음성 머신러닝 연구의 모든 이점을 모바일 장치에 제공하는 중요한 단계로 현재, 공개 모델, 해당 모델 카드 및 코드를 오픈 소스로 제공해 전세계 연구자 및 개발자들이 인공지능(AI) 음성 애플리케이션을 효율적으로 그리고 책임감 있게 개발할 수 있도록 지원...

머신러닝에서 특징 학습(Feature Learning) 또는 표현 학습(Representation learning)은 시스템이 원시 데이터에서 특징 감지 또는 분류에 필요한 표현을 자동으로 검색 할 수 있도록 하는 일련의 기술로 이것은 머신이 기능을 학습하고 특정 작업을 수행하는 데 사용할 수 있도록 한다.
특히, 표현 학습(Representation learning)은 버트(BERT: 본지 기사 및 모델 다운) 및 알버트(ALBERT- 다운) 등의 자연어처리(NLP)에서 이미지 분석 및 분류(예: 인셉션 레이어/다운 및 SimCLR/다운)에 이르기까지 다양한 다운스트림 작업에 적용할 수 있는 중요한 특징을 식별하기 위해 모델을 훈련시키는 머신러닝의 한 방법이다.
구글 AI는 지난해 음성 표현과 새롭고 일반적으로 유용한 음성 표현 모델 '트릴(이하, TRILL)'을 공개했었다. TRILL은 시간적 근접성을 기반으로 하며 발생하는 음성을, 단어나 문장을 수치화해 벡터 공간으로 표현하는 과정을 의미하는 임베딩(Embedding) 공간에서 시간적 근접성을 포착하는 저차원으로 매핑한다
이 모델 공개 이후, 연구 커뮤니티에서는 연령 분류, 동영상 썸네일 선택 및 언어 식별과 같은 다양한 작업에 TRILL을 사용했다. 그러나 최첨단 성능을 달성 했음에도 불구하고 TRILL과 기타 신경망 기반 접근 방식은 음량, 평균 에너지, 피치 등과 같은 단순한 기능을 처리하는 신호 처리 작업보다 더 많은 메모리를 필요로 하고 계산하는 데 더 오래 걸린다는 과제에 봉착했었다.
이에 구글 AI는 TRILL의 40 %의 크기의 새 모델 프릴(이하, FRILL)과 휴대 전화에서 32배 이상 더 빠르게 계산할 수 있는 기능 세트를 구현했다. 이것은 음성 머신러닝 모델의 완전한 온 디바이스 애플리케이션을 향한 중요한 단계를 의미한다.
여기에, FRILL을 생성하고 텐서플로우 허브(TensorFlow Hub)에서 사전 학습 된 FRILL 모델을 생성하는 플랫폼을 10일(현지시간) 오픈 소스로 공개했다. 이는 구글의 책임감있는 AI (Responsible AI- 보기) 개발의 중요한 측면으로 더 나은 개인화, 개선 된 사용자 경험과 더 확실한 개인 정보 보호로 이어질 것으로 예상된다.
이처럼 더 작고, 더 빨라진 TRIL 아키텍처는 이동 전화나 스마트 홈 디바이스와 같은 제한된 하드웨어에 대해 계산적으로 부담을 주는 아키텍처인 ResNet50의 수정 버전을 기반으로 한다. ResNet50은 휴대폰이나 스마트 홈 디바이스와 같이 한정된 하드웨어에 대해 계산에 부담을 주기 때문이다.
반면에 MobileNetV3와 같은 아키텍처는 모바일 디바이스에서 우수한 성능을 발휘할 수 있도록 하드웨어 인식 AutoML로 설계되었다. 이를 활용하기 위해 '지식 증류(knowledge distillation- 'Distilling the Knowledge in a Neural Network'- 다운)'를 활용하여 MobileNetV3의 성능과 TRIL의 표현의 이점을 결합시켰다.
지식 증류 과정에서는 더 작은 모델(즉, 학생)은 오디오세트(AudioSet- 다운) 데이터 세트에서 더 큰 모델(교사)의 출력과 일치하려고 한다. 원래 TRILL 모델은 오디오 세그먼트를 제 시간에 클러스터링 한 자기 감독(self-supervised) 손실을 최적화하여 가중치를 학습한다(위 논문 참조).
반면, 학생 모델은 시간 일치를 무시하고 대신 훈련 데이터에서 TRILL 출력을 일치 시키려고 시도하는 완전 감독(fully-supervised) 손실을 통해 가중치를 학습한다. 완전 감독 학습 신호는 종종 자기 감독보다 강하며 더 빨리 학습할 수 있게 해준다.
