구글 AI 연구팀의 이 새로운 XMC-GAN 플랫폼은 대조적 손실(Contrastive Losses)을 사용하여 시행된다. 다른 GAN과 마찬가지로 이미지를 합성하는 생성기와 실제 이미지와 생성된 이미지 사이의 비평가 역할을 하도록 훈련된 판별기가 포함되어 있다.

텍스트 설명만으로 이미지를 생성하도록 모델을 학습하는 자동 텍스트 대 이미지(Text-to-Image) 합성은 최근 상당한 관심을 받고 있는 어려운 작업이다. 이 연구는 머신러닝(ML) 모델이 시각적 속성을 캡처하고 텍스트와 관련시키는 방법에 대한 풍부한 통찰력을 제공한다.
스케치(Sketche), 객체 마스크(Object Masks) 또는 마우스 트레이스(Mouse Traces)와 같은 이미지 생성을 안내하는 다른 종류의 입력과 비교할 때, 설명 문장은 시각적 개념을 표현하는 더 직관적이고 유연한 방법이다.
따라서 강력한 자동 텍스트 대 이미지 생성 시스템은 신속한 콘텐츠 생성을 위한 유용한 도구가 될 수 있으며, 머신러닝을 통해 예술의 창작에 통합하고 창작 과정에서 도구로서의 텐서플루우(TensorFlow) 기반의 오픈 소스 파이썬(Python) 라이브러리로 오픈 소스인 마젠타(Magenta-다운) 등과 마찬가지로 다른 많은 창의적인 애플리케이션에 적용할 수 있다.
최첨단 이미지 합성 결과는 일반적으로 두 가지 모델을 훈련시키는 생성적 적대 신경망(Generative Adversarial Network. 이하, GAN)으로 현실적인 이미지를 만들려는 생성기·생성자(G, Generator), 그리고 이미지가 실제인지 조작되었는지를 결정하려는 판별기·판별자(D, Discriminator)로 두 모델은 서로 경쟁하면서 서로에게 영향을 미치면서 고도화 된다.
생성기는 노이즈로부터 어떠한 결과물을 만들어내는데, 이 결과물은 분류기에 의해서 평가되며, 판별기는 생성기로부터 온 결과물과 실제 데이터(Real Data)를 구분해내는 역할을 한다.
많은 텍스트-이미지 생성 모델은 의미론적으로 관련된 이미지를 생성하기 위해 텍스트 입력을 사용하여 조건화되는 GAN으로 이는 특히, 길고 모호한 설명이 제공되는 경우 상당히 어렵다.
게다가 GAN 훈련은 생성기가 제한된 출력 세트만을 생성하는 것을 배우는 훈련 과정의 일반적인 이상 사례인 모드 축소(Mode Collapse-보기)가 발생하기 쉽기 때문에 판별기는 조작된 이미지를 인식하기 위한 강력한 전략을 학습하지 못한다.
모드 축소를 완화하기 위해 일부 접근법은 이미지를 반복적으로 정제하는 다단 정제 네트워크(Multi-Stage Refinement Retworks- 다운)를 사용한다. 또한 GAN 훈련은 모드 축소를 일으키기 쉽고, 이는 생성자가 제한된 출력 세트만 생성하는 방법을 학습하여 판별자가 조작된 이미지를 인식하는 강력한 전략을 학습하지 못하는 훈련 프로세스의 일반적인 실패 사례이다.
그러나 이러한 시스템은 단순한 단일 단계 종단 간 모델보다 효율성이 떨어지는 다단계 훈련을 필요로 한다. 다른 노력은 최종적으로 실제 이미지를 합성하기 전에 객체 레이아웃을 먼저 모델링하는 계층적 접근 방식에 의존한다. 이를 위해서는 레이블이 지정된 분할 데이터를 사용해야 하므로 얻기 어려울 수 있다.
여기에, 구글 AI 연구팀이 텍스트-이미지(Text-to-Image) 생성을 위한 교차 모드 대조 학습에서, 인터 모달(이미지-텍스트)과 인트라 모달(이미지-이미지) 대조를 이용하여 이미지와 텍스트의 상호 정보를 극대화하기 위해 학습하여 텍스트-이미지 생성을 처리하는 '교차 모달 대조 생성적 적대 신경망(Cross-Modal Contrastive Generative Adversarial Network. 이하, XMC-GAN)을 개발해 제시했다.
특히, 이번 연구에서는 미시간 대학교(University of Michigan) 교수이자 LG AI 연구소(LG AI Research) 수석 부사장 겸 최고 AI 사이언티스트(CSAI, Chief Scientist of AI)로 구글 AI 연구조직 ‘구글 브레인’ 핵심 멤버인 이홍락 교수가 공동으로 참여했다.

