영국 케임브리지대, 중국 우환 화중과학기술대, 아스트라제네카 등 50여명의 국제 공동 연구팀이 연합학습 사용해 CT 스캔을 통한 코로나 19 진단과 다른 질병에도 적용할 수 있는 새로운 AI 모델 구축
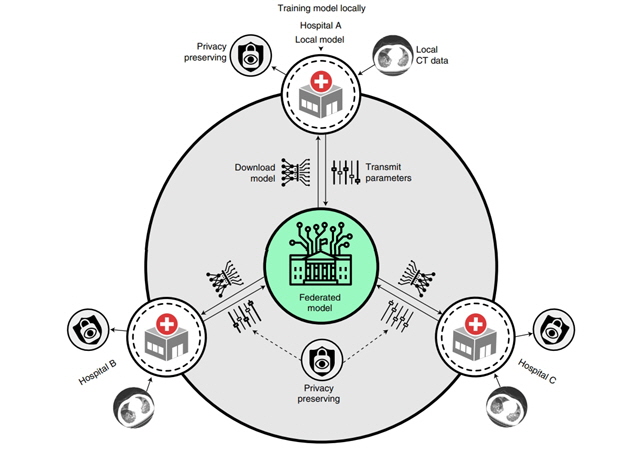
의료 인공지능(AI)에서 연합학습(Federated Learning)은 개인 정보 등 민감한 임상 데이터를 서로 직접 공유할 필요 없이 개발자와 조직이 협업을 통해 여러 위치에 분산된 학습 데이터를 사용하여 심층신경망(DNN Deep Neural Networks)을 훈련시킬 수 있다.
보통 의료 시나리오에 배치된 AI 알고리즘은 궁극적으로 임상 등급의 정확도에 도달해야 한다. 이는 적용되는 응용 프로그램의 표준을 충족하거나 능가한다는 의미인 것이다. 또 의료 전문가와 동일한 등급을 충족하는 모델을 학습하려면 AI 알고리즘에 많은 사례가 제공되어야 한다.
중요한 데이터의 양만이 아니다. 매우 다양해야 하며 성별, 연령, 인구 통계 및 환경 등 각 다른 환자의 샘플을 통합해야 하고 개별 의료 기관에는 수십만 개의 레코드와 이미지가 포함된 아카이브가 있을 수 있지만 이러한 데이터 소스는 일반적으로 사일로로 유지된다. 이는 곧 개인 정보이므로 필요한 환자의 동의와 윤리적 승인 없이는 사용할 수 없기 때문이다.

그러나 연합학습은 개인 정보 등 민감한 임상 데이터를 서로 직접 공유할 필요가 없이 여러 번의 반복 학습 과정에서 공유 모델은 단일 조직이 자체적으로 보유한 것 보다 훨씬 광범위한 데이터를 얻게 되는 것으로 기관에서는 더욱 매력적인 것이다.
즉, 기존 방식과 달리, 사용자가 직접 사용하는 데이터를 처리하고 모델을 강화해, 이 모델을 한 곳에 모아 더 정교한 모델을 만들어 다시 배포하는 방식으로 현재의 데이터 중심 시스템과 비교할 때 기관 데이터를 공유하지 않고도 비슷한 세그멘테이션(segmentation) 성능을 달성할 수 있다.
특히, 희소 벡터 기술(sparse vector technique) 등을 사용하는 연합학습 시스템은 상당히 적은 비용으로 엄격한 개인 정보를 보호할 수 있으며, 개인 데이터를 통해 로컬로 학습된 의료기관 간에 효과적으로 데이터를 집계할 수 있어 심층 모델의 정확성, 견고성 및 일반화 능력을 더욱 향상시킬 수 있는 것이다.
여기에, 영국 케임브리지대학교(University of Cambridge)와 중국 우환(Wuhan)의 화중과학기술대학교(Huazhong University of Science and Technology), 아스트라제네카(AstraZeneca) 등의 50여명의 국제 공동 연구팀이 연합학습을 사용해 COVID-19(코로나 19)를 진단할 수 있는 새로운 인공지능 모델을 구축했다.
연구원들은 연합학습을 사용하여 데이터 공유 없이 영국과 중국의 23개 병원에 있는 약 3,300명의 환자로부터 얻은 9,000건 이상의 CT 스캔 데이터를 기반으로 했다.
