알고리즘에 대한 대규모 계산을 가능하게 하기 위해 사용자가 로컬 계산 방법을 수백 또는 수천 대의 머신으로 쉽게 확장할 수 있는 새로운 분산 컴퓨팅 라이브러리... AI를 위한 분산 컴퓨팅이 간단해졌다.
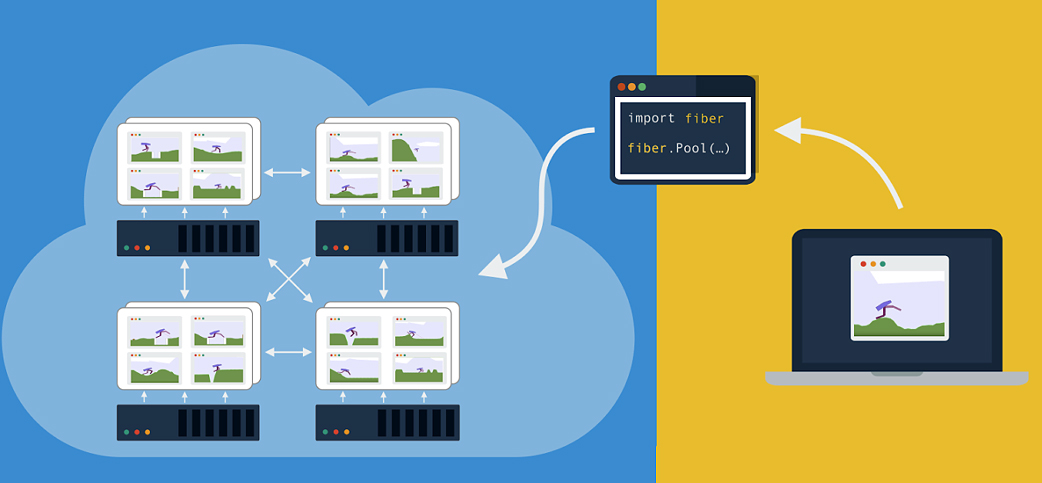
지난 몇 년 동안 머신러닝 발전과 더불어 컴퓨팅 처리 능력은 대폭 향상되고 있다. 점점 더 많은 알고리즘이 병렬 처리를 활용하고 분산된 학습을 통해 엄청난 양의 데이터를 처리하는 것이다.
그러나 결과적으로 데이터와 학습을 모두 늘려야하므로 대규모 계산 리소스를 관리하고 사용하는 소프트웨어에 큰 문제가 발생하는 것이 또 다른 과제로 떠오르고 있다.
우버(Uber)에서는 신경망에서 모델을 훈련시키기 위해 많은 양의 계산을 활용하는 POET(Paired-Ended Trailblazer), Go-Explore 및 GTN(Generative Teaching Networks) 과 같은 알고리즘을 개발했다.
이와 같은 알고리즘에 대한 대규모 계산을 가능하게하기 위해 우버는 사용자가 로컬 계산 방법을 수백 또는 수천 대의 머신으로 쉽게 확장할 수 있는 새로운 분산 컴퓨팅 라이브러리 인 '파이버(Fiber)'를 최근 오픈소스로 공개했다.
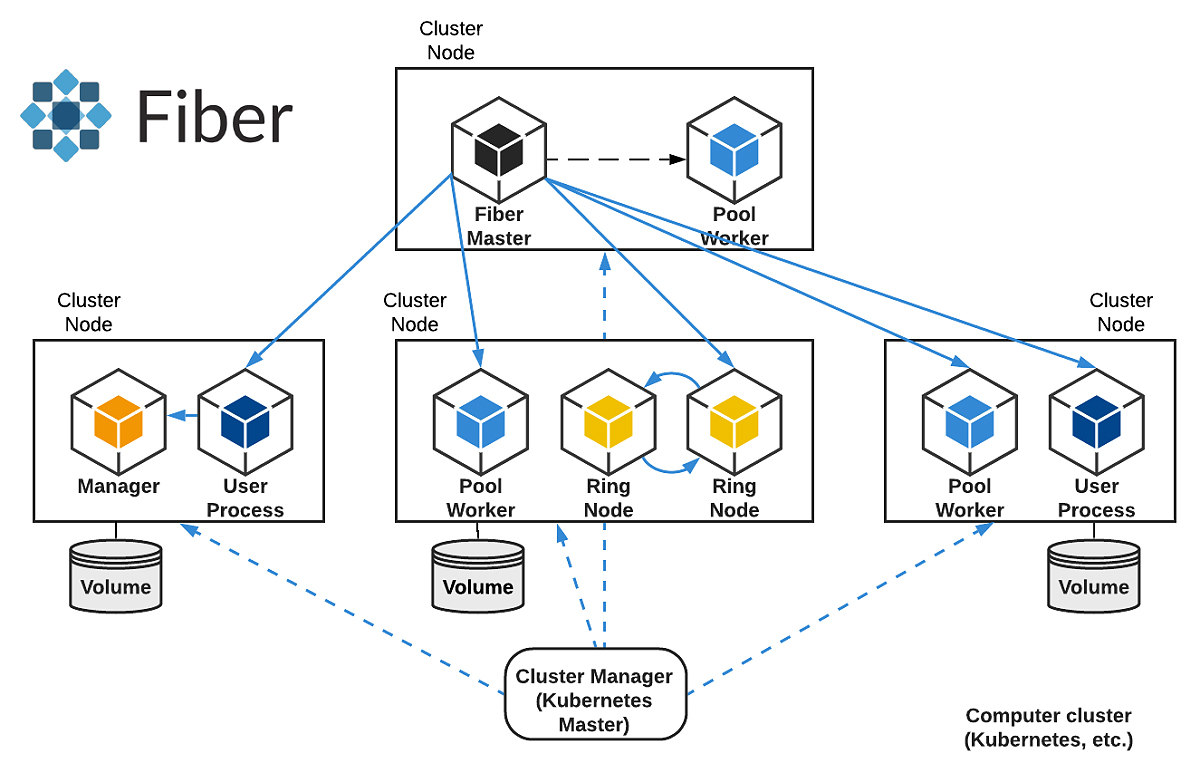
파이버는 파이썬(Python)을 사용하여 대규모 컴퓨팅 프로젝트에 전력을 빠르고, 쉽고, 효율적으로 제공하여 머신러닝 모델 학습 프로세스를 단순화하고 최적의 결과를 이끌어낸다. 최신 컴퓨터 클러스터를 위한 파이썬 기반 분산 컴퓨팅 라이브러리다.
