GNN을 평가하기 위한 방법과 데이터 세트는 훨씬 덜 주목 받았다. 많은 GNN 연구에서는 동일한 5-10개의 벤치마크 데이터 세트를 재사용하며, 대부분은 쉽게 레이블이 지정된 학술 인용 네트워크와 분자 데이터 세트로 구성된다. 이는 새로운 GNN 변형의 경험적 성능이 제한된 그래프 클래스에 대해서만 주장할 수 있음을 의미한다.

그래프Graph)는 자료의 정량적 성향에 대한 일반적인 경향을 보여주는 예측이나 소셜 네트워크, 교통 인프라, 분자 및 인터넷과 같은 관계 구성 요소를 연결하는 자연 시스템의 매우 일반적인 표현이다.
그래프 신경망(Graph Neural Networks. 이하, GNN)은 그래프 또는 전체 그래프 내의 항목에 대한 예측에 컨텍스트를 통합하기 위해 고유한 연결을 활용하는 강력한 머신러닝(ML) 기법이다. GNN은 신약을 발견하고, 수학자들이 계산 및 수식을 증명하도록 돕고, 잘못된 정보를 감지하고, 지도에서 특정지역의 도착 시간 예측 등에서 정확도를 개선하는 등 다양한 분야에서 효과적으로 사용되고 있다.
지난 10년 동안 GNN에 대한 관심의 급증으로 수천 개의 GNN 변형 모델이 생성되었으며 매년 수백 개가 도입되고 있다.
대조적으로, GNN을 평가하기 위한 방법과 데이터 세트는 훨씬 덜 주목받았다. 많은 GNN 연구에서는 동일한 5-10개의 벤치마크 데이터 세트를 재사용하며, 대부분은 쉽게 레이블이 지정된 학술 인용 네트워크와 분자 데이터 세트로 구성된다. 이는 새로운 GNN 변형의 경험적 성능이 제한된 그래프 클래스에 대해서만 주장할 수 있음을 의미한다.
최근 GNN 벤치마킹에 대한 워크샵 및 국제학회 트랙에서 이러한 문제를 다루기 시작했으며, 오픈소스로 공개된 OGB(Open Graph Benchmark-다운)는 그래프 머신러닝을 위한 벤치마크 데이터 세트, 데이터 로더 및 평가자의 모음으로 데이터 세트는 다양한 그래프 머신러닝 작업과 실제 애플리케이션을 다룬다.
OGB 데이터 로더는 파이토치(PyTorch) 기하학 및 심층그래프 라이브러리(DGL, Deep Graph Library-다운)를 포함하여 널리 사용되는 그래프 딥러닝 프레임워크와 완벽하게 호환되며, 자동 데이터 세트 다운로드, 표준화된 데이터 세트 분할 및 통합 성능 평가를 제공한다.
OGB는 중요한 그래프 머신러닝 작업과 다양한 데이터 세트 규모 및 풍부한 영역을 포괄하는 그래프 데이터 세트를 제공하는 것을 목표로 한다. 그러나, OGB 데이터 세트는 인용 및 분자 네트워크와 같은 기존 데이터 세트와 동일한 많은 도메인에서 제공되고 있다. 이것은 OGB가 데이터 세트 다양성 문제를 해결하지 못한다는 것을 의미한다.
여기에, 구글 AI는 GNN 연구 커뮤니티가 실제 세계에서 볼 수 있는 큰 통계적 편차가 있는 그래프를 실험하여 혁신을 따라갈 수 있는지에 대해 의문을 제기했다. 학술 문헌에 등장하는 GNN 벤치마크 데이터세트가 잠재적인 그래프의 완전히 다양한 '세계'의 개별 '위치'인 반면, 구글AI 연구팀은 확률 모델을 사용하여 이 세계를 직접 생성하고 모든 위치에서 GNN 모델을 테스트하고 일반화 가능한 통찰력을 추출했다.
그 결과, 학술 데이터 세트에서 다루지 않는 그래프 공간 영역에서 GNN 성능을 탐색할 수 있도록 하는 보완적이며, GNN 연구의 규모와 속도에 맞추기 위해 수백만 개의 합성 시스템에서 GNN 아키텍처의 성능을 분석하는 벤치마크로 '그래프월드(GraphWorld)'를 개발하고 오픈소스로 공개했다.
그래프월드는 대규모 OGB 데이터 세트에 대한 하나(DEEPER BIGGER BETTER FOR OGB-LSC AT KDD CUP 2021-다운)의 실험 보다 적은 계산 비용으로 합성 데이터에 대한 수십만 개의 GNN 실험을 간편하게 실행하는 비용 효율적인 것으로 나타났다.
