콜롬비아 대학의 이 AI 모델은 레이블이 없는 비디오 데이터를 사용하여 구축되었다. 그들의 접근 방식은 예측할 기능을 미리 확인하는 대신 어떤 기능이 예측 가능한지 데이터에서 학습한다.
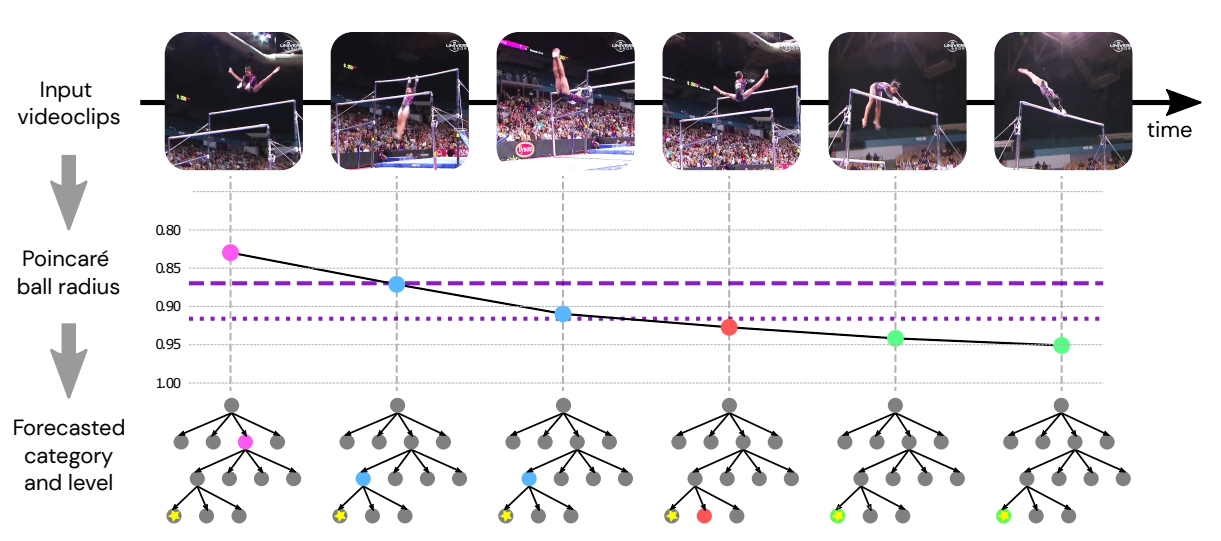
콜롬비아 대학(Columbia University) 연구팀이 미래에 무엇이 예측 가능한지를 말할 수 있는 능력을 가진 인공지능(AI) 프레임워크를 개발했다. 흥미롭게도 이 AI 모델은 레이블이 없는 비디오 데이터를 사용하여 구축되었다. 그들의 접근 방식은 예측할 기능을 미리 확인하는 대신 어떤 기능이 예측 가능한지 데이터에서 학습한다.
연구팀은 미래를 예측하는 것은 로봇 공학, 보안, 헬스케어 뿐만 아니라 다양한 응용 분야 등에서 컴퓨터 비전의 핵심적인 과제라고 한다.
연구팀은 픽셀과 모션을 생성하고, 미래의 활동을 예측하는 것과 같은 다양한 옵션들을 검토해왔고, 그 중에서 이 문제를 해결하기 위한 모델이 미래를 예측할 수 있는 해결책으로 쌍곡선 기하학이 계층적 구조를 자연스럽고 간결하게 부호화 한다는 것을 바탕으로 쌍곡선 공간에서 예측 모델을 개발하고 오픈 소스로 공개했다.

모델은 가장 신뢰할 수 있는 경우, 계층 구조의 구체적인 수준에서 예측하지만 모델이 신뢰할 수 없는 경우 자동으로 더 높은 수준의 추상적으로 선택하는 방법을 학습한다. 두 개의 설정된 데이터 세트에 대한 실험은 행동 예측을 위한 계층적 표현의 핵심 역할을 보여준다. 연구팀은 레이블이 지정되지 않은 비디오로 학습되었지만 시각화는 표현에서 행동 계층이 나타난다는 것을 보여준다.
이 연구에서 핵심은 모델이 미래의 계층적 표현을 예측하는 것이다. 미래가 확실할 때 모델은 가능한 한 구체적으로 미래 z를 예측해야 한다. 그러나 미래가 불확실할 때 모델은 베팅를 회피하고(hedge the bet) z의 계층적 부모를 예측해야 한다. 비공식적으로 쌍곡선 공간은 트리의 연속적인 유사체로 볼 수 있다. 이 공간은 자연스럽게 계층 구조에 적합하기 때문에 쌍곡선 예측 모델은 추상적 표현 (예측 가능성이 낮은 경우)과 구체적인 표현 (예측 가능성이 높은 경우) 사이를 원활하게 보간(Interpolation) 할 수 있다.

미래는 결정적이지 않다. 특정 과거 (그림의 처음 세 프레임)가 주어지면 다른 표현 (푸앙카레 공의 사각형으로 표시됨)이 서로 다른 미래를 인코딩 할 수 있으며 모두 가능하다. 모델이 불확실한 경우 ẑ (빨간색 사각형) 으로 표시되는 이러한 모든 가능한 미래를 추상적으로 예측한다. 더 확실할수록 더 구체적인 예측을 얻을 수 있다. 실제 미래가 z (파란색 사각형)로 표시된다고 가정하면 회색 화살표는 더 많은 정보를 사용할 수 있을 때 예측이 따를 궤적을 나타낸다. 분홍색 원은 두 가지 특정 표현 (분홍색 사각형)의 평균을 계산할 때 일반성의 증가를 보여준다.
