CVSS는 소스 음성과 함께 두 개의 S2ST 데이터 세트에는 각각 1,872시간 및 1,937시간의 음성이 포함되며, 번역 음성 외에도 번역 음성의 발음과 일치하는 정규화된 숫자, 통화, 두문자어(頭文字語, 준말) 등 번역 텍스트도 제공된다.

한 언어에서 다른 언어로 음성에서 음성으로 번역(Speech-To-Speech Translation. 이하, S2ST)을 자동으로 번역하는 것은 서로 다른 언어를 사용하는 사람들 사이의 의사소통과 문화 및 정보 교류에 혁신적으로 기여한다.
일반적으로 기존 자동 S2ST 시스템은 자동음성인식(ASR), 텍스트 간 기계 번역(MT) 및 텍스트 음성 변환(TTS) 합성 하위 시스템의 캐스케이드(Cascade)로 구축되므로 시스템 전체가 텍스트 중심이다.
최근, 학습된 개별 음성 표현에 기초한 엔드 투 엔드 다이렉트 S2ST(예:Translatotron-다운) 및 캐스케이드 S2ST(예:Tjandra et al-다운)와 같이 중간 텍스트 표현에 의존하지 않는 S2ST에 대한 작업에 진전을 나타나고 있다.
이러한 다이렉트 S2ST 시스템의 초기 버전은 캐스케이드 S2ST 모델에 비해 번역 품질이 낮았지만 번역 지연과 복합 오류를 줄이고 음성, 감정, 어조 등의 원래 음성에서 준언어적 및 비언어적 정보를 보다 잘 보존할 수 있는 잠재력을 가지고 있기 때문에 견인력을 얻고 있다.
그러나 이러한 모델은 일반적으로 쌍을 이루는 S2ST 데이터가 있는 데이터 세트에 대해 학습을 받아야하지만 이러한 코퍼스(말뭉치)의 공개 가용성은 극히 제한적이다.
여기에, 구글 AI는 이러한 새로운 세대의 S2ST에 대한 연구와 인공지능 음성 변환 애플리케이션의 개발을 촉진하기 위해 21개 언어에서 영어로 문장 수준의 음성 대 음성 변환 쌍을 포함하는 공통 음성 기반 음성 변환 말뭉치인 '대규모 다국어 음성-음성 번역 코퍼스(이하, CVSS)'를 지난 1일 오픈소스로 공개했다. 기존 퍼블릭 코퍼스와 달리 별도의 프로세싱 없이 다이렉트 S2ST 모델의 학습에 바로 적용할 수 있다.
이는 지난 1월 아카이브를 통해 발표된 논문 'CVSS 코퍼스 및 대규모 다국어 음성 번역(CVSS Corpus and Massively Multilingual Speech-to-Speech Translation-다운)에서는 데이터 세트 설계 및 개발에 대해 설명하고, 베이스라인 다이렉트 및 캐스케이드 S2ST 모델의 훈련과 캐스케이드 S2ST 모델에 접근하는 다이렉트 S2ST 모델의 성능을 보여줌으로써 말뭉치의 효과를 입증했다.
CVSS는 메타의 'CoVoST 2 ST(음성-텍스트) 번역 코퍼스(CoVoST 2 및 대규모 다국어 음성-텍스트 번역/CoVoST 2 and Massively Multilingual Speech-to-Text Translation-다운)'에서 직접 파생되며, 이는 누구나 음성 지원 애플리케이션을 교육하는 데 사용할 수 있는 오픈 소스인 다국어 음성 데이터 세트 '커먼 보이스(Common Voice-다운)' 음성 코퍼스에서 추가로 파생된다.

CoVoST 2는 21개 언어에서 영어로, 영어에서 15개 언어로 원문을 전문적으로 번역할 수 있다. CVSS는 21 개 언어의 문장 수준 병렬 음성-음성 변환 쌍을 영어로 제공함으로써 이러한 노력을 기반으로 한다.
