3D 주석이 있는 일반 객체 범주의 실제 비디오로 구성된 대규모 데이터 세트 CO3D에는 널리 사용되는 MS-COCO 데이터 세트의 50개 범주에서 객체를 캡처하는 약 19,000개의 비디오에서 총 150만 개의 프레임이 포함

3D로 객체를 재구성하는 것은 인공지능(AI) 뿐만 아니라 텔레프레즌스(Telepresence)에서부터 게임용 3D 모델 생성과 가상 및 증강현실(AR/VR) 응용 프로그램 등까지 중요한 컴퓨터 비전 문제다.
이는 매우 사실적이며, 다재다능한 3D 재구성을 통해 기존 스마트폰 및 노트북 화면은 물론 미래 경험을 뒷받침할 AR 안경에서 실제와 가상 물체를 매끄럽게 결합할 수 있다.
그러나, 현재의 3D 재구성 방법은 다양한 객체 범주(자동차, 도넛, 사과 등)에 대한 학습 모델에 의존하고 실제 세계의 두 이미지를 모두 포함하는 데이터 세트의 부족으로 작업 진행이 지연된다. 이러한 객체는 일반적으로 실제 이미지 특성과 거의 일치하는 합성 객체의 데이터 세트를 사용한다.
이러한 문제를 해소하고 이 분야의 발전을 가속하기 위해 페이스북 AI는 3D 주석이 있는 일반적인 객체 범주의 실제 비디오로 구성된 대규모 데이터 세트인 'CO3D(Common Objects in 3D)'를 2일(현지시간) 오픈 소스로 공개했다.
이 CO3D에는 널리 사용되는 MS-COCO 데이터 세트의 50개 범주에서 객체를 캡처하는 거의 19,000개 비디오의 총 150만 프레임이 포함되어 있다. 이는 CO3D는 범주와 객체의 수면에서 기존 방법을 능가하는 것이다. 또, 페이스북AI는 CO3D 데이터 세트의 영상을 통해 새로운 관점에서 물체의 이미지를 합성하는 방법을 학습하는 새로운 방법인 NeRFormer에 대한 연구도 공유했다.

이를 위해 NeRFormer는 트랜스포머와 뉴럴 래디언스 필드(Neural Radiance Fields)라는 두 가지 최근 머신러닝 기법을 효율적으로 포함시켰다. 따라서 NeRFormer는 객체를 합성하는 데 있어 가장 최근의 방법보다 최대 17% 더 정확하다고 한다.
페이스북 AI의 목표는 3D 모양으로 주석을 단 객체들의 대규모 실제 데이터 세트를 구축하는 것이다. 특정 물체(턴테이블, 3D 스캐너 등)를 수집할 수는 있지만, 이러한 접근 방식은 다양한 범주에 걸쳐 수천 개의 객체로 구성된 가상 데이터 세트의 범위에 맞춰 확장하기가 매우 어렵다.
대신, 페이스북 AI는 객체 중심 멀티뷰 이미지만 요구하는 사진 메트릭 접근 방식을 고안했다. 이러한 데이터는 사용자 스마트폰으로 캡처한 '턴테이블' 동영상을 크라우드 소싱하여 효과적으로 대량으로 수집할 수 있었다.
이를 위해 ‘아마존 메커니컬 터크(Amazon Mechanical Turk. 이하, AMT)’ 플랫폼에서 객체 중심 동영상을 크라우드 소싱했다. 각 AMT 태스크는 작업자에게 지정된 카테고리에 있는 객체를 선택하고 솔리드 표면에 배치한 후 비디오를 녹화하도록 요청하여 해당 범주 주위에 전체 원 방향으로 이동하는 동안 전체 개체를 계속 표시하도록 했다. 이는 형상 개념이 잘 정의되어 있고 성공적인 3D 재구성에 적합한 고정 물체로 구성된 50개의 MS-COCO 범주를 선택했다.
