사람들이 물리적 세계에서 다양하고 복잡한 작업을 수행하는 데 도움이 될 수 있게 구현된 AI 시스템 및 AI 비서 구축의 진전을 가속화할 수 있기를...

페이스북 AI 연구원들이 사실적인 음향으로 3D 환경에서 인공지능(AI) 에이전트를 훈련할 수 있도록 설계된 새로운 오디오 시뮬레이션 플랫폼 '사운드스페이스(SoundSpaces)'를 오픈 소스로 공개했다. 이 에이전트는 시각뿐만 아니라 소리를 통해 탐색할 수 있다.
세계 최초의 이 시청각 플랫폼 사운드스페이스는 실제 스캔 환경에서 나오는 거의 모든 음원에 대한 높은 충실도와 사실적인 시뮬레이션을 삽입할 수 있는 새로운 오디오 센서를 제공한다. 페이스북 AI의 AI 해비타트 시뮬레이션 플랫폼(Habitat simulation platform) 위에 구축됐으며, 공개된 플랫폼은 두 세트로 3D 환경 마트포트3D(Matterport3D)와 복제본 데이터세트의 오디오 렌더링을 포함하고 있다.
구체화 된 에이전트의 한계를 더욱 넓힐 수있는 중요한 기능을 소개하는 몇 가지 새로운 이정표로 이 연구는 자기 중심적 관점 또는 다중 모드 신호에서 더 복잡하고 현실적인 공간을 탐색하고 이해하는 방법을 학습하고 구현하는 에이전트인 것이다.
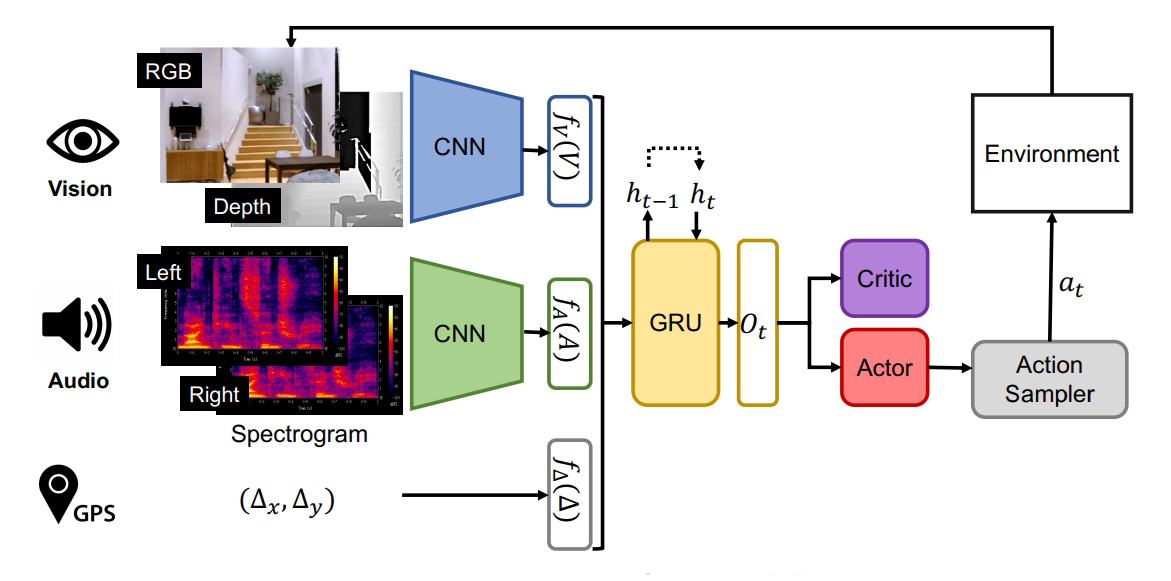
연구진은 이 새로운 플랫폼을 통해 매우 사실적인 음향으로 3D 환경에서 AI 요원을 양성할 수 있다. 이를 통해 음향 발생 대상 탐색, 동물이 소리 또는 초음파를 발생시켜 그 반향으로 방향을 정하는 반향정위(反響定位, echolocation), 멀티모달 센서 탐색 등 새롭게 구현된 AI 과제가 줄줄이 풀린다.
