CNN이 정확히 무엇이며, 영상에서는 때로는 복잡한 개념을 쉽게 이해할 수 있는 부분으로 나누어 로컬 수용 필드, 공유 가중치 및 바이어스, 활성화 및 풀링 등의 세 가지 개념을 배운다
아래 영상은 매스웍스의 MATLAB ® Tech Talk에서 컨볼루션 뉴런 네트워크(CNN, Convolutional Neural Network)의 기본 원리를 살펴보고 CNN이 일반적인 딥러닝 아키텍처이지만 CNN은 정확히 무엇인가? 를 알아보고 또 CNN의 복잡한 개념을 쉽게 이해할 수 있는 부분으로 나누어 로컬 수용 필드, 공유 가중치 및 바이어스, 활성화 및 풀링 등의 세 가지 개념을 배운다.
또한 영상에서는 이 세 가지 개념을 결합하여 CNN에서 레이어를 구성하는 방법을 보여준다.
이미지 분석을 위해 CNN을 훈련시키는 세 가지 방법에 대해서도 배우게 된다. 첫 번째, 모델 교육 두 번째, 전송 학습을 사용하여 (유사한 문제를 해결하기 위해 한 가지 유형의 문제에 대한 지식을 사용할 수 있다는 생각에 기반 함) 세 번째, 사전 학습 된 CNN을 사용하여 기계 학습 모델을 학습하기 위한 기능을 추출한다.
아래는 컨벌루션 뉴런 네트워크(CNN) 란 무엇입니까? 의 영상 대본입니다.
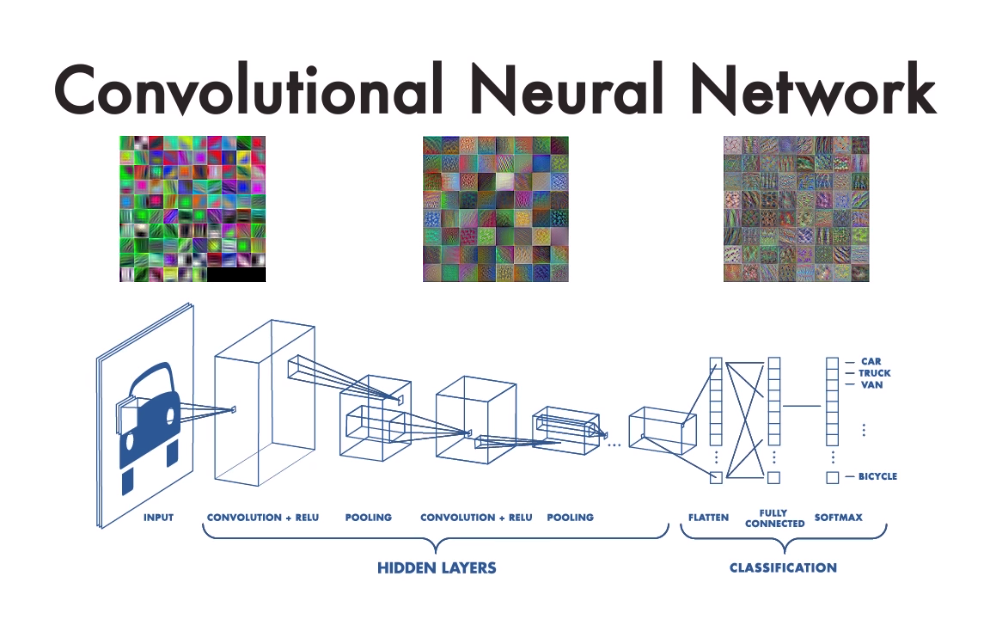
컨볼루션 신경 네트워크 (CNN)는 깊은 학습을 위한 네트워크 아키텍처입니다. 이미지에서 직접 학습합니다.
출력을 생성하기 위해 입력을 처리하고 변환하는 여러 레이어로 구성됩니다.
CNN이 장면 분류, 물체 감지 및 분할, 이미지 처리 등의 이미지 분석 작업을 수행하도록 교육 할 수 있습니다.
CNN의 작동 방식을 이해하기 위해 다음 세 가지 개념을 다룰 것입니다.
1) 지역 수용 필드
2) 공유 가중치 및 편견
3) 활성화 및 풀링
마지막으로 이미지 분석을 위해 CNN을 교육하는 세 가지 방법에 대해 간략하게 살펴보겠습니다.
지역 수용 필드의 개념부터 살펴보겠습니다.
