DGIST 박상현 교수팀, 편향된 데이터를 사용하여 딥러닝 모델을 학습하더라도 정확한 분류 결과를 도출하는 이미지 변환 모델로 자율주행, 콘텐츠 생성, 의료 분야 등 다양한 분야의 적용 기대돼...

일반적으로 인공지능(AI) 딥러닝 모델을 훈련시키기 위해 사용되는 데이터셋에는 종종 편향이 존재할 수 있다. 예를 들어, 세균성 폐렴과 코로나를 구분하는 데이터셋을 만든다고 했을 때, 코로나 감염 위험으로 인해 서로 다른 조건에서 영상을 수집하게 될 수 있다.
이로 인해 영상 내에 미세한 차이가 생겨 실제 질병을 구분하기 위한 중요한 특징들이 아닌 영상 프로토콜 간의 차이로 발생하는 특징들로 질환을 구분하게 된다. 이 경우 학습에 이용한 데이터에 대해서는 높은 성능을 보이지만 일반성이 떨어져 다른 곳에서 취득한 데이터에는 잘 동작하지 않는 오버피팅 문제가 발생한다.
특히 이런 상황에서 기존 딥러닝 기법은 질감의 차이를 중요하게 활용하는 경향이 있어 예측이 부정확할 수 있었다.
이에 DGIST(총장 국양) 로봇및기계전자공학과 박상현 교수 연구팀이 데이터의 편향을 효과적으로 줄여줄 수 있는 새로운 이미지 변환 모델을 개발했다.
여러 소스에서 수집한 이미지를 사용해 AI 모델을 개발할 때 사용자의 의도와 다르게 다양한 요소에 의해 데이터 편향이 일어날 수 있는데, 이러한 요소정보가 없더라도 편향을 제거해줄 수 있어 높은 영상분석 성능을 얻을 수 있게 도와준다. 자율주행, 콘텐츠 생성, 의료 분야에서 혁신적인 역할을 할 수 있을 것으로 기대된다.
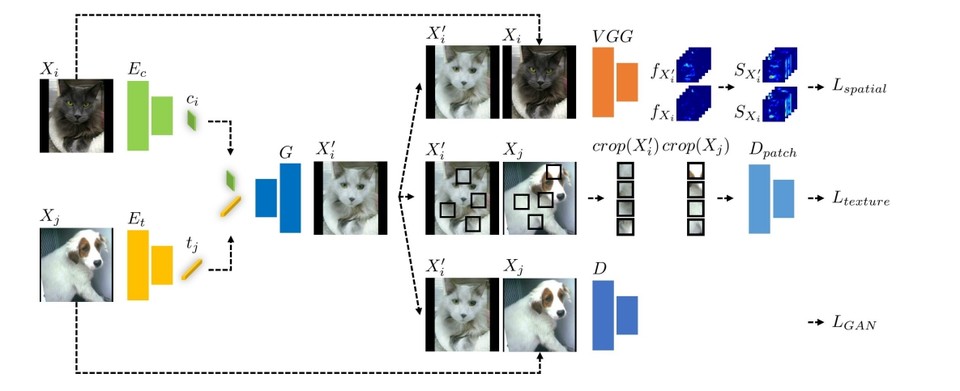
박상현 교수팀은 이미지 변환 모델을 개발하여 질감의 편향을 제거한 데이터셋을 만들고, 이를 활용하여 모델을 학습시키는 방법을 고안했다. 기존 이미지 변환 모델은 질감과 내용이 서로 얽혀 있어 질감을 바꾸면 내용도 함께 변형되는 문제가 있었는데, 이를 해결하기 위해 질감과 콘텐츠를 각각 다루는 오류함수를 동시에 사용하는 모델을 새롭게 개발한 것이다.
이번 연구팀이 제안한 새로운 이미지 변환 모델은 입력 이미지의 콘텐츠 정보와 다른 도메인의 질감 정보를 추출하여 결합시키는 방식으로 작동한다. 이때 입력 이미지의 콘텐츠 정보와 새로운 도메인의 질감 정보를 동시에 유지하기 위해 콘텐츠 자기유사성(Spatial self-similarity) 오류함수와 질감동시발생(co-occurence) 오류함수를 함께 사용하여 모델을 학습시킨다.
