에 근접한 건 전혀 아니라는 점이다. 현재 사용되는 벤치마크가 정말 AI의 능력을 제대로 측정하는 것인지 의문이 생길 수밖에 없는 것이다.
이에 여러 NLP 연구자들이 모여 새로운 벤치마크를 제안한다. 벤치마크를 제안한 논문의 제목은 '대규모 멀티태스크 언어 이해도 측정(Measuring Massive Multitask Language Understanding)'이다. 아이디어는 간단하다. 어떤 언어 AI가 얼마나 똑똑한지 알아보려면, 그냥 엄청나게 다양한 분야의 다양한 문제를 내보면 되는 거 아니냐는 것이다.
아래 예를 들어본다.
▷고등학교 수학
만약 4 daps = 7 yaps이고, 5 yaps = 3 baps라면, 42 baps는 몇 daps인가?
A. 28
B. 21
C. 40
D. 30
(직접 한번 풀어본다. 정답은 글의 맨 마지막에 있다.)
이 문제를 넣으면 언어 모델은 아마 A, B, C, D 중 하나의 답을 생성해 낼 것이다. 그리고 그게 정답인지 확인하면 되는 것으로 참 쉽다. 또 몇 분야에서 예시 문제 몇 개를 더 풀어 본다.
▷법학
한 백과사전 세일즈맨이 한 은둔자의 집에 도착했다. 그곳에는 “세일즈맨 거부. 어기는 사람은 처벌받음. 위험은 당신 책임.”이라는 표지판이 있었다. 세일즈맨은 초대받은 사람은 아니었지만, 표지판을 무시하고 차를 몰고 집 쪽으로 들어갔다. 그가 코너를 도는 순간, 땅에 묻혀있던 폭발물이 터졌고, 세일즈맨은 다쳤다. 이 상황에서 세일즈맨이 그 은둔자에게 부상에 대한 보상을 요구할 수 있을까?
A. 있다. 단, 은둔자가 폭발물을 설치했을 때 단순히 침입을 막는 걸 넘어서 해하려는 의도가 있어야 한다.
B. 있다. 단, 은둔자가 그 폭발물을 설치했어야 한다.
C. 없다. 왜냐하면 세일즈맨이 경고를 명시한 표지판을 무시했기 때문이다.
D. 없다. 은둔자는 침입자가 자기 자신이나 가족을 해할 수도 있다는 합리적인 두려움을 갖고 있었기 때문이다.
▷물리학
공을 손에 쥐고 가만히 떨어트리면 공은 9.8m/s29.8m/s2의 가속도로 떨어진다. 공기 저항이 없다고 가정한 상태에서 아래쪽으로 공을 힘있게 던진다면, 손을 떠난 공의 가속도는?
A. 9.8m/s29.8m/s2
B. 9.8m/s29.8m/s2 초과
C. 9.8m/s29.8m/s2 미만
D. 던진 속도를 알려주지 않으면 알 수 없음
▷대학 수학
복소평면(complex z-plane)에서 z2=∥z∥2z2=‖z‖2을 만족하는 점들이 이루는 도형은?
A. 두 점
B. 원
C. 반직선
D. 직선
▷분야: 의학
33세 남성이 갑상선암에 걸려 급성 갑상선 전절제술을 시술했다. 수술하는 동안 중등도의 출혈이 경부 좌측 부분의 몇몇 혈관에 나타나 봉합이 필요하게 되었다. 수술 후 혈장검사 수치로 칼슘 수치는 7.5 mg/dl, 알부민 수치는 4 g/dl, 부갑상선호르몬 수치(PTH)는 200 mg/ml였다. 다음 중 어느 혈관의 손상이 이 환자의 검사결과와 상관있는가?
A. 목갈비동맥의 가지
B. 바깥목동맥의 가지
C. 갑상목동맥의 가지
D. 속목정맥의 지류
대충 이런 식이며 느낌이다.
저자들은 의학부터 수학, 화학, 외교, 경제학, 철학 등등까지 무려 57개의 분야에서 15,908개의 문제를 준비했다. 이 중 14,080개의 문제가 테스트로 사용되었다. 과연 GPT-3의 정답률은 얼마였을까?