이 접근 방식은 판별자가 보다 강력하고 차별적인 특징을 학습하는 데 도움이 되므로 XMC-GAN은 1단계 훈련에서도 모드 축소의 위험이 적다. 중요한 것은 XMC-GAN은 이전의 다단계 또는 계층적 접근 방식과 비교하여 단순한 1단계 생성으로 최첨단 성능을 달성한다는 것이다. 종단 간 학습이 가능하며 (레이블된 분할 또는 경계 박스 데이터와 달리), 영상 텍스트 쌍만 필요로 한다.
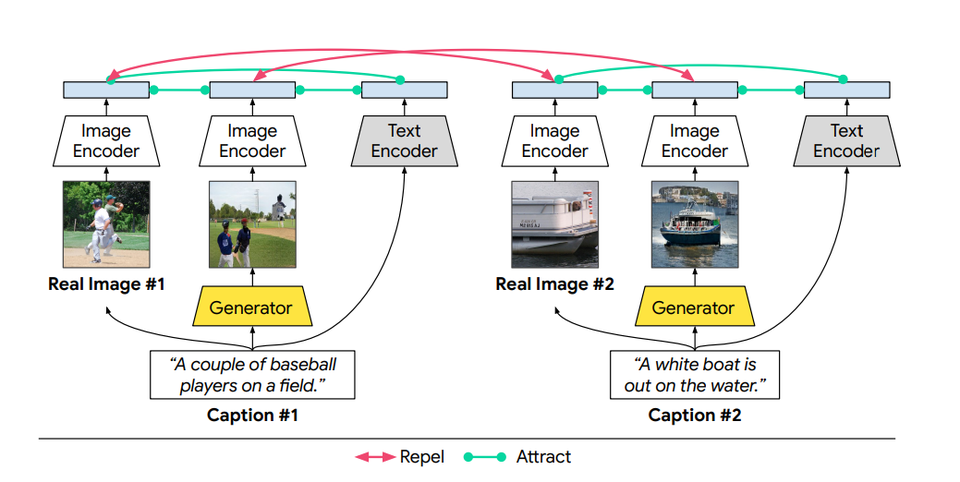
여기서, 텍스트-이미지 합성 시스템의 목표는 조건화된 텍스트 설명에 대한 높은 의미 충실도를 가진 선명하고 사실적인 장면을 생성하는 것이다. 이를 달성하기 위해 연구팀은 ▷장면을 설명하는 문장으로 이미지(실제 또는 생성됨), ▷생성된 이미지와 동일한 설명을 가진 실제 이미지, ▷이미지의 영역(실제 또는 생성됨)과 관련된 단어 또는 구(Phrases) 등 해당 쌍 간의 상호 정보를 최대화하는 것이다.
XMC-GAN에서는 대조적 손실(Contrastive Losses)을 사용하여 시행된다. 다른 GAN과 마찬가지로 XMC-GAN에는 이미지를 합성하는 생성기와 실제 이미지와 생성된 이미지 사이의 비평가 역할을 하도록 훈련된 판별기가 포함되어 있다.
▷실제 이미지, ▷해당 이미지를 설명하는 텍스트, ▷텍스트 설명에서 생성 된 이미지 등 세 가지 데이터 세트가 이 시스템에서 대조적인 손실에 기여한다. 생성기와 판별기 모두에 대한 개별 손실 함수는 전체 이미지에서 계산 된 손실과 전체 텍스트 설명의 조합이며, 관련 단어 또는 구문이 있는 세분화 된 이미지에서 계산 된 손실과 결합된다.
그런 다음, 학습 데이터의 각 배치에 대해 각 텍스트 설명과 실제 이미지 사이의 마찬가지로 각 텍스트 설명과 생성 된 이미지 배치 사이의 코사인 유사성 점수를 계산한다. 여기서 목표는 일치하는 쌍 (텍스트-이미지 및 실제 이미지-생성 이미지 모두)이 높은 유사성 점수를 갖고 일치하지 않는 쌍이 낮은 점수를 갖는 것이다. 이러한 대비 손실을 적용하면 판별자가 더 강력하고 차별적인 특징을 학습할 수 있다.
연구팀은 XMC-GAN을 세 가지 도전적인 데이터 세트에 적용했다. 첫 번째는 MS-COCO 이미지(다운)에 대한 설명 모음이었고, 다른 두 개는 로컬화 된 내러티브(Localized Narratives-다운)로 주석이 달린 데이터 세트였으며, 그 중 하나는 MS-COCO 이미지(LN-COCO라고 함)를 다루고 다른 하나는 오픈이미지(Open Images-다운) 데이터를 설명한다.