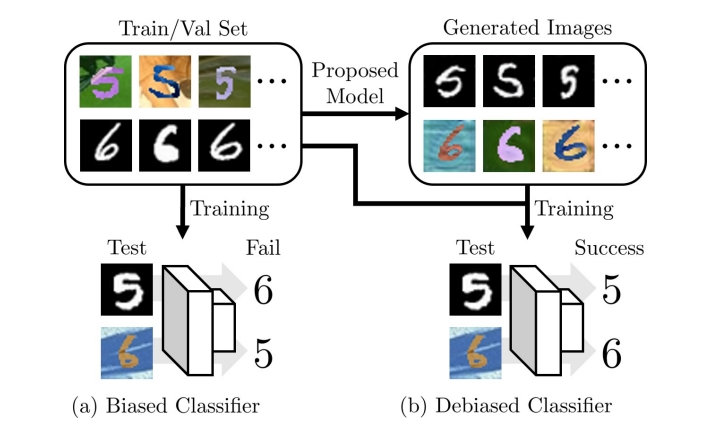
그 결과, 입력 이미지의 콘텐츠 정보는 유지한 채로 다른 도메인의 질감을 갖는 이미지를 생성할 수 있게 됐으며 이러한 방법을 사용해 질감 편향이 제거된 데이터셋을 만들고 이를 활용하여 딥러닝 모델을 훈련시킴으로써 기존 방법에 비해 큰 성능 향상을 확인할 수 있었다.
특히, 연구팀은 질감 편향이 존재하는 숫자 분류 데이터셋, 털이 색상이 다른 개-고양이 분류 데이터셋, 촬영 프로토콜이 다른 코로나-세균성폐렴 분류 데이터셋에서 기존 편향 제거 및 이미지 변환 기법 대비 높은 성능을 도출했으며, 멀티 라벨 숫자 분류 데이터셋 및 사진-그림-만화-스케치 와 같이 여러 편향이 존재하는 데이터셋에서도 더 나은 결과를 도출할 수 있었다.
나아가 박상현 교수팀이 제안한 이미지 변환 기법은 이미지 조작 작업에도 적용할 수 있다. 이 기법을 기존의 이미지 조작 방법과 비교하면, 이미지의 내용은 그대로 유지하면서 질감만을 조작하는 결과를 확인할 수 있었다.
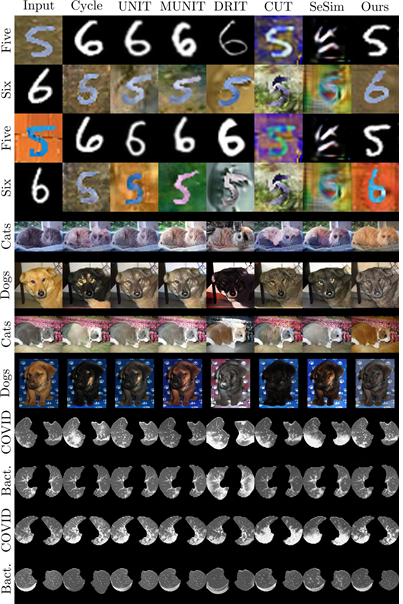
또한, 이 기법은 다른 환경으로의 적응에도 효과적으로 사용할 수 있다. 의료 영상 및 자율주행 영상과 같은 다양한 도메인에서 기존의 적응 기법과 성능을 비교한 결과, 이 새로운 기법이 더 높은 성능을 보여주는 것을 확인했다.
DGIST 로봇및기계전자공학과 박상현 교수는 “이번 연구를 통해 개발된 기술은 산업 및 의료 분야에서 딥러닝 모델 학습을 위해 편향된 데이터셋을 불가피하게 사용해야 하는 상황에서 성능을 크게 높일 수 있는 기법이다”라며, “인공지능을 상업적으로 이용하거나 배포할 때 여러 환경에서 강인하도록 하는 데에 크게 기여할 수 있을 것으로 기대된다”고 말했다.
한편, 이번 연구 결과는 우수성을 인정받아 영상분석 관련 분야 최상위 저널인 ‘신경망(Neural Networks)’ 9월호에 '텍스처 편향 및 도메인 적응을 위한 텍스처 동시 발생 및 공간적 자기 유사성을 통해 콘텐츠 보존 이미지 변환(Content preserving image translation with texture co-occurrence and spatial self-similarity for texture debiasing and domain adaptation-보기)'란 제목으로 게재(아카이브 다운)됐다.