전 세계 수십억 명의 사람들이 지식 격차와 문화의 차이, 그리고 자유롭게 소통하는 데 있어 근본적인 언어의 장벽을 허물고 사람들을 더 가깝게... AI 연구자 및 개발자들이 좀 더 다양한 (그리고 지역적으로 관련이 있는) 번역 도구를 만들 수 있도록

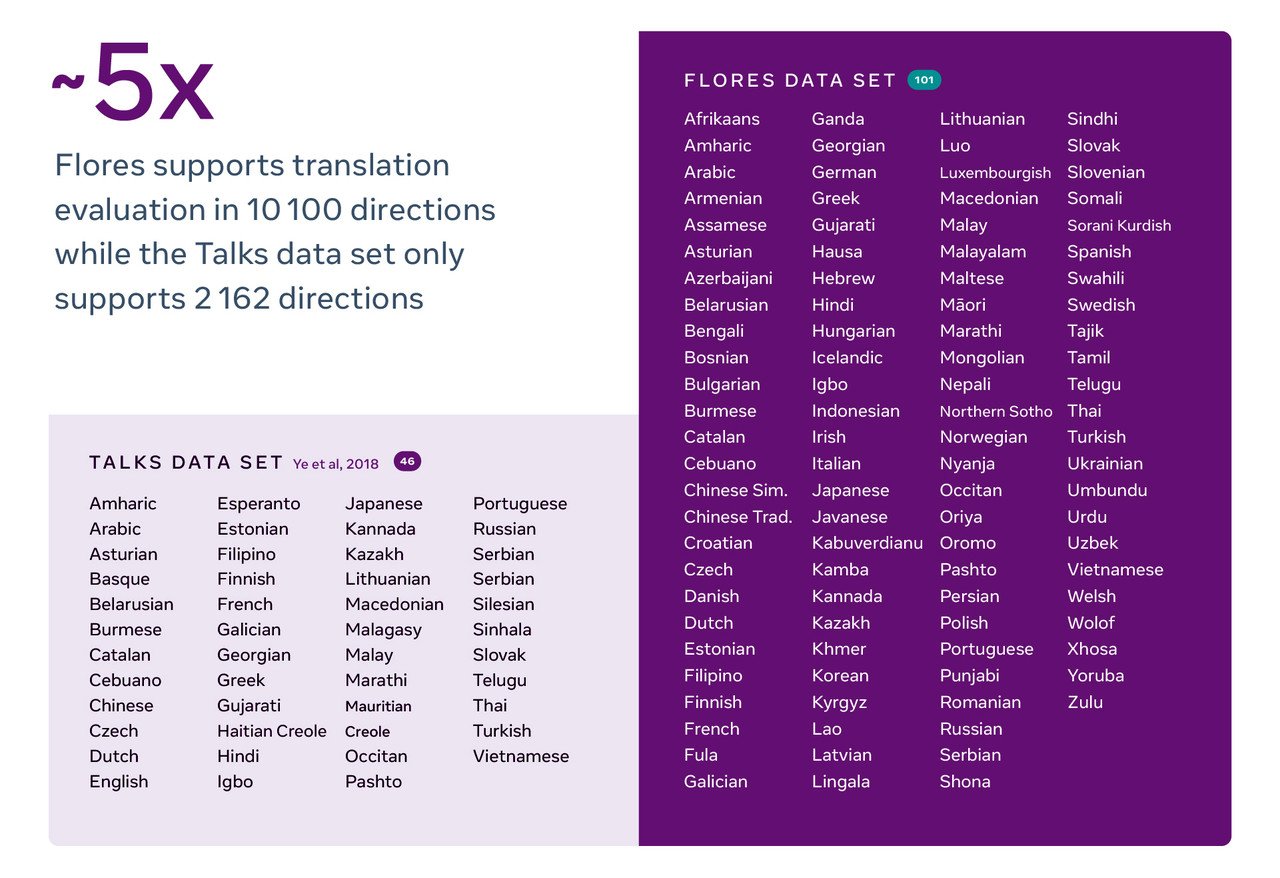
한국어, 일본어를 포함한 전 세계의 101 개국의 언어를 다루는 세계 최초의 다대다(Many-To-Many) 데이터 세트 인 '플로레스-101(FLORES-101)'을 페니스북 AI 연구소(FAIR)가 4일(현지시간) 오픈 소스로 공개했다.