특히, 성숙한 사진 측량 프레임워크인 COLMAP은 3D 공간에서 스마트폰 카메라의 위치를 추적하고 물체의 표면을 캡처하는 조밀한 3D 포인트 클라우드를 추가로 재구성함으로써 실측으로 처리되는 3D 주석을 제공했다. 마지막으로 고품질 3D 주석을 위해 3D 재구성 정확도가 부족한 동영상을 필터링하는 반자동 능동 학습 알고리즘을 개발하고 적용했다.
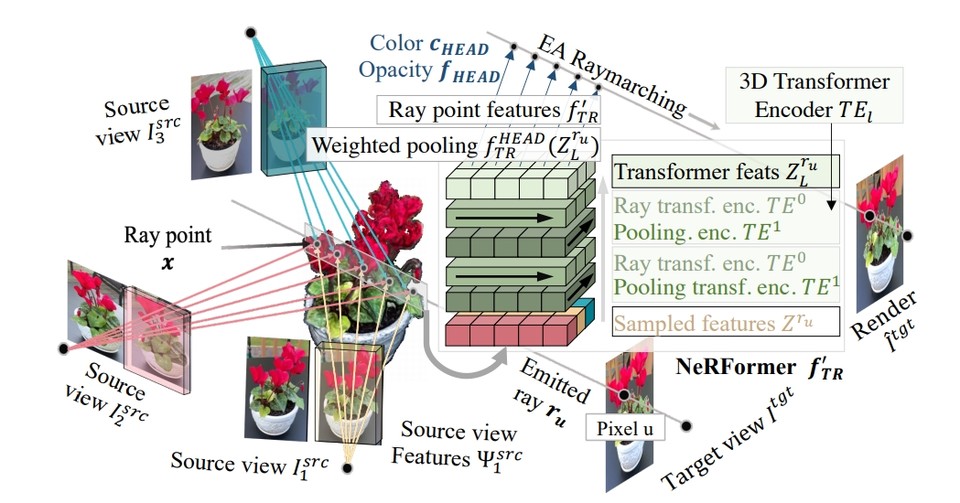
페이스북 AI는 이번 CO3D 데이터셋 공개와 함께 수집된 영상을 관찰하여 객체 카테고리의 기하학적 구조를 학습하는 새로운 딥 아키텍처 NeRformer를 개발하고 적용했다. 학습 중에 NeRformer는 물체의 기하학과 외형을 나타내는 NeRF(neural radiance field)를 구별하게 렌더링 하여 학습한다.
중요한 것은 렌더링이 객체의 비디오 프레임의 내용을 분석하여 복사 필드(radiance field)의 특성을 예측하고 렌더링 광선(rays)을 따라 '마칭(marching, 행진)'하여 새로운 뷰를 렌더링하기 위해 공동으로 학습하는 새로운 딥 트랜스포머(deep Transforme)에 의해 수행된다. 이러한 방식으로 NeRformer가 범주의 공통 구조를 학습하면 알려진 소수의 뷰만 주어졌을 때 이전에 볼 수 없었던 객체의 새로운 뷰를 합성할 수 있다.
CO3D는 이러한 종류의 첫 번째 데이터 세트로서 실제 3D 객체의 재구성을 적절하게 가능하게 해준다. 실제로 CO3D는 이미 NeRFormer가 새로운 시각 합성(new-view synthesis. 이하, NVS) 작업을 처리할 수 있도록 학습 데이터를 제공한다. 여기에서 사실적인 NVS는 완전히 몰입형 AR/VR 효과로 가는 주요 단계로 물체는 가상으로 다양한 환경에 걸쳐 이동할 수 있으며, 이를 통해 사용자의 경험을 공유하거나 기억함으로써 사용자를 연결할 수 있다.
한편, 페이북AI는 이 데이터 세트를 통해 3D 장면을 재구성하는 최근의 방법(NeRFormer, Implicit Differentiable Render, NeRF 등)의 확산에 대한 표준 테스트베드가 되기를 바란다고 밝혔EK.
이 연구의 논문은 '3D의 공통 개체: 실제 3D 범주 재구성의 대규모 학습 및 평가(Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction-다운)'이란 제목으로 지난 1일 아카이브를 통해 공개됐다. 현재, 관련 데이터 세트는 깃허브(다운)를 통해 누구나 다운받아 사용할 수 있다.