GNN 벤치마크 데이터 세트의 제한된 다양성
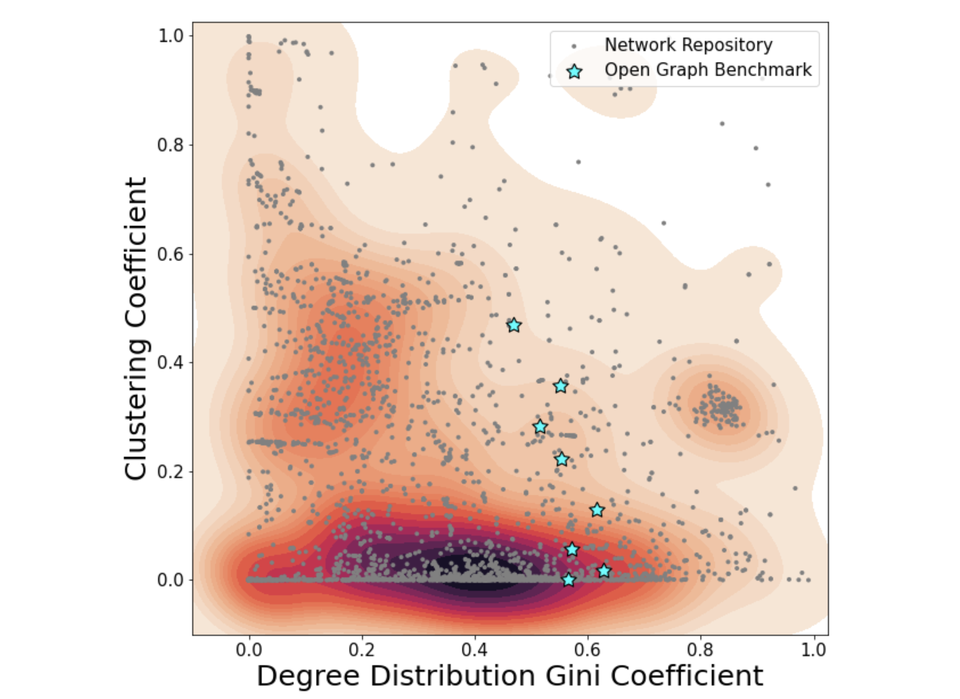
그래프월드에 대한 동기를 설명하기 위해 구글 AI 연구팀은 OGB 그래프를 실시간 시각적 분석 기능을 갖춘 최초의 대화형 데이터 및 네트워크 데이터 리포지토리인 네트워크 리포지토리(Network Repository) 보다 훨씬 더 큰 그래프 모음(5,000개 이상)과 비교했다. 대부분의 네트워크 리포지토리 그래프는 레이블이 지정되지 않아 일반적인 GNN 실험에서 사용할 수 없지만, 실제 세계에서 사용할 수 있는 넓은 공간의 그래프를 나타낸다.
또한, 연구팀은 OGB 및 네트워크 리포지토리 그래프의 두 가지 속성을 계산했다. 클러스터링 계수(연결된 노드가 인접한 이웃에 대해 어떻게 연결되는지) 및 정도 분포 지니 계수(gini coefficient, 노드의 연결 수 간의 불평등)로 OGB 데이터 세트가 이 메트릭 공간의 제한적이고 밀도가 낮은 지역에 존재한다는 것을 발견했다.
그래프월드의 데이터 세트 생성기
그래프월드를 사용하여 주어진 과제에 대한 GNN 성능을 조사하는 사용자는 먼저 과제에 대한 GNN 모델을 스트레스 테스트하기 위한 그래프 데이터 세트를 생성할 수 있는 매개 변수화된 생성기를 선택한다.
생성기 매개변수는 출력 데이터 세트의 상위 수준 기능을 제어하는 입력으로 그래프월드는 매개 변수화 된 생성기를 사용하여 최첨단 GNN 모델의 한계를 테스트하기에 충분히 다양한 그래프 데이터 세트의 모집단을 생성한다. 예를 들어, GNN의 인기 있는 작업은 노드 분류이다.
여기서, GNN은 소셜 네트워크의 사용자 관심과 같이 각 노드의 알려지지 않은 속성을 나타내는 노드 레이블을 추론하도록 훈련된다.
구글 AI 연구팀의 논문(그래프월드: 가짜 그래프는 GNN에 대한 실제 통찰력을 제공한다./GraphWorld: Fake Graphs Bring Real Insights for GNNs-다운)에서는 이 작업을 위한 데이터 세트를 생성하기 위해 잘 알려진 '확률적 블록 모델(SBM, Stochastic Block Mode-다운)'을 선택했다.
SBM은 먼저 미리 설정된 수의 노드를 분류할 노드 레이블 역할을 하는 그룹 또는 '클러스터(설명)'로 구성한다. 그런 다음, 결과 그래프의 서로 다른 속성을 제어하는 다양한 매개변수에 따라 노드 간의 연결을 생성한다.
