컴퓨터 비전과 자연어처리(NLP) 기술을 결합해, 제시된 텍스트를 인식해 이미지를 생성하고 이미지를 각각 카테고리로 분류할 수 있는 두 가지 새로운 AI 모델...

딥러닝이 컴퓨터 비전에 혁명을 가져 왔지만 현재, 접근 방식에는 몇 가지 주요 문제가 있다고 한다. 일반적인 이미지 데이터 세트는 노동 집약적이고 수집 및 가공하는 데 많은 비용이 많이 들며 AI가 응용할 수 있는 좁은 시각 개념만 학습시키고 있다. 표준 비전 모델은 하나의 작업과 그에 속한 작업에만 능하며 새로운 작업에 적응하는 데 상당한 노력이 필요하다
오픈AI가 컴퓨터 비전과 자연어처리(NLP) 기술을 결합해, 제시된 텍스트를 인식해 이미지를 생성하고 이미지를 각각 카테고리로 분류할 수 있는 두 가지 새로운 AI 모델 '클립(Contrastive Language-Image Pre-training. 이하 CLIP)'과 'DALL-E'를 지난 5일 공개했다.
먼저, AI 일러스트레이터 DALL · E는 기발한 이미지를 만든다. 이 모델은 텍스트 입력에 따라 다양하고 때로는 초현실적인 이미지를 만들도록 훈련되었기 때문에 상상력을 마음껏 발휘할 수 있다. 예를 들어, '개와 산책하는 투투(발레 치마)의 아기 무' 그림 또는 '하프로 만든 달팽이'를 만들 수 있다. DALL · E는 처음부터 이미지를 생성 할뿐만 아니라 텍스트 또는 이미지 프롬프트와 일치하는 방식으로 기존 이미지를 재 생성하도록 훈련되었다.
DALL-E라는 이름은 초현실주의 화가 살바도르 달리(Salvador Dali)와 픽사(Pixar)의 윌-E(WALL-E)에서 따왔다.

OpenAI의 GPT-3는 언어 입력으로 다양한 텍스트 생성 작업을 수행할 수 있는 딥러닝 언어 모델로, GPT-3는 인간처럼 이야기를 쓸 수 있다. DALL·E의 경우 샌프란시스코에 소재한 AI 연구소를 통해 텍스트와 이미지를 바꾸고 AI가 반쯤 완성된 이미지를 완성하도록 훈련시켜 Image GPT를 구현한 것이다.
특히, DALL·E는 동물이나 사물의 이미지를 인간 시각적으로 표현할 수 있으며, 관련 없는 아이템을 감각적으로 결합하여 하나의 이미지로 만들어 낼 수도 있다. 공개된 테스트 이미지를 살펴보면 DALL-E가 생성된 형상에서 오브젝트(객체)를 능숙하게 조종하고 재배열할 수 있는 능력을 갖췄고, 또 질감이나 입체감처럼 제시되지 않은 부분까지 세심하게 표현해 낼 수 있는 것으로 보인다.
여기서, 이미지의 성공률은 텍스트가 얼마나 잘 표현되는지에 따라 달라진다. 또한 캡션이 이미지가 명시적으로 표시되지 않은 특정 세부 정보를 포함해야 한다고 암시할 때 종종 빈칸을 채울 수 있다. 예를 들어, '거북으로 만든 기린'이나 '아보카도 모양의 안락의자'라는 문구로도 만족스러운 결과를 제공한다.
또 하나의 AI모델 클립(CLIP, 대조적인 언어 이미지 사전 훈련)는 자연어를 기반으로 정확한 이미지 분류를 수행할 수 있는 신경망이다. 이를 통해 필터링 되지 않고 매우 다양하며 노이즈가 많은 데이터에서 이미지를 보다 정확하고 효율적으로 분류할 수 있다. CLIP이 다른 점은 시각적 분류를 위한 대부분의 기존 모델처럼 큐레이트 된 데이터 세트의 이미지를 인식하지 못한다는 것이다.