플로레스-101은 연구자들이 다국어 번역 모델을 신속하게 테스트하고 개선할 수 있다.
페이스북 AI 연구소는 지식 격차와 문화의 차이, 언어의 장벽을 허물고 사람들을 더 가깝게 만드는 것 위해 누구나 사용할 수 있게 플로레스-101을 공개했다. 이를 통해 AI 연구자 및 개발자들이 좀 더 다양한 (그리고 지역적으로 관련이 있는) 번역 도구를 만들 수 있도록 하는 것을 의미한다.
예를 들어, 벵골에(Bengali)에서 인도 서부 마하라슈트라(Maharashtra)에서 사용하는 언어 마라티어(Marathi)로 번역하는 것이 영어에서 스페인어로 번역하는 것만큼 쉽도록 만들 수 도 있다.

번역 시스템이 얼마나 잘 수행되는지 성능을 평가하는 것은 AI 연구자들에게 중요한 과제였다. 연구자가 결과를 측정하거나 비교할 수 없다면 더 나은 번역 시스템을 개발할 수 없기 때문이다.
그동안 AI 연구 커뮤니티는 다대다 번역 모델 성능의 고품질, 신뢰성 있는 측정을 수행한 후 다른 것과 결과를 비교할 수 있는 개방적이고 쉽게 접근할 수 있는 방법이 필요했다.
이 문제에 대한 이전 작업은 종종 독점 데이터 세트를 사용하여 영어 안팎으로 번역하는 데 크게 의존했다. 그러나 이것이 영어 사용자에게 도움이 되었지만 사람들이 지역 언어 간의 빠르고 정확한 번역을 필요로 하는 세계의 많은 지역, 예를 들어 헌법이 20 개 이상의 공식 언어를 인정하는 인도에서는 충분하지 않았다.
플로레스-101는 현재, 자연어 처리(NLP) 연구를 위한 광범위한 데이터 세트가없는 에티오피아의 지배층의 암하라어(Amharic), 몽골어(Mongolian), 우르두어(Urdu)와 같은 언어에 중점을 두었다.
처음으로 연구자들은 10,100 개의 서로 다른 번역 방향(예: 힌디어에서 태국어 또는 스와힐리어로 직접)을 통해 번역의 품질을 안정적으로 측정할 수 있다. 문맥 상, 영어 안팎으로 평가하면 200 개의 번역 방향만 제공된다.
번역에서 좋은 벤치마크는 구축하기 어렵다. 이들은 모델 간의 의미 있는 차이를 정확하게 반영할 수 있어야 연구자들이 결정을 내리는 데 사용할 수 있다. 번역자가 더 쉽게 이용할 수 있는 소수의 선택자가 아니라 모든 언어에 걸쳐 동일한 품질 표준을 충족해야 하기 때문에 특히 어려울 수 있다.
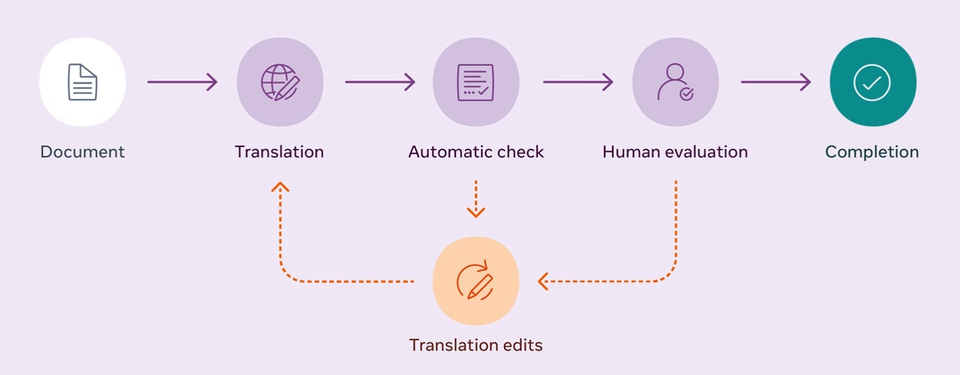
이를 위해 다단계 워크플로에서 플로레스-101 데이터 세트를 생성했다. 각 문서는 전문 번역가가 먼저 번역한 후, 인간 편집자가 검증했다. 다음으로, 철자, 문법, 구두점, 서식에 대한 검사와 상용 엔진의 번역과의 비교를 포함한 품질 관리 단계로 진행됐다.
