신경망 기반 머신러닝과 달리, 데이터 사이의 연관 관계를 표현할 수 있어 페이스북, 구글, 링크드인, 우버 등 대규모 소셜 네트워크 서비스, 내비게이션, 교통 예측 시스템, 신약 개발 등 다양한 분야에서 활용 기대

그래프 자료구조가 적용된 새로운 머신러닝 모델은 기존 신경망 기반 머신러닝 기법들과 달리, 데이터 사이의 연관 관계를 표현할 수 있어 페이스북, 구글, 링크드인, 우버 등, 대규모 소셜 네트워크 서비스(SNS)부터, 내비게이션, 신약개발 등 광범위한 분야와 응용에서 사용된다.
예를 들면 그래프 구조로 저장된 사용자 네트워크를 분석하는 경우 일반적인 머신러닝으로 불가능했던 현실적인 상품 및 아이템 추천, 사람이 추론한 것 같은 친구 추천 등이 가능하다.
이러한 신흥 그래프 기반 신경망 머신러닝은 그간 GPU와 같은 일반 머신러닝의 가속 시스템을 재이용해 연산 되어왔는데, 이는 그래프 데이터를 스토리지로부터 메모리로 적재하고 샘플링하는 등의 데이터 전처리 과정에서 심각한 성능 병목현상과 함께 장치 메모리 부족 현상으로 실제 시스템 적용에 한계를 보여 왔다.
여기에, KAIST(총장 이광형)는 전기및전자공학부 정명수 교수 연구팀(컴퓨터 아키텍처 및 메모리 시스템 연구실)이 세계 최초로 그래프 머신러닝 추론의 그래프처리, 그래프 샘플링 그리고 신경망 가속을 스토리지/SSD 장치 근처에서 수행하는 `전체론적 그래프 기반 신경망 머신러닝 기술(이하 홀리스틱 GNN)'을 개발하는데 성공했다.
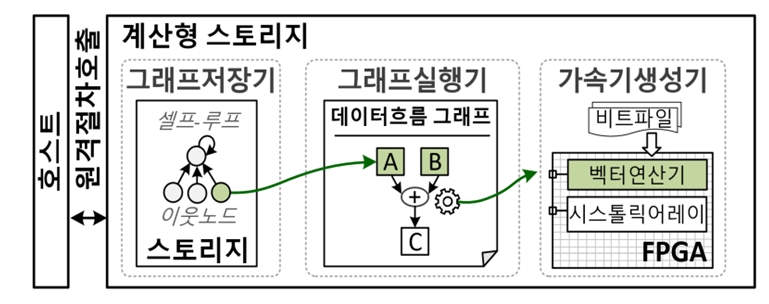
연구팀은 자체 제작한 프로그래밍 가능 반도체(FPGA)를 동반한 새로운 형태의 계산형 스토리지/SSD 시스템에 머신러닝 전용 신경망 가속 하드웨어와 그래프 전용 처리 컨트롤러/소프트웨어를 시제작했다.
특히, 주목할 점은 연구팀은 이상적 상황에서 최신 고성능 엔비디아 GPU를 이용한 머신러닝 가속 컴퓨팅 대비 7배의 속도 향상과 33배의 에너지 절약을 가져올 수 있다는 것이라고 한다.
KAIST 정명수 교수 연구팀이 개발한 홀리스틱 GNN 기술은 그래프 데이터 자체가 저장된 스토리지 근처에서 사용자 요청에 따른 추론의 모든 과정을 직접 가속한다.
구체적으로는 프로그래밍 가능한 반도체를 스토리지 근처에 배치한 새로운 계산형 스토리지(Computational SSD) 구조를 활용해 대규모 그래프 데이터의 이동을 제거하고 데이터 근처(Near Storage)에서 그래프처리 및 그래프 샘플링 등을 가속해 그래프 머신러닝 전처리 과정에서의 병목현상을 해결했다.
일반적인 계산형 스토리지는 장치 내 고정된 펌웨어와 하드웨어 구성을 통해서 데이터를 처리해야 했기 때문에 그 사용에 제한이 있었다.
그래프처리 및 그래프샘플링 외에도, 연구팀의 홀리스틱 GNN 기술은 인공지능 추론 가속에 필요한 다양한 하드웨어 구조, 그리고 소프트웨어를 후원할 수 있도록 다수 그래프 머신러닝 모델을 프로그래밍할 수 있는 장치수준의 소프트웨어와 사용자가 자유롭게 변경할 수 있는 신경망 가속 하드웨어 프레임워크 구조를 제공한다.

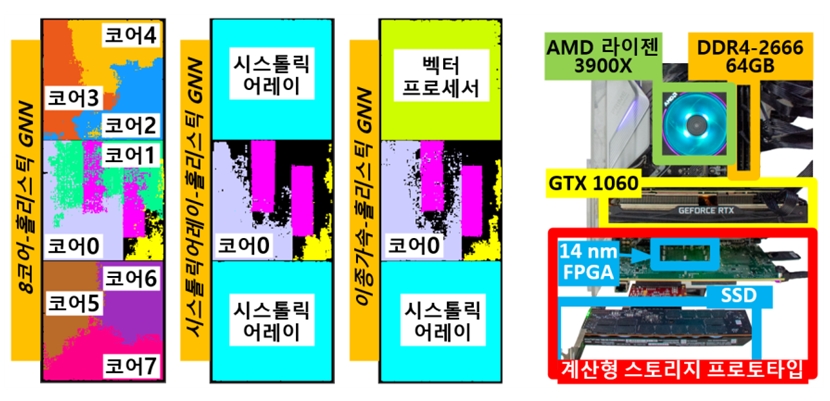
연구팀은 홀리스틱 GNN 기술의 실효성을 검증하기 위해 계산형 스토리지의 프로토타입을 자체 제작한 후, 그 위에 개발된 그래프 머신러닝용 하드웨어 RTL(Registor Transistor Logic)과 소프트웨어 프레임워크를 구현해 탑재했다.
그래프 머신러닝 추론 성능을 제작된 계산형 스토리지 가속기 프로토타입과 최신 고성능 엔비디아 GPU 가속 시스템(RTX 3090)에서 평가한 결과, 홀리스틱 GNN 기술이 이상적인 상황에서 기존 엔비디아 GPU를 이용해 그래프 머신러닝을 가속하는 시스템의 경우에 비해 평균 7배 빠르고 33배 에너지를 감소시킴을 확인했다.
특히, 그래프 규모가 점차 커질수록 전처리 병목현상 완화 효과가 증가해 기존 GPU 대비 최대 201배 향상된 속도와 453배 에너지를 감소할 수 있었다.
정명수 교수는 "대규모 그래프에 대해 스토리지 근처에서 그래프 기계학습을 고속으로 추론할 뿐만 아니라 에너지 절약에 최적화된 계산형 스토리지 가속 시스템을 확보했다ˮ며 "기존 고성능 가속 시스템을 대체해 초대형 추천시스템, 교통 예측 시스템, 신약 개발 등의 광범위한 실제 응용에 적용될 수 있을 것ˮ이라고 말했다.
한편, 이번 연구는 오는 2월 22일부터 24일까지 미국 산호세에서 열릴 스토리지 시스템 분야 최우수 학술대회인 유즈닉스 패스트 2022(USENIX Conference on File and Storage Technologies. FAST 2022)에서 '대규모 그래프에서 딥러닝 서비스를 가속화하기 위한 컴퓨팅 SSD용 하드웨어/소프트웨어 공동 프로그래밍 가능 프레임워크Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs)' 이란 제목으로 발표될 예정이다.