GPT-3의 성능 테스트 대상이 된 모델의 정답률은 다음과 같았다. (사지선다형의 문제이므로 25% 가 랜덤 확률임을 참고하면 된다.)
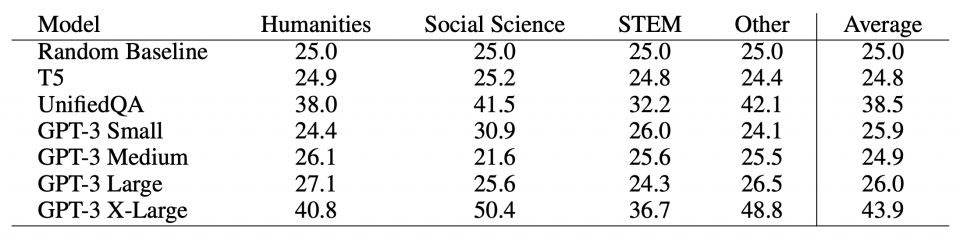
가장 큰 GPT-3 모델의 정답률은 43.9% 이었다.
또한 분야별 정답률은 다음과 같았다.
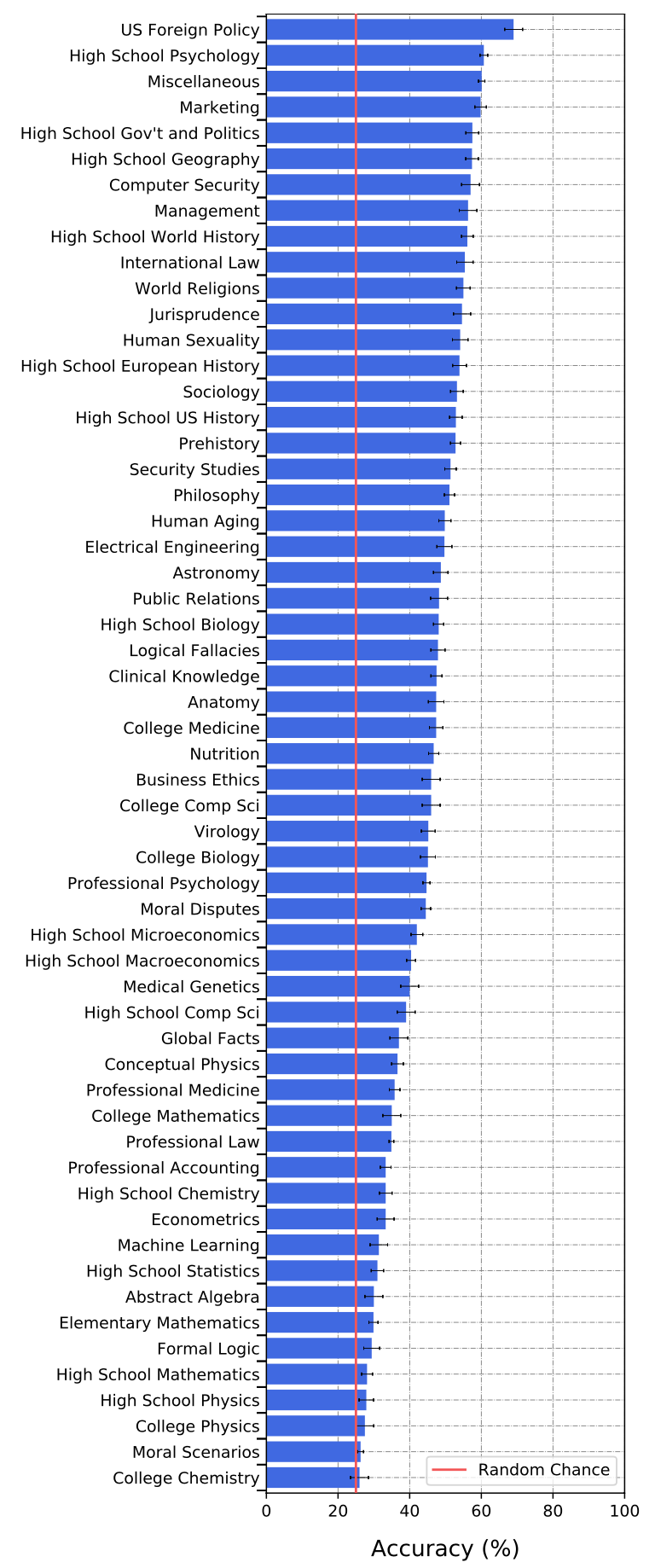
그러면 이 결과는 무엇을 말해주는 걸까? GPT-3 성능 테스트 결과를 바탕으로 여섯 가지로 정리해 본다.
