페이스북 AI의 이 프레임워크 WyPR은 3D 딥러닝 기법으로 입력에서 포인트 레벨 특징 표현을 추출하고 객체 분할을 위해 각 포인트를 객체 클래스로 분류한다. 학습을 위해 다중인스턴스 러닝(MIL)을 사용한다.

보여지는 시각에 어떤 물체가 있고, 어디에 무엇이 있는지? 인식하고 이해하는 것은 컴퓨터 비전의 기본 작업으로 자율주행차에서 로봇, 증강현실(AR) 등에 이르기까지 다양한 분야에 널리 사용되고 있다.
이러한 시스템이 3D 공간을 인식하도록 훈련하는 것은 일반적으로 센서(종종 3D 센서)를 사용하여 장면을 캡처 한 다음 3D 박스에 위치 표시를 포함하여 장면에서 객체의 공간 범위에 레이블을 지정하는 것을 포함한다.
이는 인공지능(AI) 모델을 학습시키는 가장 대중적이자 강력한 방법이지만 수동 라벨링은 매우 시간이 많이 걸린다. 평균적으로 작은 실내 3D 장면에서 라벨링은 보통 20분 이상이 걸린다고 한다. 3D 장면에 레이블을 지정하는 것은 박스 없이 장면에 있는 객체 목록과 같은 장면 수준 레이블 모음을 사용하여 훨씬 빠르고 쉽게 수행할 수 있을 것이다.
지난 14일 공개된 페이스북 AI 연구에서는 훈련 중 장면 레벨 태그(예: 장면에 존재하는 객체 목록)만을 감독으로 사용하여 3D 데이터(예: 포인트 클라우드)에서 공간 인식(예: 객체를 감지하고 세그멘팅)을 수행할 수 있는가? 에 연구팀은 포인트 클라우드 인식을 위한 약하게 감독되는 프레임워크 인 WyPR을 발표했다.
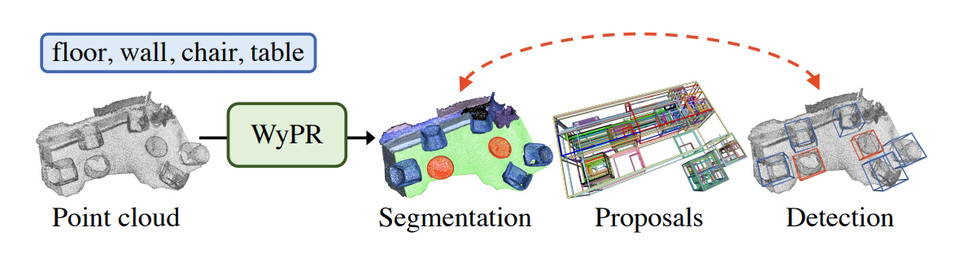
WyPR은 포인트 레벨 의미 분할, 3D 제안 생성 및 3D 객체 감지라는 세 가지 핵심 3D 인식 작업을 공동으로 해결하여 자체 및 교차 작업 일관성 손실을 통해 예측을 결합한다.
WyPR이 표준 다중 인스턴스 학습 목표와 함께 훈련 시간에 공간 레이블에 접근하지 않고도 포인트 클라우드 데이터에서 객체를 감지하고 분할할 수 있음을 보여줬으며, 스탠포드대, 프린스턴대, 뮌헨기술대의 풍부한 주석이 달린 실내 장면의 3D 재구성 프레임워크 ScanNet(다운) 및 S3DIS(Stanford 3D Indoor Scene Dataset- 보기) 데이터 세트를 사용하여 그 효과를 입증하여 약하게 감독되는 분할에 대한 이전 상태를 6% mIoU 이상 능가하는 것으로 확인됐다.
또한, 연구팀은 두 데이터 세트에서 약하게 감독되는 3D 객체 감지를 위한 첫 번째 벤치마크를 설정하는데, 여기서 WyPR은 표준 접근 방식을 능가하고 향후 작업을 위한 강력한 기준선을 확립했다.
이는 자연스럽게 서로를 구속하는 세분화와 탐지의 두 가지 과제를 공동으로 다루면서 이 약하게 감독된 문제 설정에 대한 효과적인 표현을 배울 수 있음을 보여준 것으로 자연스럽게 서로를 구속하는 분할과 검출이라는 두 가지 작업을 공동으로 처리함으로써, 이 약하게 감독되는 문제 설정에 대한 효과적인 표현을 학습할 수 있음을 보여준다.
이 프레임워크 WyPR은 먼저, 표준 3D 딥러닝 기법을 사용하여 입력에서 포인트 레벨 특징 표현을 추출한다. 또, 객체 분할을 얻으려면 각 포인트를 객체 클래스로 분류한다. WyPR은 네트워크의 이 부분을 훈련시키기 위해 포인트 수준의 감독을 가정하지 않기 때문에, 학습을 위해 자체 감독 목표(예: 입력의 증강된 관점에 걸쳐 예측이 일관성이 있어야 함)와 함께 다중인스턴스 러닝(Multiple-Instance Learning, 이하, MIL- 논문 다운)을 사용한다.
그런 다음, 객체 경계 박스를 얻기 위해 선택적 검색에서 영감을 얻어 기하학적 선택적 검색(Geometric Selective Search, GSS)이라고 불리는 연구팀의 새로운 3D 객체 제안 기법을 활용한다. 각 제안은 이전과 같이 MIL을 사용하는 객체 클래스 중 하나로 분류되며, 이와 유사한 자체 감독 손실도 포함된다.
마지막으로, WyPR은 분할 및 탐지 하위 시스템에 의해 만들어진 예측에 걸쳐 일관성을 적용한다. 예를 들어, 탐지된 경계 박스 내의 모든 포인트가 박스 레벨 예측과 일치하도록 시행한다. 아래 그림은 전체 과정을 보여준다.

결론적으로 아래 이미지 시맨틱 분할 결과에서 알 수 있듯이 WyPR은 포인트 수준에서 레이블이 지정된 장면을 보지 않고도 장면에서 객체를 상당히 잘 감지하고 분할할 수 있는 것이다. 또, WyPR은 기준선 및 벤치마크 설정을 포함하여 약하게 감독되는 3D 감지 문제 설정을 공식화하여 이 영역에서 향후 연구에 박차를 가할 것으로 예상된다.

예를 들어, 서비스 로봇이 노인이 다른 방에서 물건을 가져오는 것을 도와야 할 때나 AR 장치를 통해 누군가의 식탁에 앉아 있는 동료들을 투영할 때와 같은 다양한 하류 작업에 공간 3D 장면 이해는 매우 중요하다. WyPR은 모델에게 매우 시간이 많이 걸리는 과정인 포인트 레벨에서 레이블이 지정된 학습과정이 필요 없이 공간 3D 이해 능력을 제공한다.
이처럼 WyPR은 훈련 데이터 장벽을 낮추고 더 많은 수의 수업에 대해 더 세밀한 이해를 가능하게 함으로써 공간 3D 장면 이해를 훨씬 더 쉽게 할 수 있게 하여 이전에 상상했던 경험을 현실에 한걸음 더 다가간 것이다. 페이스북 AI 연구팀의 이 연구 결과(다운)는 지난 13일 아카이브를 통해 발표됐으며, 이 프레임워크는 WyPR 프로젝트 홈페이지(보기)를 통해 곧 오픈소스로 공개될 예정이다.