컴퓨터에서 실행되는 응용 프로그램을 컴퓨터 클러스터에서 실행되는 응용 프로그램으로 확장하는 것은 아주 쉬워야한다. 그러나 이것은 현실 세계에서 그렇게 쉬운 일이 아니다. 대규모 분산 컴퓨팅 작업을 실행하는 많은 사람들이 분산 컴퓨팅을 활용하기가 어려운 몇 가지 이유가 있다.
랩톱 또는 데스크톱에서 로컬로 코드를 작동시키는 것과 프로덕션 클러스터에서 코드를 실행하는 것에는 큰 차이가 있다. MPI(Message Passing Interface)를 로컬에서 작동 시 킬 수 있지만 컴퓨터 클러스터에서 MPI를 실행하는 것은 완전히 다른 프로세스다.
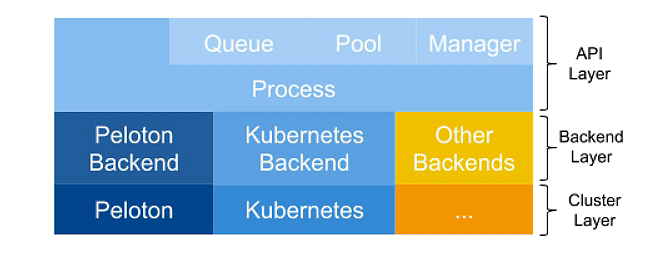
이는 동적 스케일링을 사용할 수 없으며, 많은 양의 리소스가 필요한 작업을 시작하면 모든 작업이 할당 될 때까지 기다려야 작업을 실행할 수 있다. 이 대기 시간은 확장 효율성을 떨어뜨린다. 또 실행 중에 일부 작업이 실패할 수 있다. 이로 인해 결과의 일부를 복구하거나 전체 실행을 버릴 수 있다.
또한 높은 학습 비용과 각 시스템에는 프로그래밍에 대한 서로 다른 API 및 규칙으로 새로운 시스템으로 작업을 시작하려면 완전히 새로운 규칙을 습득해야 한다.
이 새로운 파이버 플랫폼은 이러한 각 문제를 구체적으로 해결한다. 그렇게 하면 훨씬 더 많은 사용자가 원활하게 대규모 분산 컴퓨팅을 수행할 수 있는 것이다.
단일 데스크톱 또는 랩톱 만 프로그래밍하는 대신 이 시스템을 사용하여 전체 컴퓨터 클러스터를 프로그래밍 할 수 있다. 원래 POET(페어링 엔드 트레일블레이저)와 같은 대규모 병렬 과학 계산 프로젝트를 지원하기 위해 개발 되었으며 우버는 이를 사용하여 유사한 프로젝트를 수행했다.