특히, 구글 AI의 CVSS는 서로 다른 초점을 가진 연구를 용이하게 하기 위해 CVSS-C와 CVSS-T 두 가지 버전의 영어 번역 음성이 제공된다. 둘 다 최첨단 TTS 시스템을 사용하여 합성되며, 각 버전은 다른 공개 S2ST 말뭉치에는 없는 고유한 가치를 제공한다.
CVSS-C는 모든 번역 음성은 단일 표준 화자의 음성으로 이루어진다. 합성음에도 불구하고 음성은 매우 자연스럽고 깨끗하며 말하기 스타일로 일관된다. 이러한 속성은 대상 음성의 모델링을 용이하게 하고 훈련된 모델이 화자의 음성을 정확하게 재생하는 것보다 음성 품질이 더 중요한 일반 사용자 대면 애플리케이션에 적합한 고품질 번역 음성을 생성할 수 있도록 한다.
CVSS-T는 번역 음성은 해당 소스 음성에서 음성을 캡처한다. 각 S2ST 쌍은 다른 언어임에도 불구하고 양쪽에서 비슷한 목소리를 가지고 있다. 이 때문에 데이터 세트는 영화 더빙과 같이 정확한 음성 보존이 필요한 모델을 구축하는 데 적합하다.
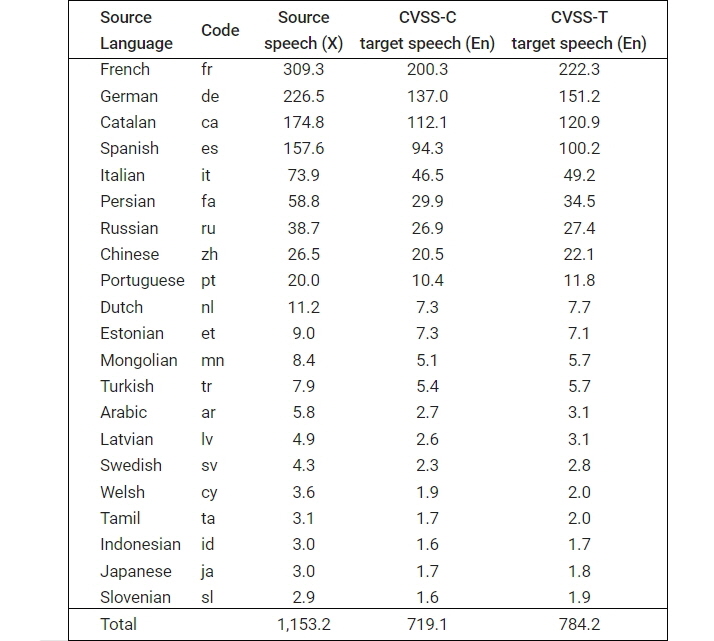
CVSS는 소스 음성과 함께 두 개의 S2ST 데이터 세트에는 각각 1,872시간 및 1,937시간의 음성이 포함되며, 번역 음성 외에도 번역 음성의 발음과 일치하는 정규화된 숫자, 통화, 두문자어(頭文字語, 준말) 등 번역 텍스트도 제공한다. CVSS는 구글 라이선스(저작자 표시 4.0 국제-CC BY 4.0)에 따라 배포되며, 누구나 무료(다운)로 내려 받을 수 있다.
한편, 21개 언어는 아라비아어(Arabic), 카탈로니아어(Catalan), 웨일스어(Welsh), 독일어(German), 에스토니아(E어stonian), 스페인어(Spanish), 페르시아어(Persian), 프랑스어(French), 인도네시아어(Indonesian), 이탈리아어(Italian), 일본어(Japanese), 라트비아어(Latvian), 몽고어(Mongolian), 네덜란드어(Dutch), 포르투갈어(Portuguese), 러시아어(Russian), 슬로베니아어(Slovenian), 스웨덴어(Swedish), 타밀어(Tamil), 터키어(Turkish), 중국어(Chinese) 등이다.