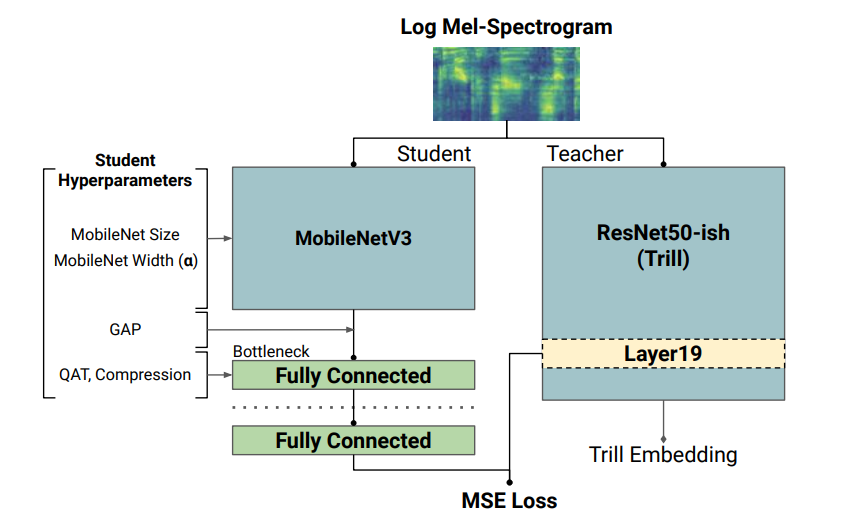
또한 연구팀은 최고의 학생 모델 선택을 위해 다양한 학생 모델을 사용하여 증류를 수행했으며, 각 모델은 특정 아키텍처 선택 조합으로 학습된다. 각 학생 모델의 지연 시간을 측정하기 위해 엣지 디바이스에서 텐서플로우 모델을 실행할 수 있는 프레임워크인 텐서플로우 라이트(TensorFlow Lite-다운. 이하,TFLite)를 활용했다.
각 후보 모델은 32비트 부동 소수점 추론(floating point inference)을 위해 먼저 TFLite의 플랫버퍼(FlatBuffers-다운) 형식으로 변환된 다음 벤치마킹을 위해 대상 장치(이 경우, 픽셀 1)로 전송된다. 이러한 측정은 모든 학생 모델에서 지연 시간과 품질 균형을 정확하게 평가하고 변환 프로세스에서 품질 손실을 최소화하는 데 도움이 됐다.
연구팀은 아키텍처 선택 및 최적화를 위해 대기 시간과 정확성의 균형을 유지하는 다양한 신경망 아키텍처와 기능을 탐색했다. 매개 변수가 적은 모델은 일반적으로 더 작고 빠르지만 표현력이 적기 때문에 일반적으로유용한 표현을 덜 생성한다. 이에 MobileNetV3 아키텍처를 기반으로 여러 초매개변수에서 144 개의 서로 다른 모델을 학습시켰다.
결과적으로 연구팀은 비시맨틱 음성 벤치마크(NOSS. Non-Semantic Speech Benchmark)와 두 가지 새로운 작업에서 이러한 모델 각각을 평가했는데, 이는 화자(사람)가 마스크를 착용하고 있는지와 "기침" 및 "재채기"와 같은 레이블을 포함하는 환경 소리 분류( Environment Sound Classification- 다운) 데이터 세트의 인간 잡음 하위 집합에 대해 평가했다.
또한 엄격히 더 나은 대안을 가진 모델을 제거한 후, 144개의 모델 배치에서 해당 품질 임계값이나 지연시간에서 더 빠르고 더 나은 성능 대안이 없었던 모델인 품질 대 대기 곡선에 8개의 프론티어 모델을 남겨두게 된다. 아래(표)의 모델만의 지연 시간 대 품질 곡선을 표시하고, 엄격히 더 나쁜 모델은 무시했다
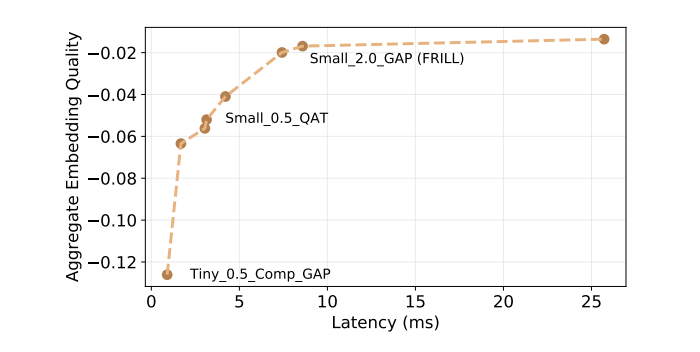
프릴(FRILL)은 Pixel 1에서 추론 시간이 8.5ms (TRILL보다 약 32 배 빠름)로 가장 성능이 좋은 10ms 미만의 추론 모델이며, 또한 TRILL 크기의 약 40%이다. 약 10ms 지연 시간에서 프런티어 곡선이 발생하므로, 짧은 지연 시간에서는 최소의 지연 시간 비용으로 훨씬 더 나은 성능을 달성할 수 있다.