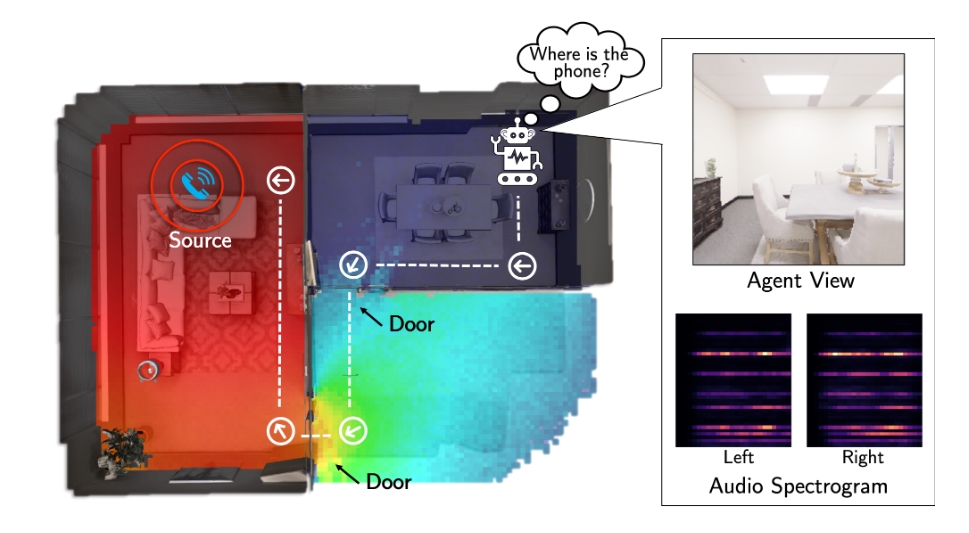
소리 추가는 단순히 수율만 있는 것이 아니다. 더 빠른 훈련과 더 정확한 추론 탐색은 물론, 에이전트가 멀리서도 스스로 목표를 발견(감지)할 수 있게 해준다. 사운드스페이스는 예를 들어, 소파 뒤에 대상물이 있더라도 음원을 식별하고 그쪽으로 이동하거나 이전에 들어 본적이 없는 소리에 응답하도록 에이전트를 학습할 수 있다. 또한 연구팀은 향후 작업을 촉진하기 위해 페이스북의 AR·VR 연구소 FRL(Facebook Reality Labs)와 협력했다.
또한 학습할 수 있는 엔드 투 엔드 프레임워크로 자기중심적 관찰로부터 하향식 의미 맵(물체가 위치한 위치)과 주피오-추적 메모리(정신적 맵)를 구축한다. 이 새로운 에이전트가 투어 중 보이는 물체를 탐색하는 방법(예: 테이블 찾기)이나 공간에 대한 질문(예: 집안에 의자가 몇 개 있는지)에 대해 배우고 추론할 수 있다.
AI 커뮤니티가 작업을보다 쉽게 재현하고 구축 할 수 있도록 Facebook AI 연구원은 사전 계산 된 오디오 시뮬레이션을 제공하여 Matterport3D 및 복제 데이터 세트(Replica Dataset- 논문)에서 즉석 오디오 감지를 허용한다. 페이스북의 오디오 시뮬레이터로 이러한 AI Habitat(보기) 호환 3D 자산을 확장함으로써 연구원들은 효율적인 Habitat API(다운)를 활용하고 AI 에이전트 교육을 위해 오디오를 쉽게 통합할 수 있다. 더 자세한 AI 시청각 플랫폼 '사운드스페이스'는 아래 논문을 참고하면 된다.
한편, 마트포트3D(Matterport3D- 다운)는 90 개의 건물 규모 장면에 대한 194,400 개의 RGB-D 이미지에서 10,800 개의 파노라마 뷰를 포함하는 대규모 RGB-D 데이터 세트이다. RGB-D 이미지는 컬러 이미지(빨간색, 녹색, 파란색)를 해당 깊이 이미지와 결합하여 사실적인 이미지를 생성하는 이미지이다. 복제 데이터 세트(Replica Dataset- 다운)은 실내 공간을 고품질로 재구성 한 세트이다.
연구팀은 '사운드스페이스(SoundSpaces- 다운)'를 오픈 소스로 AI 커뮤니티와 공유함으로써 우리는 사람들이 물리적 세계에서 다양하고 복잡한 작업을 수행하는 데 도움이 될 수 있게 구현된 AI 시스템 및 AI 비서 구축의 진전을 가속화할 수 있기를 바란다고 당부했다. 이 연구 결과 논문은 지난 21일 아카이브(다운)를 통해 '사운드스페이스: 시청각 내비게이션 3D 환경에서(SoundSpaces: Audio-Visual Navigation in 3D Environments)'이란 제목으로 공개됐다.