그래프월드에 노출하는 SBM 매개변수 중 하나는 클러스터의 '호모필리(Homophily. 同種愛-동종애, 同質性-이하, 동질성)'으로, 동일한 클러스터의 두 노드가 연결될 가능성을 제어한다(다른 클러스터의 두 노드에 상대적). 동질성은 소셜 네트워크에서 흔히 볼 수 있는 현상이다. 비슷한 관심사를 가진 사용자(예, SBM 클러스터)가 연결될 가능성이 더 높다.
그러나, 모든 소셜 네트워크가 동일한 수준의 동질성을 가지는 것은 아니다. 그래프월드는 SBM을 사용하여 동질성이 높은 그래프(왼쪽 아래), 동질성이 낮은 그래프(오른쪽 아래), 동종성 수준이 중간에 있는 수백만 개 이상의 그래프를 생성한다.
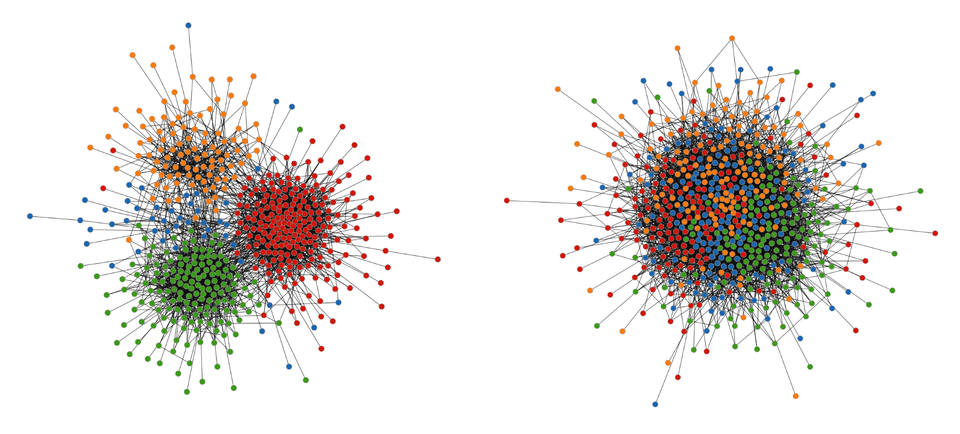
이를 통해 사용자는 다른 연구자들이 선별한 실제 데이터 세트의 가용성에 의존하지 않고 모든 수준의 동질성을 가진 그래프에서 GNN 성능을 분석할 수 있는 것이다.
그래프월드 실험 및 통찰력
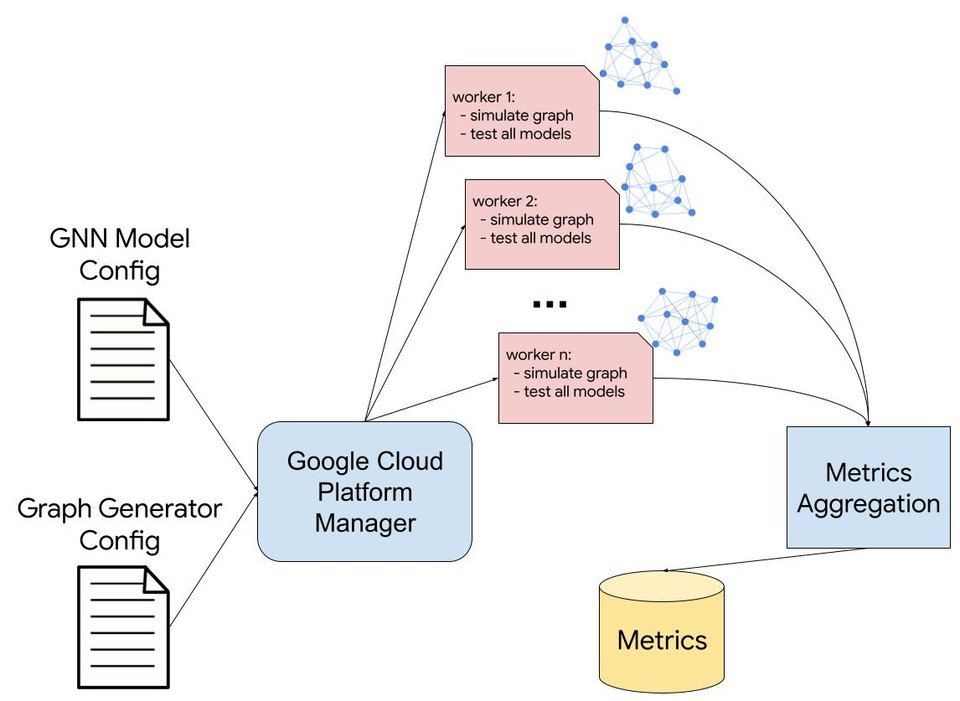
그래프월드는 해당 작업에 대한 작업 및 매개 변수화 된 생성기가 주어지면 병렬 컴퓨팅(예, Google Cloud Platform Dataflow-보기)을 사용하여 생성기 매개변수 값을 샘플링하여 GNN 벤치 마크 데이터 세트의 세계를 생성한다.
