MIT 맥거번 뇌 연구소 '조쉬 맥더모트' 교수, "이제 이러한 유형의 모델링을 음높이 인식(Pitch Perception) 및 음성 인식과 같은 다른 측면에 적용할 수 있으며 사람이 주의를 기울이거나 기억할 수 있는 한계와 같은 다른 인지 현상을 이해하는 데에도 사용될 수 있다"...

인간의 두뇌는 특정 소리를 인식할 뿐만 아니라 소리가 나는 방향을 인지하도록 미세 조정된다. 즉, 뇌는 오른쪽 귀와 왼쪽 귀에 도달하는 소리의 차이를 비교하여 개가 짖는 소리, 소방차의 사이렌 소리 또는 다가오는 자동차의 소리 등으로 객체의 위치를 추정할 수 있다.
인간의 귀는 외이, 중이, 내이의 세 부분으로 이루어졌으며, 외이(外耳)의 한 부분으로 소리를 모으는 역할과 다양한 크기와 모양을 가지고 있는 귓바퀴는 공기와 중이(中耳) 사이에서 소리의 에너지를 점차 좁아지는 귓속으로 모으는 음파의 임피던스 매치 역할을 한다. 이 흐름으로 인해 청신경(聽神經)을 통해 뇌로 전달되는 전기 신호가 만들어진다.
뇌는 이 신호를 분석하여 소리를 인식하는 것이다. 특히, 중뇌의 일부는 이러한 차이를 비교하여 소리가 나오는 방향을 추정하는 데 도움이 되도록 특수화되어 있다. 이 과정을 현지화(localization)라고도 한다. 그러나 이 과정은 환경이 메아리(반향, echo)를 생성하고 한 번에 많은 소리가 들리는 실제 조건에서 훨씬 더 어려워진다.
여기에, MIT 신경과학자들은 인공지능(AI)을 통해 그 복잡한 작업도 불구하고 소리로 객체의 위치를 추정할 수 있는 AI 모델을 개발했다. 다수의 컨볼루션 네트워크(합성곱 신경망, Convolutional Neural Networks. 이하, CNN)으로 구성된 이 모델은 인간처럼 작업을 수행할 뿐만 아니라 인간이 소리의 위치를 파악하는 것과 같은 방식으로 진행된다.
이 연구를 주도한 MIT 뇌 및 인지과학부 교수이자 MIT 맥거번 뇌 연구소(McGovern Institute for Brain Research at MIT) 조쉬 맥더모트(Josh McDermott) 박사는 "이제 우리는 실제 세계에서 소리를 실제로 현지화할 수 있는 모델을 갖게 되었습니다"라며, "또한 이 새로운 연구의 결과는 위치를 인식하는 인간의 능력이 우리 환경의 특정 문제에 적응한다는 것도 시사합니다"라고 밝혔다.
그동안 많은 과학자들은 뇌가 소리의 위치를 파악하는 데 사용하는 것과 같은 연산을 수행할 수 있는 컴퓨터 모델을 구축하기 위해 오랫동안 노력해왔다. 그러나 모델은 때때로 배경 소음이 없는 이상적인 설정에서 잘 작동하지만 소음과 반향이 있는 실제 환경에서는 결코 작동하지 못했다.
연구팀은 보다 정교한 현지화 모델을 개발하기 위해 CNN으로 눈을 돌렸다. 신경망은 다양한 아키텍처로 설계할 수 있으므로 현지화에 가장 적합한 아키텍처를 찾을 수 있도록 약 1,500개의 서로 다른 모델을 훈련하고 테스트할 수 있는 슈퍼컴퓨터를 사용했다. 그 결과 현지화에 가장 적합한 것으로 보이는 10개를 식별했으며, 이를 추가로 훈련하고 모든 후속 연구에 사용했다.
이 모델들을 훈련시키기 위해, 연구팀은 방의 크기와 방 벽의 반사 특성을 조절할 수 있는 가상 세계를 만들었다. 모델들에게 전달되는 모든 소리는 이 가상의 방들 중 어딘가에서 비롯되었다. 400 개가 넘는 학습 소리 데이터 세트에는 인간의 목소리, 동물의 소리, 자동차 엔진과 같은 기계 소리 및 천둥과 같은 자연스러운 소리가 포함되었다.
그런 다음 연구팀은 과학자들이 과거에 인간의 위치 파악 능력을 연구하는 데 사용한 일련의 테스트를 모델에 적용했다. 귓바퀴에는 소리를 반사하는 많은 주름이 있어 귀에 들어오는 주파수를 변경하며 이러한 반사를 통해 소리가 어디에서 오는지에 따라 다르기 때문이다.