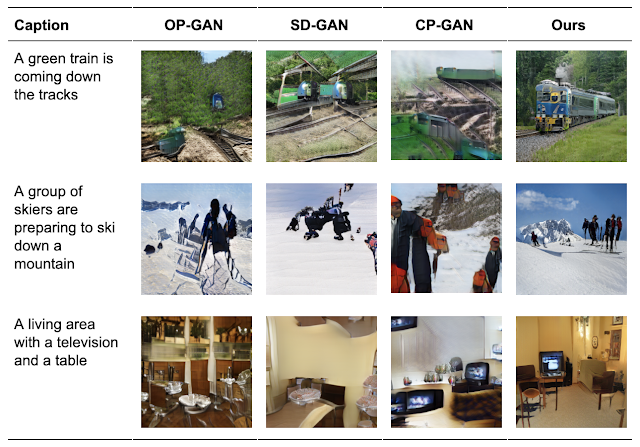
연구팀은 또한 XMC-GAN이 각각에 대해 새로운 상태를 달성한다는 것을 발견했다. XMC-GAN에서 생성 된 이미지는 다른 기술을 사용하여 생성된 것보다 더 높은 품질의 장면을 묘사했다. MS-COCO에서 XMC-GAN은 최첨단 FID (Fréchet Inception Distance) 점수를 24.7에서 9.3으로 향상시켰다.
XMC-GAN은 또한 더 길고 상세한 설명을 포함하는 도전적인 극소화된 내러티브 데이터 세트에 잘 일반화된다. 우리의 선행 연구인 TRECS는 이미지 생성 품질을 향상시키기 위해 마우스 추적 입력을 사용하여 국소화된 내러티브를 위한 텍스트 대 이미지 생성을 다룬다.
또한 XMC-GAN은 마우스 추적 주석을 받지 못함에도 불구하고 LN-COCO에서 이미지 생성에서 TRECS를 크게 능가하여 최신 FID를 48.7에서 14.1로 향상시킬 수 있었다. XMC-GAN과 같은 엔드 투 엔드 모델에 마우스 추적과 기타 추가 입력을 통합하는 것은 향후 연구에서 흥미롭게 진행될 것으로 보인다.
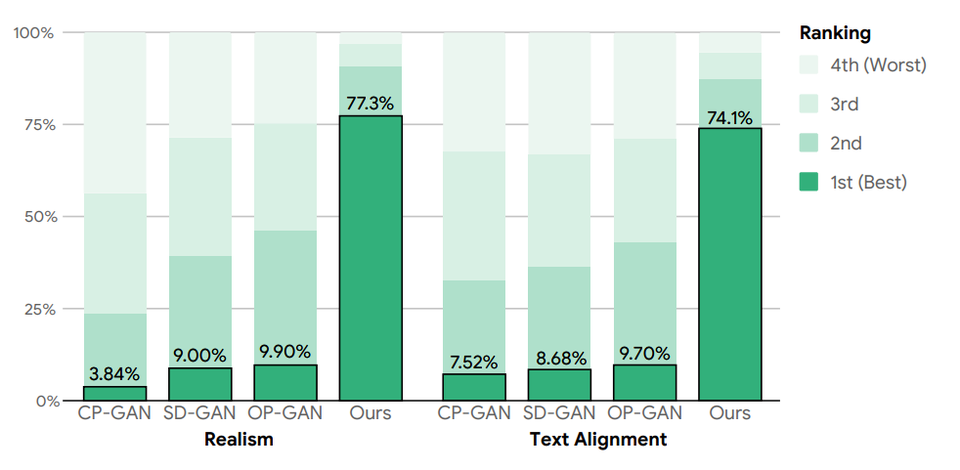
결론적으로 연구팀은 텍스트-이미지 합성을 위한 GAN 모델을 훈련하기 위한 최초의 교차 모달 대비 학습 프레임 워크로 이미지와 텍스트 간의 대응을 강화하는 몇 가지 모델 간 대비 인간 평가와 정량적 지표 모두에서 XMC-GAN은 여러 데이터 세트에서 이전 모델에 비해 현저한 개선을 보였다. 길고 상세한 내러티브를 포함하여 입력 설명과 잘 일치하는 고품질 이미지를 생성하며, 더 간단하고 종단 간 모델인 것이다.
한편, 구글 AI 연구팀의 이 새로운 '텍스트-이미지 생성을 위한 교차 모달 대조 학습(Cross-Modal Contrastive Learning for Text-to-Image Generation-다운)' 연구 결과는 오는 6월 19일부터 25일까지 미국 테네시 내슈빌에서 가상으로 열리는 글로벌 최고 수준의 컴퓨터 비전 및 패턴 인식 분야 국제회의 ‘CVPR 2021(IEEE, Conference on Computer Vision and Pattern Recognition)’ 에서 발표된다.