오픈포즈(OpenPose)와 Mask R-CNN을 사용해, 바이올린이나 피아노 연주의 오디오 입력에서 아바타의 움직임을 추정하는 신경망 시스템
지난달 18일부터 22일까지 미국 솔트레이크시티 솔트 팰리스(Salt Palace) 컨벤션 센터에서 개최된 ‘컴퓨터 비전 및 딥러닝 컨퍼런스 CVPR 2018(IEEE Conference on Computer Vision and Pattern Recognition)'에서 많은 신기술과 연구 결과가 발표됐다. 국내에서는 대표적으로 네이버가 참가해 작년에 이어 올해도 다섯 편의 논문이 채택되었으며, 국내 산학기관 중 유일하게 CVPR 상위 2% 이내에 선정, 'Oral' 세션을 통해 발표되는 성과를 얻기도 했다.
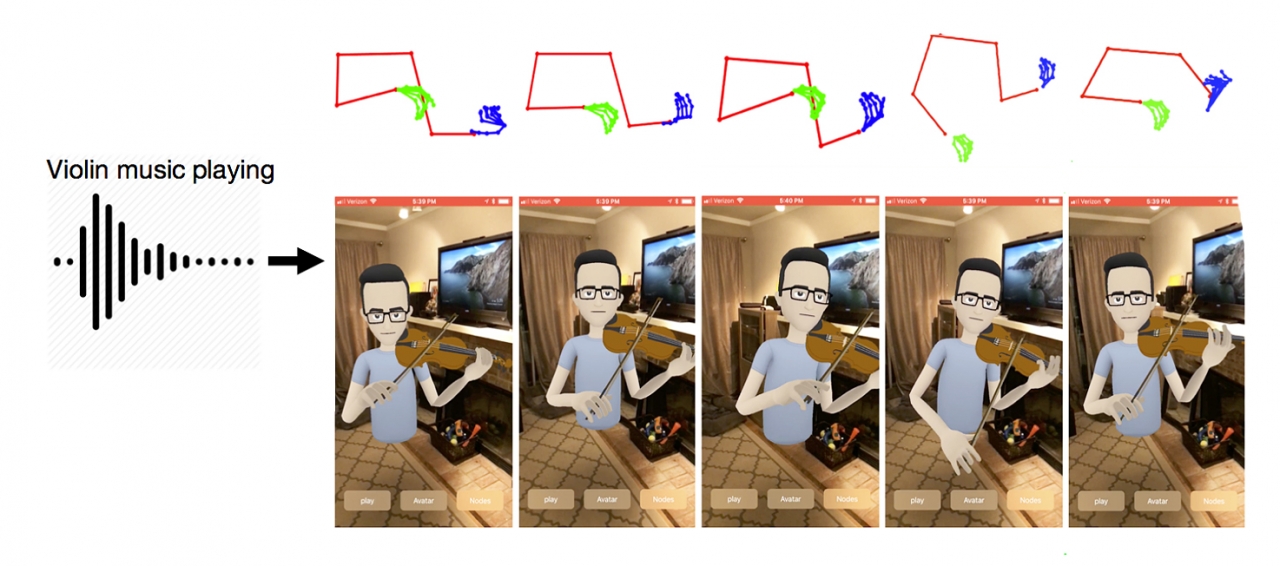
특히, 페이스북 AI 리서치와 스탠포드 대학과 워싱턴 대학의 연구진은 이번 ‘컴퓨터 비전 및 딥러닝 컨퍼런스'에서는 신경망을 이용하여 바이올린과 피아노 연주의 오디오 입력에서 아바타의 움직임을 추정하는 '오디오-신체 역학(Audio to Body Dynamics)'시스템이 발표돼 많은 주목을 받았다. 이 연구에서는 오디오로 신체 역학을 예측할 수 있다는 첫 번째 결과를 제시한 것으로 관련 연구 자료를 통해 요약해 본다.
발표된 시스템은 바이올린이나 피아노 연주의 오디오를 입력으로 하고 아바타 애니메이션을 만들 골격 예측 영상을 출력하는 신경망을 이용한 방법으로 음성 신호로부터 신체 동작을 예측한다. 기법에서는 손과 얼굴을 포함한 신체의 움직임을 실시간으로 추적할 수 있는 오픈포즈(OpenPose)와 페이스북 AI연구소가 발표한 Mask R-CNN(다운받기)을 사용해 추정한 것이다.
또한 피아노와 바이올린의 영상(위 Youtube 영상 참조)에서 각 영상의 각 프레임의 상체와 손가락을 감지하고 오디오 기능과 신체 골격의 랜드 마크의 상관 관계를 인터넷에 업로드 된 바이올린 및 피아노 연주 비디오에 대해 학습 받은 LSTM(Long-Short-Term-Memory, RNN) 신경망을 구축, 예측된 움직임의 포인트를 기반으로 애니메이션을 만들고 오디오에 따라 움직이는 아바타로 출력했다.