일반적인 신경 네트워크에서 입력 레이어의 각 뉴런은 숨겨진 레이어의 뉴런에 연결됩니다. 그러나 CNN에서는 입력 영역 뉴런의 작은 영역만이 숨겨진 계층의 뉴런에 연결됩니다. 이 지역을 지역 수용 필드라고 합니다.
로컬 수용 필드는 입력 레이어에서 숨겨진 레이어 뉴런으로 피쳐 맵을 만들기 위해 이미지 전체에서 변환됩니다. 회선을 사용하여 이 프로세스를 효율적으로 구현할 수 있습니다. 이것이 왜곡 된 신경 네트워크라고 불리는 이유입니다.
두 번째 개념은 공유 가중치와 편향에 관한 것입니다.
신경 네트워크와 마찬가지로, CNN은 가중치와 편견을 가진 뉴런을 가지고 있습니다. 이 모델은 교육 과정에서 이 값을 학습하고 각각의 새로운 학습 예제로 지속적으로 업데이트합니다. 그러나 CNN의 경우, 주어진 레이어의 모든 숨겨진 뉴런에 대해 가중치 및 바이어스 값이 동일합니다.
이것은 모든 숨겨진 뉴런이 이미지의 다른 영역에서 동일한 특징(예: 가장자리 또는 얼룩)을 감지하고 있음을 의미합니다. 이로써 네트워크에서 이미지의 오브젝트 변환을 허용합니다.
예를 들어, 고양이를 인식하도록 훈련 된 네트워크는 고양이가 어디에 있든 간에 그렇게 할 수 있습니다.
우리의 세 번째이자 마지막 개념은 활성화와 풀링입니다. 활성화 단계는 활성화 함수를 사용하여 각 뉴런의 출력에 변형을 적용합니다. Rectified Linear Unit 또는 ReLU는 일반적으로 사용되는 활성화 기능의 예입니다.
그것은 뉴런의 출력을 취하여 가장 높은 양의 값으로 매핑합니다. 또는 출력이 음수이면 함수는 이를 0으로 매핑 합니다.
단계를 적용하여 활성화 단계의 출력을 추가로 변환 할 수 있습니다. 뉴런의 작은 영역의 출력을 단일 출력으로 응축하여 피쳐 맵의 차원을 줄입니다. 이는 다음 레이어를 단순화하고 모델이 학습해야하는 매개 변수의 수를 줄이는 데 도움이 됩니다.
자, 모두 합시다. 이 세 가지 개념을 사용하여 CNN에서 레이어를 구성 할 수 있습니다. CNN에는 수십 또는 수백 개의 숨겨진 레이어가 있을 수 있으며 각 레이어는 이미지의 다른 기능을 감지합니다.
이 피쳐 맵에서 모든 숨겨진 레이어는 학습 된 이미지 기능의 복잡성을 증가 시킨다는 것을 알 수 있습니다. 예를 들어 첫 번째 숨겨진 레이어는 가장자리를 감지하는 방법을 배우고 마지막으로 더 복잡한 모양을 감지하는 방법을 배웁니다.
전형적인 신경망에서처럼, 마지막 층은 마지막 숨겨진 층의 모든 뉴런과 출력 뉴런을 연결합니다. 이렇게 하면 최종 출력이 생성됩니다. 이미지 분석을 위해 CNN을 사용하는 세 가지 방법이 있습니다.
첫 번째 방법은 CNN을 처음부터 교육하는 것입니다. 이 방법은 수십만 개의 레이블이 지정된 이미지와 중요한 계산 리소스가 필요할 수도 있기 때문에 가장 어렵지만 매우 정확합니다.
두 번째 방법은 유사한 문제를 해결하기 위해 한 가지 유형의 문제에 대한 지식을 사용할 수 있다는 아이디어를 기반으로 한 이전 학습에 의존합니다. 예를 들어 자동차와 트럭을 구별하는 새 모델을 초기화하고 교육하기 위해 동물을 인식하도록 훈련 된 CNN 모델을 사용할 수 있습니다. 이 방법은 첫 번째 방법보다 적은 양의 데이터와 계산 자원을 필요로 합니다.
세 번째 방법을 사용하면 사전 학습 된 CNN을 사용하여 기계 학습 모델을 교육하기 위한 기능을 추출 할 수 있습니다. 예를 들어, 이미지의 가장자리를 감지하는 방법을 배운 숨겨진 레이어는 여러 도메인의 이미지와 관련이 있습니다. 이 방법은 최소량의 데이터와 계산 리소스를 필요로 합니다.