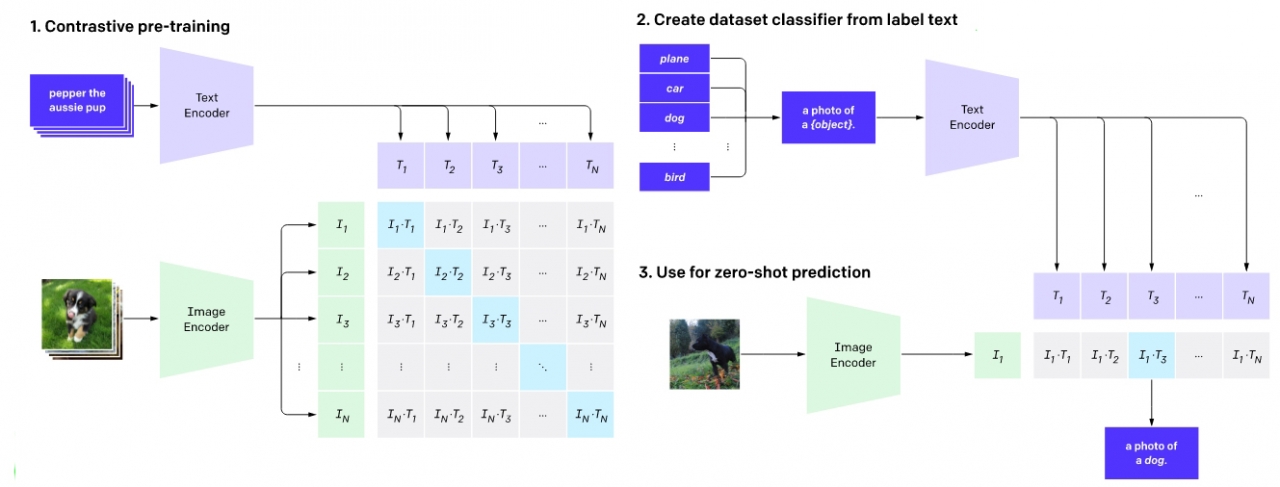
CLIP는 인터넷에서 이용할 수 있는 다양한 자연어 감독(Supervision)에 대해 훈련되었다. 따라서 CLIP은 데이터 세트에서 레이블이 지정된 단일 단어가 아닌 그림에 상세한 설명이 있는 것을 학습한다. 그러나 일부에서는 이 모델이 웹에서 이미지를 가져와 자체적으로 생성하기 때문에 저작권 문제에 대한 의문도 제기됐다.
CLIP는 인식할 시각적 범주의 이름을 제공함으로써 모든 시각적 분류 벤치 마크에 적용될 수 있다. 특히, 이 신경망은 자연어처리에서 시각적인 개념을 효율적으로 학습한다. GPT-2 및 GPT-3의 '제로샷 러닝(Zero-shot Learning- 참고)' 기능과 유사한 벤치 마크 성능을 직접 최적화하지 않고도 매우 다양한 분류 벤치 마크를 수행하도록 자연어로 지시할 수 있다.
한편, GPT-3에 이은 이번 DALL·E, CLIP와 같은 모델도 역시 상당한 사회적 영향을 미칠 수 있다. OpenAI는 이러한 모델이 특정 직업에 대한 경제적 영향, 모델 출력의 편향 가능성 및 이 기술에 의해 암시되는 장기적인 윤리적 도전과 같은 사회적 문제와 어떻게 관련되는지 분석할 것이라고 밝혔다. 이번 개발된 AI 두 모델 DALL·E, CLIP의 더 자세한 내용은 연구 논문 '자연어 감독으로부터 전달 가능한 시각적 모델 학습(Learning Transferable Visual Models From Natural Language Supervision- 다운)'과 공개된 코드는 깃허브(다운)를 참고하면 된다.
관련기사
- 대형 자연어처리 모델의 윤리적인 AI 논란 속... 구글, 애플-오픈AI와 공동 연구 발표
- GPT-3, 왜 요금제를 선택했으며... 마이크로소프트에 독점 라이선스를 부여했나?
- GPT-3... 휼륭하지만 '다섯 가지' 한계를 짚어본다
- 세계 정상급 AI 전문가들 모인 '오픈 AI'에 입사하는 UNIST 출신 김태훈 청년의 포부
- GPT-3는 과연 얼마나 똑똑한 것일까?
- 테슬라 일론 머스크, 오픈AI... 마이크로소프트에 GPT-3 독점 라이선스 부여한 것! 공개 비판
- OpenAI, GPT-3 언어 모델... 마이크로소프트, 독점 라이선스 확보
- [영상] 초보자도 쉽게 GPT-3를 사용해 혼자서 GPT-3 모델을 구현한다
- GPT-3, 인류 역사상 가장 뛰어난 '언어 인공지능'이다
- [이슈] OpenAI, 혁신적인 AI 자연어처리(NLP) 모델 'GPT-3' 공개
- [AI 리뷰] 계층 구조로서의 예측... 미래를 예측하는 'AI 프레임워크' 오픈소스로 공개
- [AI 리뷰] 질병 치료 위한 최상의 약물 조합... 혁신적으로 추론하는 인공지능 모델 오픈 소스로 공개!
- [이슈] GPT-3 넘었다!... 화웨이, 2천억개 매개변수의 초거대 언어 AI 모델 '판구 알파' 공개
- 페이스북 AI, 한국어 포함한 전 세계 101개국 언어... 다대다 데이터 세트 '플로레스-101' 오픈 소스로 공개
- 현존하는 초거대 언어 인공지능 모델 ‘GPT-3’ 애저에 개방!...마이크로소프트, 애저 오픈AI 서비스 발표