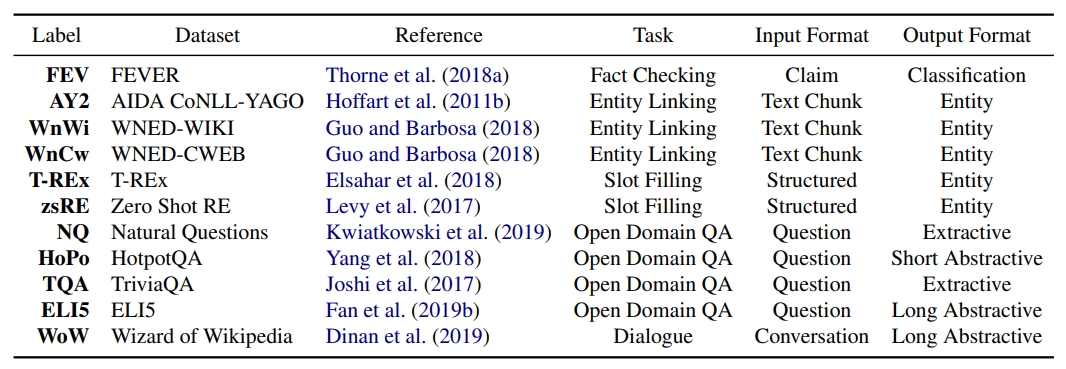
사실 확인(Fact-checking), 오픈 도메인 질문 답변(Open domain QA), 슬롯 채우기(Slot filling), 엔터티 연결(Entity linking) 및 대화 생성(Dialog generation) 등 5 개의 개별 작업에 걸친 11 개의 데이터 세트로 구성

페이스북 AI이 실제 지식을 더 잘 활용할 수있는 모델을 구축할 수 있도록 지식 집약적 언어 작업(KILT) 통합 벤치 마크를 최근 발표했다.
이 '지식 집약적 언어 작업(Knowledge Integrated Language Tasks. 이하, KILT)'는 11개의 데이터 세트를 단일 형식으로 통합하고 이를 전체 위키백과(Wikipedia) 말뭉치(Corpus)의 사전 처리된 단일 컬렉션에 근거를 둔다. 즉, KILT의 모든 데이터 세트가 위키백과의 전체 내용을 스냅샷으로 배열하여 하나의 지식원 역할을 하는 것이다. 모든 데이터 세트를 단일 소스에 매핑하는 것은 이 분야에서 연구 작업을 훨씬 더 편리하게 만들며, 또한 다른 모델에 걸쳐 더 정확하고 균형 잡힌 평가를 가능하게 한다.
페이스북 AI 연구팀은 "모델이 지식 기반 작업에서 어떻게 수행되는지 평가할 때 특정 출력뿐만 아니라 이를 생성하는 데 사용되는 특정 정보도 고려하는 것이 중요하며, KILT 벤치 마크에는 출처 정보 또는 매핑이 포함된다. 작업을 해결할 수 있는 정확한 지식과 여러 작업에 대해 주석 캠페인을 통해 출처 주석을 보다 포괄적으로 만든다. 또 출력값과 검증값을 함께 사용하면 연구자들은 모델의 정확성과 모델 예측을 정당화하는 능력을 평가할 수 있다"고 연구 논문 'KILT: 지식 집중 언어 과제를 위한 벤치 마크(KILT: a Benchmark for Knowledge Intensive Language Tasks-다운)을 통해 밝혔다.
KILT 벤치 마크는 사실 확인(Fact-checking), 오픈 도메인 질문 답변(Open domain QA), 슬롯 채우기(Slot filling), 엔터티 연결(Entity linking) 및 대화 생성(Dialog generation) 등 5 개의 개별 작업에 걸친 11 개의 데이터 세트로 구성되며 고려되는 모든 데이터 세트에 대한 테스트 세트를 포함한다.
이와 함께, 페이스북 AI 연구팀은 대부분의 검색 기준에 대한 다중 프레임 워크 커넥터가 있는 킬트 라이브러리(The KILT Library)를 오픈소스(다운)로 공개하고 라이브러리에 기준선과 사전 훈련 된 모델을 계속 추가할 것이며, 다른 모듈 구성 요소를 상호 교환하고 실험하는 논리도 추가 할 것이라고 밝혔다.