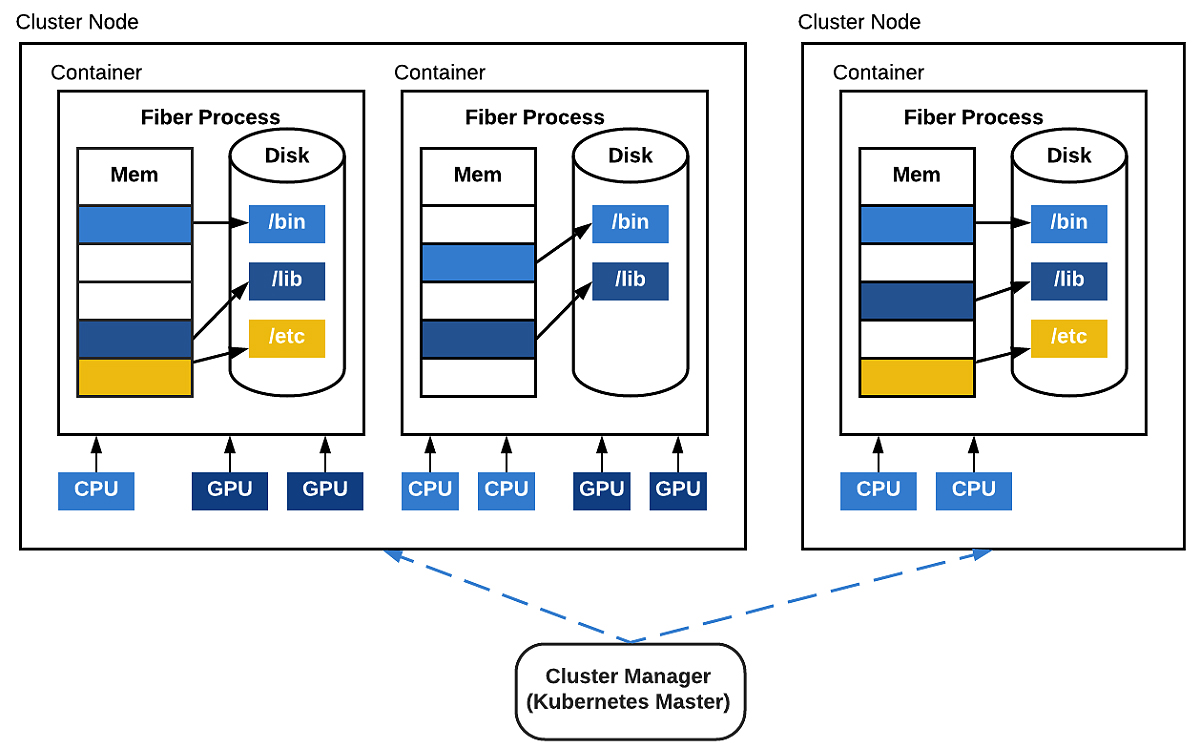
특히, 파이버는 사용하기 쉽다. 파이버를 사용하면 컴퓨터 클러스터의 세부 정보를 확인할 필요 없이 컴퓨터 클러스터에서 실행되는 프로그램을 작성할 수 있으며, 파이썬 표준 멀티 프로세싱 라이브러리와 동일한 API를 제공한다. 멀티 프로세싱을 사용하는 방법을 알고 있는 엔지니어는 파이버를 사용하여 컴퓨터 클러스터를 보다 쉽게 프로그래밍 할 수 있다.
또한 통신 백본은 빠르고 안정적인 통신을 가능하게 하는 고성능 비동기 메시징 라이브러리 (Nanomsg) 위에 구축되며, 별도로 배포가 필요하지 않다. 파이버는 컴퓨터 클러스터에서 일반 응용 프로그램과 같은 방식으로 실행되므로 사용자를 위한 리소스 할당 및 통신을 자동으로 처리하며 임베디드 된 오류 처리 기능을 통해 사용자는 충돌을 처리하는 대신 실제 응용 프로그램 코드 작성에 집중할 수 있다. 이것은 작업자 풀을 실행할 때 특히 유용하다.
이러한 이점 외에도 파이버는 중요한 영역에서 다른 특수 프레임 워크와 함께 사용할 수 있다. 예를 들어, SGcha(Stochastic Gradient Descent)의 경우 파이버 Ring 기능은 컴퓨터 클러스터에서 분산 교육 작업을 설정하여 우버의 오픈 소스 분산 딥러닝 프레임 워크 인 호로보드(Horovod) 또는 분산 통신 패키지(torch.distributed) 와 함께 작동할 수 있다.
한편 우버의 AI를 위한 파이썬 기반 분산 컴퓨팅 라이브러리 '파이버(Fiber-다운)' 오픈소스는 깃허브를 통해 다운로드 할 수있으며 누구나 사용할 수 있다.