그 후, 다른 번역자들이 인간 평가를 수행하여 부자연스러운 번역, 등록 및 문법을 포함한 수많은 범주의 오류를 식별했다. 확인된 오류의 수와 심각도에 따라 번역은 재번역을 위해 반송되거나 품질 표준을 충족하는 경우 번역이 완료된 것으로 간주됐다.
카네기멜론대학교(Carnegie Mellon University) 언어 기술 연구소의 그레이엄 노이빅(Graham Neubig) 교수는 "플로레스-101은 기계 번역 커뮤니티 내에서 많은 언어의 표현을 개선하는 데 도움이되는 정말 흥미로운 리소스라고 생각합니다"라며, "이것은 위키백과(Wikipedia) 텍스트와 같은 정보 액세스와 관련된 영역에서 전 세계의 수많은 언어를 다루는 가장 광범위한 리소스 중 하나입니다"라고 말했다.
페이스북 AI 연구소는 플로레스-101 데이터 세트를 오픈 소스로 제공하는 것은 이제 시작에 불과하며, 연구원들이 지난해 10월 오픈 소스로 공개한 영어 데이터에 의존하지 않고 100 개국 언어를 번역하는 최초의 AI 모델 인 M2M-100(다운)과 같은 다국어 번역 모델에 대한 작업을 가속화하고 특히, 더 많은 언어로 번역 모델을 개발할 수 있기를 바란다고 밝혔다.
전 세계 수십억 명의 사람들, 특히 비영어권 사용자에게 언어는 정보에 접근하고 다른 사람들과 자유롭게 소통하는 데 있어 근본적인 장벽으로 남아 있지만 지난 몇 년 동안 이번, 페니스북 AI 연구소(FAIR) 등과 같은 곳에서 기계 번역이 크게 발전했지만 이러한 노력으로 인해 소수의 언어가 가장 많은 혜택을 얻었다.
한편, 이번 연구 결과는 지난 1월 '저 자원 및 다국어 기계 번역을 위한 FLORES-101 평가 벤치마크(The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation-다운)'이라 제목의 논문으로 발표했다. 현재, 플로레스-101 데이터 세트는 페이스북 깃허브(다운)를 통해 누구나 사용할 수 있다.
관련기사
- [이슈] “인공지능 시대 이끌 것!”... 네이버, '초대규모 AI' 한국어 언어모델 ‘하이퍼클로바’ 공개
- [칼럼] 인공지능 시대의 접점에서... 사람만큼, 놀랍게 진화하는 'AI 언어' 모델
- 업스테이지, 한국어 기반 AI모델 공정 평가 위한 ‘한국어 자연어 이해 평가 데이터셋(KLUE)’ 공개한다
- [이슈] GPT-3 넘었다!... 화웨이, 2천억개 매개변수의 초거대 언어 AI 모델 '판구 알파' 공개
- 인간처럼 코드를 추론할 수 있는 인공지능 모델의 여정과 도전!
- 국립국어원-SKT, 인공지능 한국어 모델 개발한다... GPT-3와 버금가는 1,500억개 매개변수 가진 거대 언어 모델로
- [AI 리뷰] 페이스북 AI, 다국어 음성 AI 개발 위한 '8개 언어, 5만시간 오디오 세트' 오픈 소스로 공개
- 구글 AI, 말하기 쓰기 명령에 인간 시각에 대응하고 식별하는 에이전트 오픈 소스로 공개
- [AI 리뷰] 오픈AI, 글 쓰는 GPT-3에서 진화... 텍스트 읽고 그림 그리는 AI 모델 'DALL·E' 및 'CLIP' 공개
- 대형 자연어처리 모델의 윤리적인 AI 논란 속... 구글, 애플-오픈AI와 공동 연구 발표
- 텍스트 없는 자연어처리?... 음성 인공지능 NLP 시대 열어, 페이스북 AI ‘생성적 화자 언어 모델’ 오픈 소스로 공개
- [스페셜리포트] 101개국 구어와 문어, 실시간 번역하는 메타AI의 혁신적인 인공지능과 데이터셋 오픈소스로 공개
- [AI 리뷰] 메타 AI, 초거대 인공지능 언어모델 ...1750억개 매개변수의 'OPT-175B' 오픈소스로 공개