딥러닝 모델의 메타인지가 가능해지면 지능을 증강하는 형태의 AI 모델도 개발할 수 있게 된다. 또한 자율주행, 의료 진단 등 안전이나 생명과 직결되는 민감한 분야에서 유용하게 이용할 수 있을 것으로 기대

오늘날 이용되는 대부분의 인공지능은 주어진 후보 중 정답이 없으면 가장 비슷한 답을 찾도록 설계됐다.
특히 딥러닝 모델은 이미지 인식 능력이 탁월해 컴퓨터비전 분야에서 다양하게 활용되고 있으나, 답을 몰라도 가장 유사한 값을 정답으로 잘못 인식한다는 단점이 있다. 이 경우 자율주행 차량이 장애물을 잘못 인식하는 등 심각한 문제를 일으킬 수 있어 이를 보완할 AI모델의 필요성이 제기되고 있다.
여기에, 지스트(광주과학기술원, 총장직무대행 박래길) 융합기술학제학부 이규빈 교수 연구팀은 학습한 적 없는 ‘모르는 데이터’를 구별해 내는 AI 기술을 개발했다.
AI모델은 여러 블록으로 구성되어 있는데, 각 블록은 똑같은 작업을 수행한다. 컨베이어 벨트에 재료(데이터)가 들어오고, 여러 사람(블록)이 분업하여 순서대로 물건을 완성하는 것과 같다.
연구팀은 이 중 ‘모르는 데이터’ 탐지에 적합한 블록을 찾아내기 위해 직소 퍼즐을 이용했으며, 블록의 활성도를 기준으로 모르는 데이터를 탐지하는 방법을 제시했다.
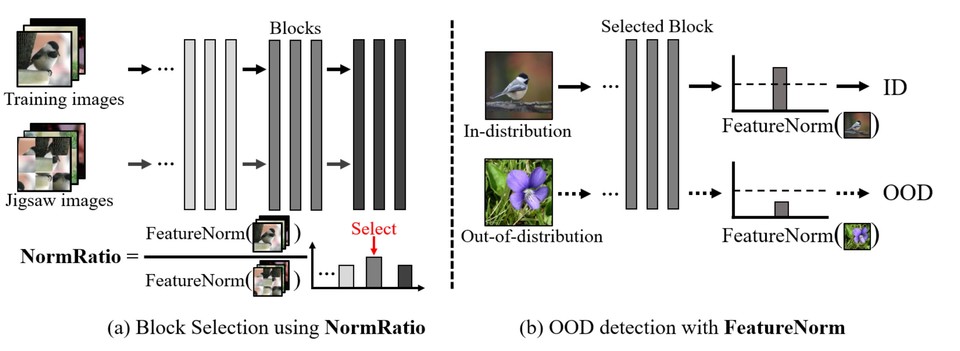
연구팀은 모르는 데이터의 예시로써 이미지를 직소 퍼즐처럼 잘게 쪼갠 뒤 무작위로 섞어서 입력했다. 실제 이미지와 유사하지만 정답은 아닌 데이터를 입력한 후 활성도에 따라 모르는 데이터 탐지에 적합한 블록을 찾기 위해서다.
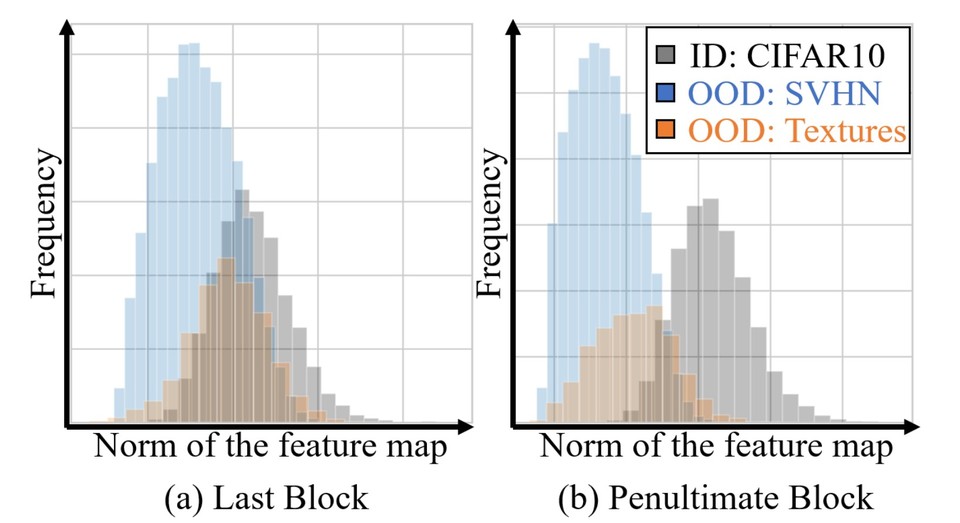
기존 연구에서는 가장 많은 데이터를 학습한 마지막 블록을 사용했으나, 연구팀은 마지막 블록이 과도한 학습으로 인해 모르는 데이터도 아는 데이터로 착각하는 경향이 있다는 점을 밝혀냈다.
연구팀은 모르는 데이터(직소 퍼즐)에는 낮은 활성도를, 아는 데이터에는 높은 활성도를 보이는 블록이 모르는 데이터 탐지에 가장 적합한 것으로 보고, 직소 퍼즐에 대한 활성도 대비 학습된 이미지에 대한 활성도가 가장 높은 블록을 선택했다.
이 방식으로 기존에 사용하던 첫 번째 CIFAR10 벤치마크에서는 5.8%, 두 번째 ImageNet 벤치마크에서는 6.8% 향상된 탐지 결과를 얻어 현재까지 가장 높은 수준의 성능이 달성됐다.
이번 연구성과로 딥러닝 모델의 메타인지가 가능해지면 지능을 증강하는 형태의 AI 모델도 개발할 수 있게 된다. 또한 자율주행, 의료 진단 등 안전이나 생명과 직결되는 민감한 분야에서 유용하게 이용할 수 있을 것으로 기대된다. 즉, 메타인지란 자신의 생각에 대해 판단하는 능력으로 이번 연구에서는 아는 것을 안다, 모르는 것을 모른다라고 판단할 수 있는 능력을 뜻한다.
자율주행차 운행 중 동물을 사람으로 잘못 인식해 급정거하거나 학습한 적 없는 피부병을 기존에 학습한 피부병 중 가장 유사한 질환으로 오진하는 것과 같은 문제를 방지할 수 있다.
이규빈 교수는 “이번 연구성과를 발전시키면 딥러닝 모델이 인식된 결과를 스스로 인지하는 메타인지 능력을 얻을 수 있다”며 “모르는 것을 아는 것으로 잘못 인식해 발생할 수 있는 막대한 피해를 방지할 수 있을 뿐만 아니라, 지능 증강과 같은 다양한 기술로 응용될 것이라고 기대한다”고 밝혔다.
한편, 유연국 박사과정생이 신성호 박사과정생, 이성주 박사과정생, 전창현 석사와 함께 진행한 이번 연구는 컴퓨터비전 분야에서 세계 최고 수준의 학회인 '컴퓨터비전과 패턴인식 학술대회(CVPR 2023)'에서 '분포 외 탐지에서 형상 표준을 사용하기 위한 블럭 선택 방법(Block Selection Method for Using Feature Norm in Out-of-distribution Detection-다운)' 란 제목으로 오는 6월 18일 발표될 예정이다. 연구에 사용된 코드는 깃허브에서 오픈소스(다운)로 이용할 수 있다