1. GPT-3는 (당연히) 완벽하지 않다
테스트 결과를 보면, GPT-3는 이 벤치마크에서 44점을 기록했다. 모두 무작위로 찍었을 때 받는 점수인 25점보다는 훨씬 높은 점수이고 절대 만만치 않은 문제임을 고려할 때 꽤 인상적인 점수이기는 하지만, 동시에 엄청나게 높은 점수는 아니다.
이 벤치마크에 대한 인간의 점수가 몇 점인지는 알 수 없다. 아마 사람마다 편차가 크지만 각 분야의 전문가들이 문제를 푼다면 아마 90점 이상은 기록할 것이다. GPT-3는 아직 그에 한참 못 미치는 수준이다.
2. GPT-3는 공학/자연과학 분야에 약하다
위의 분야별 테스트 결과를 보면 알겠지만, GPT-3는 상대적으로 인문·사회과학 분야에서 높은 점수를 기록한 반면 공학·자연과학 분야에서는 약한 모습을 보였다. 이런 현상에는 여러 이유가 있겠지만 GPT-3 학습에 사용된 데이터가 인문·사회과학적인 데이터에 쏠려있어서 그럴 수도 있고, 객관식 테스트의 특성상 인문·사회과학 분야는 암기식 테스트가 많고 공학·자연과학 분야는 추론 능력을 확인하는 테스트가 많아서 그럴 수도 있다. 현재의 GPT-3는 사고력보다는 지식의 양에서 강점이 있다고 볼 수 있다.
3. 그래도 GPT-3는 놀랍다
GPT-3는 대량의 텍스트 데이터를 대상으로 다음 단어 예측 문제를 수행한 모델이다. 그런데 어떻게 이 벤치마크에서 랜덤 이상의 점수를 기록할 정도의 지식과 사고력을 갖게 된 걸까? 필자는 점수를 떠나서 GPT-3가 랜덤이 아닌 점수를 기록했다는 사실 자체가 놀랍다.
따지고 보면 평범한 한 명의 성인이 57개 분야의 문제를 모두 푼다고 했을 때, 전체 평균 점수가 50점을 넘기가 쉽지 않을 것 같다. 이 벤치마크에서 GPT-3는 평범한 인간 수준에는 근접했다고도 볼 수 있는 셈이다. 주목해야 하는 건 현재 수준이 아니라 AI가 발전하는 속도와 방향인 것이다.
4. 모델 크기가 중요하다
보통 GPT-3를 하나의 모델로 이야기를 하지만, 사실 GPT-3는 여러 종류가 있다. 일반적으로 우리가 GPT-3라고 부르는 모델은 가장 큰 모델(1,750억 개의 파라미터)을 말한다. 하지만 GPT-3도 같은 데이터를 같은 방식으로 학습시킨 여러 사이즈의 모델이 있다.
논문에서는 더 작은 사이즈의 GPT-3 모델로도 테스트를 해봤다. Small(27억 개 - 27억 개가 스몰 사이즈라니…), Medium(67억 개), Large(130억 개)짜리 모델이었는데, 신기하게도 130억짜리 GPT-3를 포함한 모든 나머지 모델에서는 정답률이 25%밖에 나오지 않았다. 즉, 랜덤한 수준을 벗어나지 못했다는 의미다. 모든 GPT-3가 같은 데이터, 같은 방식으로 학습을 했다는 걸 생각해보면, 모델 크기가 커지면서 갑자기 어떤 능력을 갖추게 된 것으로 보인다. 모델 크기의 중요성을 보여주는 결과이다.