연구팀은 레이블이 지정되지 않은 대규모 비디오 컬렉션에서 자체 감독된 표현을 학습한 후 레이블이 지정된 더 작은 데이터 세트를 사용하여 이러한 표현을 대상 도메인으로 전송했다. 대상 도메인에서 연구팀은 소수의 라벨링된 예제를 사용하여 감독된 선형 분류기를 맞추기 전에 동일한 목표를 미세 조정했다.
평가는 두 개의 서로 다른 비디오 데이터 세트를 사용하여 수행되었다.
먼저, 스포츠 비디오는 키네틱스-600(Kinetics-600)과 파인짐(FineGym)이라는 두 개의 스포츠 비디오 데이터 세트에서 자체 감독된 표현을 학습했다. 키네틱스는 600 개의 인간 행동 클래스와 풍부하고 다양한 인간 행동이 포함 된 50만개의 비디오가 있다. 파인짐은 체조 비디오 데이터 세트로, 클립에 가장 낮은 수준의 특정 운동 이름에서부터 가장 높은 수준의 일반적인 체조 루틴에 이르기까지 3 단계 계층 액션 레이블이 주석을 달고 있다.
또한 영화에서 연구팀은 MovieNet에서 자가 감독 표현을 학습한 다음 Hollywood2 데이터 세트를 미세 조정하고 평가했다. MovieNet은 1,100편의 영화와 75만 8천 개의 핵심 프레임을 포함하고 있다.
결론적으로 미래는 불확실하며, 다음 사건을 확실하게 예측하는 것은 항상 불가능하다. 그러나 일부는 예측이 가능하다는 것이다. 이 연구를 통해 팀은 불확실성을 계층적으로 나타내는 비디오 예측을 위한 쌍곡선 모델을 도입했으며, 연구팀은 레이블이 없는 비디오에서 학습한 후 실험과 시각화를 통해 계층 구조가 자동으로 나타나 미래의 예측 가능성을 인코딩한 것이다.
이 연구는 지난 1일 아카이브를 통해 '미래의 예측 가능성 학습(Learning the Predictability of the Future- 다운)'이란 제목으로 발표됐으며, 관련 모델 및 소스 코드는 깃허브(다운)에 DPC 코드를 기반으로 작성되었다.
관련기사
- [AI 리뷰] 오픈AI, 글 쓰는 GPT-3에서 진화... 텍스트 읽고 그림 그리는 AI 모델 'DALL·E' 및 'CLIP' 공개
- [AI 리뷰] 설명가능한 AI, 이종학습 기술... 주식 매매심사에서 불공정거래 찾아낸다!
- [AI 리뷰] 인공지능이 피트니스 추적 혁신한다!.. 보쉬센서텍, 자가학습 AI 센서 출시
- [AI 리뷰] MIT, 시계열 데이터 이상을 감지하는 딥러닝 기반 'TadGAN' 알고리즘 오픈 소스로 공개
- [AI 리뷰] 도시바, 제품 검사에서 세계 최고 수준 정밀도로 식별하는 '이상 식별 AI' 개발
- [AI 리뷰] AWS, '세이지메이커' 머신러닝 구현에 9가지 새 기능으로 더 편리하고 똑똑해졌다
- [AI 리뷰] AI 의사결정에서 불확실성 더 빨리 추정해... 더 안전한 의사결정 돕는 새로운 네트워크 개발
- [AI 리뷰] 바이탈사인(VS) 모니터링 선별적 제한하는 인공지능... 입원환자 수면 개선으로 치료 효과 증대
- [AI 리뷰] 구글 AI, 실시간 3D 객체 감지 위한 '오브젝트론 데이터 세트' 오픈 소스로 공개
- [AI 리뷰] 머신러닝으로 화상회의에서 배경 마음대로 바꾼다... 구글 미트 새로운 AI 기능
- [AI 리뷰] 새로운 딥러닝 모델... 아주 적은 뉴런으로 간단하고 더 똑똑한 인공지능 개발
- [AI 리뷰] 작물 질병을 식별하는 인공지능 앱 만들기... 오픈 소스를 통한 간단한 방법들
- [AI 리뷰] MIT 연구팀, 머신러닝으로 잠재적인 새로운 결핵 치료제 발견
- [AI 리뷰] 인공지능 시대를 위한 리더들의 10 가지 핵심 리더십은?
- [AI 리뷰] 양자 컴퓨팅 통신 위한 큐빗 생성으로... 완전한 양자 컴퓨팅 플랫폼으로 가는 길 열어
- [AI 리뷰] 인공지능 학습 이미지에서 편견을 식별하는 AI 툴... 오픈 소스로 공개
- [AI 리뷰] 유엔식량농업기구, 농업에서 인공지능 도입은 식량 불안을 해결하고, 디지털 격차를 해소시킨다!
- [AI 리뷰] 모든 것을 지능화... 바이두, 4 가지 새로운 인공지능 기술 발표
- [AI 리뷰] 질병 치료 위한 최상의 약물 조합... 혁신적으로 추론하는 인공지능 모델 오픈 소스로 공개!