인공지능은 의료분야에서 보안 및 신뢰성에 대한 우려로 인해 대규모 의료 데이터 수집이 어려워 특정 국가를 넘어 전 세계적으로 사용할 수 있는 모델을 학습하는 데 어려움이 따른다. 그들의 연구 결과는 특히, 개인 정보가 중요한 의료 진단과 같은 영역에서 AI 기술을 더욱 신뢰할 수 있고 정확하게 만들 수 있는 프레임워크를 제공했다.
COVID-19 대유행 초기에 많은 AI 연구자들이 질병을 진단할 수 있는 모델을 개발하기 위해 노력했다. 그러나 정작 이러한 모델의 대부분은 품질이 낮은 데이터와 '프랑켄슈타인(Frankenstein)' 데이터 세트 및 임상의의 입력 부족을 사용하여 구축되었다. 현재 연구원 중 다수는 이러한 초기 모델이 2021년 봄에 임상 사용에 적합하지 않다고 강조하기도 했다.
연구원들은 모델을 테스트하고 다른 병원이나 국가의 데이터 세트에서 잘 작동하는지 확인하기 위해 적절한 크기의 잘 선별된 두 개의 외부 검증 데이터 세트를 사용했습니다.
공동 저자인 아스트라제네카와 케임브리지 응용 수학 및 이론 물리학과의 마이클 로버츠(Michael Roberts) 박사는 “COVID-19 이전에는 의료 AI 애플리케이션을 구축하기 위해 수집해야 하는 데이터의 양이 얼마나 되는지 알지 못했습니다"라며, "병원마다, 국가마다 고유한 작업 방식이 있으므로 가장 광범위한 임상의에게 유용한 것을 만들기 위해서는 데이터 세트가 최대한 커야 합니다"라고 강조했다.
연구원들은 2차원 이미지 대신 3차원 CT 스캔에 프레임워크를 기반으로 했다. CT 스캔은 훨씬 더 높은 수준의 세부 정보를 제공하여 더 나은 모델을 만들 수 있다. 그들은 정확히 중국과 영국에 위치한 23개 병원에서 수집된 3,336명의 환자로부터 9,573개의 CT 스캔 데이터를 사용했다.
연구원들은 또한 서로 다른 데이터 세트로 인한 편향을 완화해야 했고 연합학습을 사용하여 더 나은 일반화된 AI 모델을 훈련하는 동시에 협업 환경에서 각 데이터 센터의 개인 정보를 보호해야 했다.
공정한 비교를 위해 연구원들은 훈련 데이터와 겹치지 않고 동일한 데이터에서 모든 모델을 검증했으며, 방사선 전문의 패널로 하여금 동일한 CT 스캔 데이터 세트를 기반으로 진단 예측을 하게 하고 AI 모델과 인간 전문가의 정확도를 비교했다.
연구원들은 그들의 모델이 COVID-19뿐만 아니라 CT 스캔을 사용하여 진단할 수 있는 다른 질병에도 유용하다고 밝혔다.
공동 제1저자인 캠브리지 대학의 한첸 왕(Hanchen Wang)은 "다음번에 팬데믹이 발생하고 그럴 것이라고 믿을 만한 충분한 이유가 있을 때 AI 기술을 신속하게 활용하여 새로운 질병을 더 빨리 이해할 수 있는 훨씬 더 나은 위치에 있게 될 것"이라고 말했다.
마이클 로버츠는 "우리는 의료 데이터 암호화가 가능하다는 것을 보여주었으므로 이러한 도구를 구축하고 사용할 수 있으며, 내부 및 외부 경계를 넘어 환자의 개인 정보를 보호할 수 있습니다"라며, “다른 나라들과 협력함으로써 우리는 혼자 할 수 있는 것보다 훨씬 더 많은 일을 효율적으로 할 수 있었습니다”라고 말했다.
한편, 공동 연구팀은 현재 새로 설립된 WHO 전염병 및 전염병 정보 허브(WHO Hub for Pandemic and Epidemic Intelligence)와 협력하고 있으며, 연구 결과는 네이처 머신 인텔리전스(Nature Machine Intelligence) 저널에 '인공지능의 개인 정보 보호 협업으로 COVID-19 진단 향상(Advancing COVID-19 diagnosis with privacy-preserving collaboration in artificial intelligence-다운)'란 제목으로 지난 15일 게재됐다.