5. 특화된 모델은 효율이 높다
논문에서는 UnifiedQA (Khashabi et al., 2020)라고 불리는 모델도 함께 테스트했다. 광범위한 유형의 텍스트를 학습한 GPT-3와 달리 UnifiedQA는 다양한 분야의 질의-응답 데이터를 중심으로 학습한 모델로서, GPT-3 Small과 비슷한 30억 파라미터 정도의 크기다.
하지만 UnifiedQA의 벤치마크 성능은 39점이었다. GPT-3의 44점보다 낮긴 하지만 크게 차이가 나는 건 아니다. 게다가 UnifiedQA의 모델 크기는 GPT-3의 약 1/60에 불과하다. 그만큼 범용성을 버리고 특정 문제에 특화된 학습을 하면 GPT-3보다 60배나 효율이 높은 모델을 학습시킬 수 있다는 의미이다. Fine-tuning의 중요성을 보여주는 결과다.
6. AI의 벤치마크와 인간의 벤치마크가 같아진다
위의 문제 예시를 보면, 사실 이 벤치마크는 인간의 능력을 측정할 때 사용해도 좋은 테스트다. 만약 누군가가 인간의 종합적인 지식과 사고력을 측정하는 벤치마크를 만든다면 이런 문제들로 구성할 것 같다.
결론적으로 지금까지의 모든 벤치마크는 “인간에게는 매우 쉬운데, AI에게는 어려운” 문제들로 구성되어 있었다. 처음에 소개한 GLUE나 SuperGLUE도 마찬가지다. 이러한 벤치마크는 AI의 성능을 확인하는 데는 유용할지 몰라도 인간의 능력을 측정하기는 어려웠다. 인간이라면 누구나 쉽게 풀 수 있는 문제이기 때문이다.
하지만 이 벤치마크는 인간에게도 어렵고 AI에게도 어려운 벤치마크이다. 최근 몇 년간 언어 AI가 빠르게 발전한 결과, 이제 AI의 성능을 측정하는 벤치마크와 인간의 성능(?)을 측정하는 벤치마크가 같아진 것이다. 재밌는 현상이고, 흥미로운 시대이다. 어쩌면 이 벤치마크의 가장 큰 의의는 이런 유형의 벤치마크가 나왔다는 사실 자체일지도 모른다. 과연 이 벤치마크는 언제 정복이 될까? 생각해 본다.
관련기사
- [AI 칼럼] 자연어처리(NLP) 기술의 상용화와 그에 따르는 과제
- 네이버, GPT-3 능가할 한국어, 일본어 초거대 인공지능 언어 모델 만든다
- [AI 칼럼] GPT-3와 소프트웨어 라이선스... 그리고 오픈 소스의 정의
- 테슬라 일론 머스크, 오픈AI... 마이크로소프트에 GPT-3 독점 라이선스 부여한 것! 공개 비판
- GPT-3, 왜 요금제를 선택했으며... 마이크로소프트에 독점 라이선스를 부여했나?
- OpenAI, GPT-3 언어 모델... 마이크로소프트, 독점 라이선스 확보
- [영상] 초보자도 쉽게 GPT-3를 사용해 혼자서 GPT-3 모델을 구현한다
- GPT-3... 휼륭하지만 '다섯 가지' 한계를 짚어본다
- GPT-3, 인류 역사상 가장 뛰어난 '언어 인공지능'이다
- [이슈] OpenAI, 혁신적인 AI 자연어처리(NLP) 모델 'GPT-3' 공개
- [AI 리뷰] 오픈AI, 글 쓰는 GPT-3에서 진화... 텍스트 읽고 그림 그리는 AI 모델 'DALL·E' 및 'CLIP' 공개
- [이슈] GPT-3 넘었다!... 화웨이, 2천억개 매개변수의 초거대 언어 AI 모델 '판구 알파' 공개
- 현존하는 초거대 언어 인공지능 모델 ‘GPT-3’ 애저에 개방!...마이크로소프트, 애저 오픈AI 서비스 발표