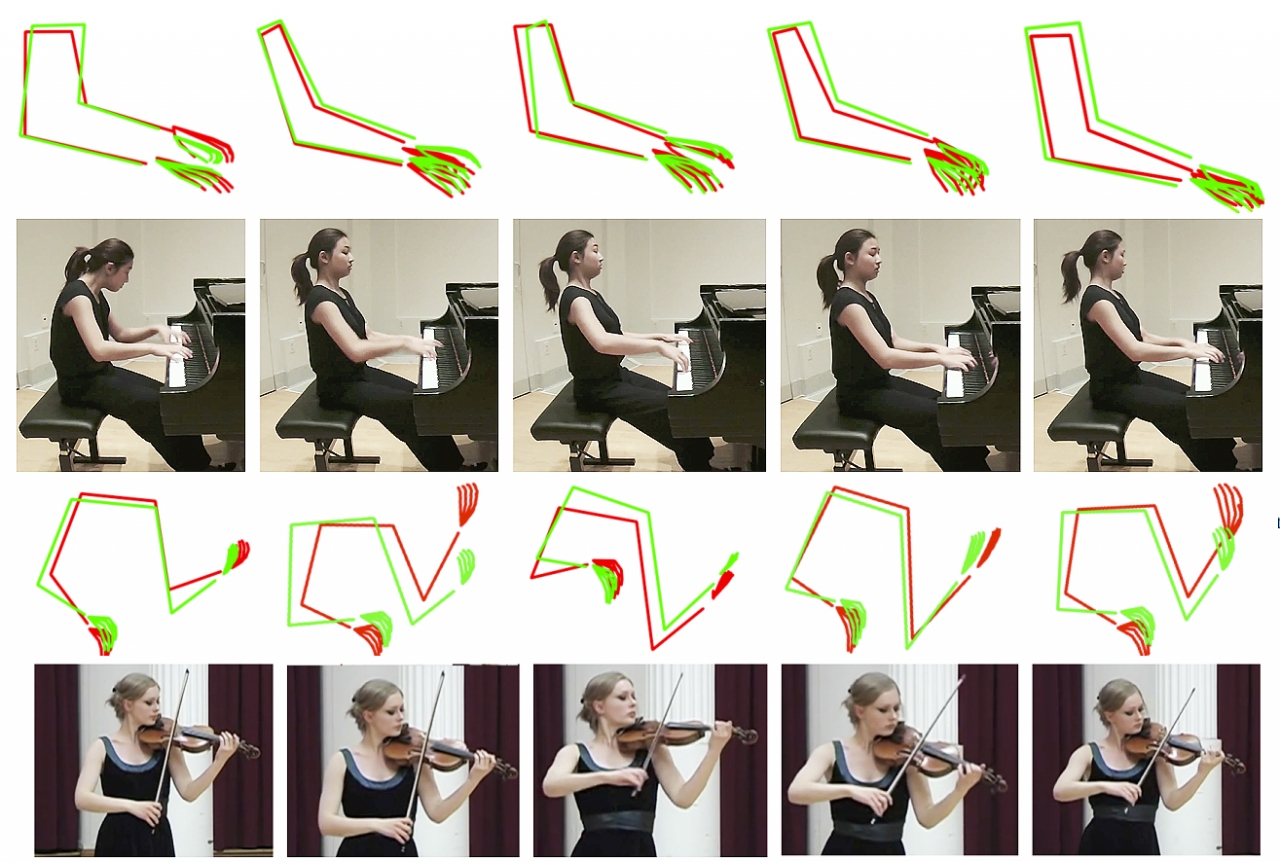
한편 연구팀은 바이올린이나 피아노 연주 오디오를 입력으로 받아서 아바타를 애니메이트하는 데 사용되는 뼈대 예측 비디오를 출력하는 방법을 제시한 것으로 핵심 아이디어는 피아니스트 또는 바이올리니스트와 마찬가지로 오디오에서처럼 손을 움직이는 아바타의 애니메이션을 만드는 것이다. 정확한 팔과 손가락 움직임을 완벽하게 추정하는 것이 목표로 하는 것이 연구팀의 목표이지만, 이 연구에서는 오디오로 신체 역학을 예측할 수 있다는 첫 번째 결과를 제시한 것으로 이 기술을 적용하고 한단계 더 높인다면 디지털미디어 산업에 큰 발전을 이끌어낼 수 있을 것으로 기대된다.(발표 논문명 'Audio to Body Dynamics' 다운받기)