하이퍼클로바X, GPT-3.5-Turbo와 Gemini-Pro보다 높은 평균 점수 기록…한국 특화 지식에서는 GPT-4도 앞서

네이버클라우드(대표 김유원)는 하이퍼클로바X(HyperCLOVA X)가 한국판 인공지능(AI )성능 평가 체계 ‘KMMLU(Measuring Massive Multitask Language Understanding in Korean)’에서 오픈AI, 구글의 생성형 AI보다 높은 점수를 기록하며, 소버린 AI로서 우수한 성능 경쟁력을 확인할 수 있었다.
지난 18일 아카이브를 통해 발표된 논문 'KMMLU: 한국어의 대규모 멀티태스킹 언어 이해 측정(KMMLU: Measuring Massive Multitask Language Understanding in Korean-다운)'에 따르면 하이퍼클로바X는 오픈AI의 GPT-3.5-Turbo와 구글의 Gemini-Pro보다 높은 점수를 기록하며, 일반 지식(General Knowledge)과 한국 특화 지식(Korea-Specific Knowledge)을 종합한 전반적인 성능이 글로벌 빅테크의 AI와 경쟁할 수 있는 수준임이 확인됐다.
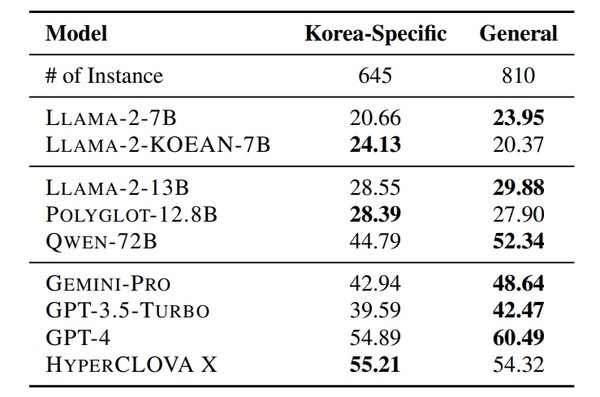
KMMLU는 국내의 대표적인 오픈소스 언어모델 연구팀인 ‘해례(HAE-RAE)’가 이끈 AI 성능 평가 지표 구축 프로젝트다. 인문학, 사회학, 과학∙기술 등 45개 분야에서 전문가 수준의 지식을 묻는 35,030개 문항으로 구성되어 있다.
수학적 추론 능력과 같이 전세계 공통적으로 적용 가능한 광범위한 지식을 묻는 문항 비중이 약 80%, 한반도 지리, 국내법 등 한국 특화 문제 해결 능력을 평가하기 위한 문항은 20%로, AI의 보편적 능력과 로컬 지식을 고르게 측정해 한국 사용자에게 유용한 AI를 종합적으로 판단할 수 있다.
또한 오픈AI, 구글 등 북미 테크 기업들이 자사 AI 성능을 확인하기 위해 주로 사용하는 지표인 ‘MMLU’를 한국어로 번역하는 경우, 문항의 부정확한 번역과 여러 문제에 내재된 영어권 국가만의 문화적 맥락 때문에 AI 모델의 한국어 능력을 제대로 가늠하기 어려운 한계가 있었다.
KMMLU는 한국어 원본의 시험 문제들로 구성되어, 국내∙외 AI의 한국어 이해 역량도 보다 정확하게 평가할 수 있다.
한국 특화 지식 기준으로는 오픈AI의 GPT-4보다도 높은 점수를 기록해, 교육, 법률 등 로컬 정보의 중요성이 큰 산업 분야에서는 하이퍼클로바X가 가장 유용할 수 있음을 보였다.
네이버클라우드는 KMMLU를 통해 입증된 하이퍼클로바X의 성능 경쟁력을 바탕으로, 하이퍼클로바X를 보안과 성능을 모두 갖춘 ‘소버린(Sovereign) AI’ 솔루션으로 발전시켜나가겠다는 계획이다.
지난해 10월에 고객사가 폐쇄된 사내망에서 하이퍼클로바X를 사용하며 데이터 유출을 방지할 수 있는 하이브리드 클라우드 서비스 ‘뉴로클라우드 포 하이퍼클로바X(Neurocloud for HyperCLOVA X)’를 출시했고, 향후 다양한 기업용 솔루션도 선보일 계획이다.
성낙호 네이버클라우드 하이퍼스케일(Hyperscale) AI 기술 총괄은 “하이퍼클로바X는 세계 공통의 보편 지식에 한국 특화 문제 해결 능력을 더한 소버린 AI로, 우수한 성능, 강력한 보안을 갖춘 솔루션과 함께 국내 산업계 전반에서 도입이 이뤄지고 있다.”며 “자국어 중심 AI에 대한 전세계적 수요가 관찰되는 만큼, 한국에서 확인한 소버린 AI의 경쟁력을 바탕으로 향후 글로벌 시장 진출에도 속도를 낼 것”이라고 말했다.
한편, 네이버클라우드는 KMMLU를 설계하는 과정에도 참여하며, AI 모델들의 한국어 이해 능력을 보다 객관적으로 평가해 더욱 우수한 성능의 AI가 한국에서 만들어질 수 있는 환경을 조성하는 데에도 적극적으로 기여하고 있다.
뿐만 아니라 2021년에는 30여 곳 기업과 대학의 자연어처리 전문가들과 함께 한국어 자연어 이해 벤치마크 ‘KLUE(Korean Language Understanding Evaluation)’를 구축했으며, 지난해에는 사회과학, 법학 등 여러 학문 분야와의 협력 연구를 통해 국내 초대규모 언어모델의 신뢰성 향상을 위한 한국어 데이터셋(아래 참조)을 공개하기도 했다.
▷SQuARe: 인간-기계 협업을 통해 생성된 민감한 질문과 수용 가능한 응답의 대규모 데이터 세트(SQuARe: A Large-Scale Dataset of Sensitive Questions and Acceptable Responses Created Through Human-Machine Collaboration-다운), ▷KoSBi: 보다 안전한 대형언어모델 적용을 위한 사회적 편향과 위험 완화를 위한 데이터 세트(KoSBi: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Application-다운).