이는 10ms를 초과하는 지연 시간에서는 더 나은 성능을 달성하는 것이 더 어렵다는 것을 의미한다. 이것은 우리가 선택한 실험 하이퍼 파라미터를 지원합니다. FRILL의 작업 별 성능은 아래 표에 나와 있다.
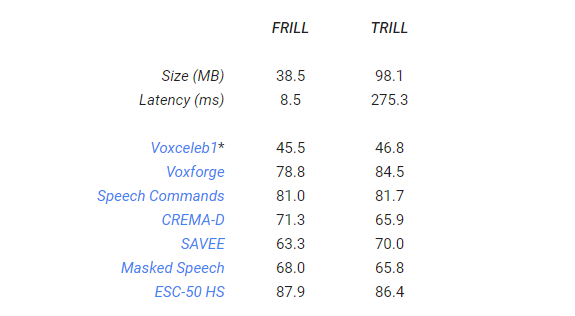
위 표에서 VoxCeleb1은 대규모 화자 식별 데이터 세트로 화자 식별을 위한 대부분의 기존 데이터 세트에는 매우 제한된 조건에서 얻은 샘플이 포함되어 있으며 일반적으로 주석을 달아 크기가 제한된다. 이 연구에서 수집 된 대규모 텍스트는 독립적 화자 식별 데이터 세트를 생성하는 것이다(논문 참조).
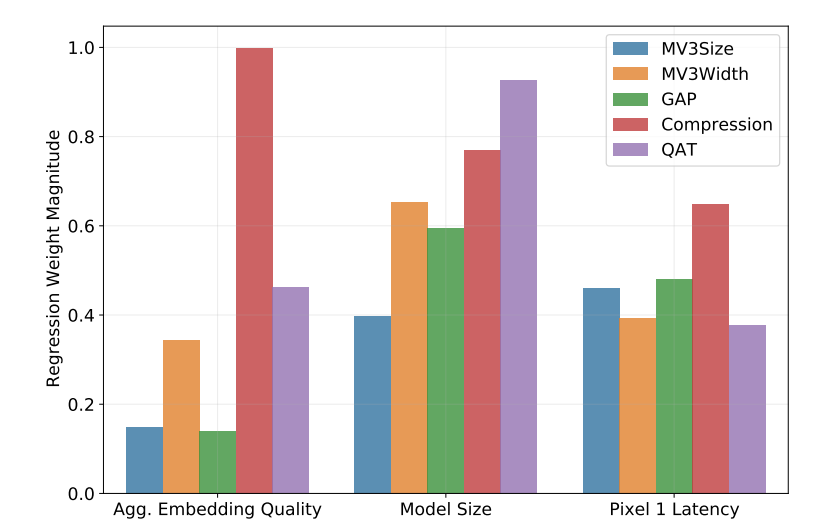
마지막으로 각 초 매개 변수(hyperparameters)의 상대적 기여도를 평가한다. 실험에서 양자화 인식 훈련, 병목 압축 및 글로벌 평균 풀링(pooling)은 결과 모델의 지연 시간을 가장 많이 줄였다. 동시에 병목 압축은 결과 모델의 품질을 가장 많이 떨어 뜨리는 반면 풀링은 모델 성능을 가장 적게 떨어 뜨렸다. 아키텍처 폭 매개변수는 성능 저하를 최소화하면서 모델 크기를 줄이는 데 중요한 요소였다.
한편, 구글 AI의 이번 FRILL 모델 및 연구결과는 오는 8월 30일부터 9월 3일까지 온라인으로 개최되는 세계 최고 음성신호처리 학회 ‘인터스피치 2021(Interspeech)’에서 ‘프릴: 모바일 기기용 비시맨틱 음성 임베딩(FRILL: A Non-Semantic Speech Embedding for Mobile Devices-다운)‘이란 제목으로 발표된다.
또한, 구글 AI의 FRILL은 음성 머신러닝 연구의 모든 이점을 모바일 장치에 제공하는 중요한 단계로 평가된다. 현재, 공개 모델(다운), 해당 모델 카드(다운) 및 코드(다운)를 오픈 소스로 제공해 전세계 연구자 및 개발자들이 온 디바이스 음성 표현 연구와 더 많은 인공지능(AI) 음성 애플리케이션을 효율적으로 그리고 책임감 있게 개발할 수 있도록 지원하고 있다.