동시에 그래프월드는 각 데이터 세트에서 임의의 GNN 모델 목록[예, GCN(Semi-Supervised Classification with Graph Convolutional Networks-다운), GAT(Graph Attention Networks-다운), GraphSAGE(Inductive Representation Learning on Large Graphs-다운)]을 테스트 한 다음 GNN 성능 결과와 함께 그래프 속성을 결합하는 방대한 표 형식 데이터 세트를 출력한다.
또한, 연구팀의 논문에서는 노드 분류, 링크 예측 및 그래프 분류 작업을 위한 그래프월드 파이프라인을 설명하며, 각각은 서로 다른 데이터 세트 생성기를 특징으로 한다. 각 파이프라인이 OGB 그래프에 대한 실험 보다 시간과 계산 리소스가 덜 소요된다는 것을 학인할 수 있다.
아래 사진에서는 그래프월드 노드 분류 파이프라인의 GNN 성능 데이터를 시각화한다(SBM을 데이터세트 생성기로 사용). 그래프월드의 영향을 설명하기 위해 먼저 고전적인 학술적 그래프 데이터 세트를 클러스터 동질성(x 축)과 각 그래프 내 노드 정도의 평균(y 축)을 측정하는 x - y 평면에 매핑한다(산점도와 유사 그 위에는 OGB 데이터 세트가 포함되지만 측정값은 다르다).
그런 다음, 그래프월드의 각 시뮬레이션된 그래프 데이터 세트를 동일한 평면에 매핑하고 각 데이터 세트에 대한 GNN 모델 성능을 측정 하는 세 번째 z 축을 추가한다. 특히, 특정 GNN 모델(예: GCN 또는GAT ), z 축은 논문에서 평가된 13개의 다른 GNN 모델에 대한 모델의 평균 역순위를 측정한다. 여기서 1에 가까울수록 모델이 노드 분류 정확도 측면에서 최고 성능에 가깝다는 의미다.

위 사진은 두 가지로 관련 결론을 보여준다. 첫째, 그래프월드는 표준 데이터 세트가 다루는 영역을 훨씬 넘어 확장되는 그래프 데이터 세트의 영역을 생성한다. 둘째, 가장 중요한 것은 그래프가 학문적 벤치마크 그래프와 다를 때 GNN 모델의 순위가 변경된다는 것이다.
특히, Cora(Collective Classification in Network Data-다운) 및 CiteSeer와 같은 클래식 데이터 세트의 동질성 노드가 클래스에 따라 그래프에서 잘 분리되어 있음을 의미한다. 구글AI 연구팀은 GNN이 덜 동질적인 그래프의 공간으로 이동함에 따라 순위가 빠르게 변한다는 것을 확인했다.
예를 들어, GCN의 비교 평균 역수 순위는 학문적 벤치마크 영역에서 더 높은 값(위 사진: 녹색)에서 해당 지역에서 더 낮은 값(빨간색)으로 이동한다. 이것은 그래프월드가 학문적 벤치마크가 제공하는 소수의 개별 데이터 세트만으로는 보이지 않는 GNN 아키텍처 개발의 중요한 이유를 드러낼 잠재력이 있음을 보여줬다.
결론적으로 구글 AI의 그래프월드는 연구 및 개발자들이 그래프 데이터 세트의 고차원 표면에서 새로운 모델을 확장 가능하게 테스트할 수 있도록 함으로써 GNN 실험의 새로운 지평을 연 것이다.
이를 통해 그래프월드 데이터 세트에서 개별 포인트로만 나타나는 OGB와 Cora와 유사한 그래프에서 멀리 떨어져 있는 그래프의 전체 부분 공간에 대한 그래프 속성에 대해 GNN 아키텍처를 세밀하게 분석할 수 있다. 그래프월드의 주요 기능은 저렴한 비용으로 기관 리소스에 액세스할 수 없는 개별 사용자가 새 모델의 경험적 성능을 신속하게 이해할 수 있도록 한다.
한편, 그래프월드 사용자는 보다 미묘한 GNN 실험을 위한 새로운 무작위 / 생성 그래프 모델(그래프 신경망 사전 훈련 전략/Strategies for Pre-training Graph Neural Networks-다운)을 조사하고 잠재적으로 GNN 사전 훈련을 위해 그래프월드 데이터 세트를 사용할 수 있으며, 그래프월드 리포지토리(다운)는 오픈소스로 공개돼 있다.