연구팀은 모델에 소리가 입력되기 전에 특수 수학적 기능을 통해 각 소리를 실행하여 이 효과를 시뮬레이션 했다. 이를 통해 모델에 사람이 가질 수 있는 것과 동일한 종류의 정보를 제공할 수 있었다.
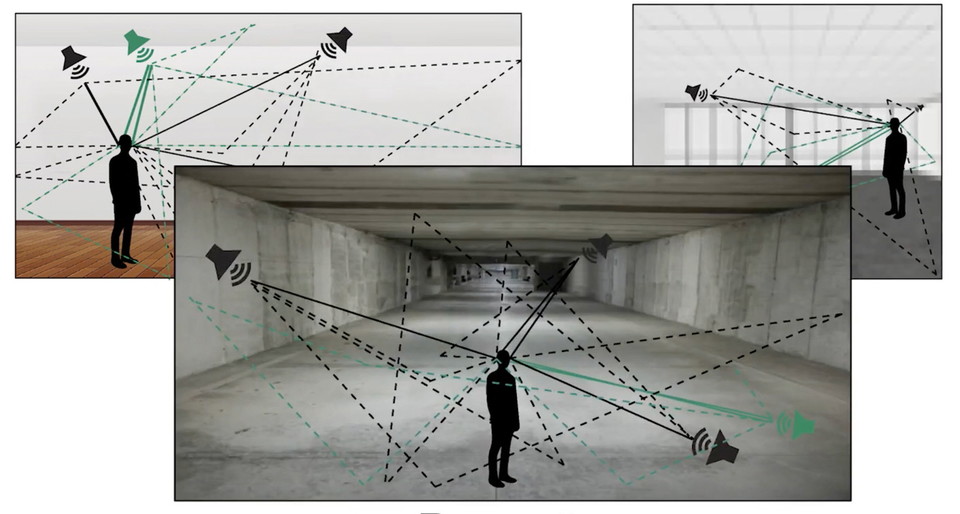
또한, 연구팀은 모델을 훈련시킨 후 실제 환경에서 모델을 테스트했다. 그들은 실제 방에 귀에 마이크가 부착된 마네킹을 배치하고 다른 방향에서 소리를 재생한 다음 해당 녹음을 모델에 제공했다. 모델은 이러한 소리를 현지화하라는 요청을 받았을 때 인간과 매우 유사하게 수행되었다.
연구팀의 이전 연구'(심층신경망 모델은 음높이 인식에서 주변 코딩 및 자극 통계에 의한 상호 작용/Deep neural network models reveal interplay of peripheral coding and stimulus statistics in pitch perception-다운)'를 성공적으로 이끈 것은 들어오는 소리의 주파수에 따라 다르다는 것을 확인해 준 것이다.
연구팀은 이번 연구에서 모델이 주파수에 대해 이와 동일한 패턴의 감도를 나타냄을 확인했으며, 이 모델은 사람들이 하는 것과 같은 방식으로 두 귀 사이의 타이밍과 레벨 차이를 주파수에 의존하는 방식으로 작용했다.
또한 연구팀은 에코가 없는 가상 세계에서 한 세트의 모델을 훈련하고 한 번에 한 가지 이상의 소리가 들리지 않는 세계에서 다른 모델을 훈련했다. 모델은 자연적으로 발생하는 소리 대신 좁은 주파수 범위의 소리에만 노출되었다.
이러한 부자연스러운 세계에서 훈련된 모델을 일련의 동일한 행동 테스트에서 평가했을 때, 모델은 인간의 행동에서 벗어났고, 실패하는 방식은 훈련된 환경의 유형에 따라 달랐다. 이러한 결과는 인간 두뇌의 위치 파악 능력이 인간이 진화한 환경에 적응했다고 말한다.
조쉬 맥더모트 교수는 "이제 이러한 유형의 모델링을 음높이 인식(Pitch Perception) 및 음성 인식과 같은 다른 측면에 적용할 수 있으며 사람이 주의를 기울이거나 기억할 수 있는 한계와 같은 다른 인지 현상을 이해하는 데에도 사용될 수 있다고 믿습니다"라고 밝혔다.
한편, 이 연구 결과는 사회 및 자연과학 전반에서 인간 행동에 대한 최고의 국제연구학술지 ‘네이처 휴먼 비헤이비어(Nature Human Behavior)’에 심층 신경망 모델이 실제 환경에서 소리 위치 파악의 인식(Deep neural network models of sound localization reveal how perception is adapted to real-world environments-다운)‘지난 27일 게재됐다. (아래 동영상은 소리 위치를 파악하는 심층 신경망 모델이 실제 환경에 어떻게 적용되는지 보여준다.)