구글 로보틱스, 구글AI, 워싱턴大 공동 연구팀이 4족 보행 로봇이 인간 시연에서 의미를 인식하는 학습(Semantics-Aware Learning)을 통해 복잡한 오프로드 환경을 이동하는 로봇의 능력을 향상시키기 위해 AI '계층적 학습 프레임워크(Hierarchical Learning Framework)' 개발

4족 보행 로봇에 대한 핵심적인 요소로 인간이 접근하기 어렵거나 접근할 수 없는 복잡한 실외 환경에서 작동할 수 있는 잠재력으로 높이 평가된다. 국방에서는 물론이고 험지에서 천연 자원을 찾는 것, 심하게 손상된 재난 현장에서 생명 신호를 찾는 등 견고하고 다재다능한 4족 보행 로봇은 다양한 환경과 조건에서 매우 유용할 수 있다.
이를 위해 로봇은 환경을 인식하고 이동 문제를 이해하고 그에 따라 이동해 나간다. 최근 지각, 시각 등의 발전으로 4족 보행 로봇의 기능이 크게 향상되었지만 대부분의 작업은 실내 또는 도시 환경에 중점을 두므로 오프로드 지형의 복잡성을 효과적으로 대응하기란 여전히 매우 어려운 문제이다.
이러한 환경에서 로봇은 지형 형상뿐만 아니라(예: 경사각, 부드러움) 로봇이 이동 기술을 결정하는 데 중요한 접촉 속성(예: 마찰, 복원력, 변형성)도 포함된다. 기존의 지각 이동 시스템은 주로 깊이 카메라 또는 라이다(LiDAR)의 사용에 초점을 맞추기 때문에 시스템은 이러한 지형 속성을 정확하게 추정하기 어렵다.

여기에, 구글 로보틱스, 구글AI, 워싱턴 대학교(University of Washington) 공동 연구팀이 4족 보행 로봇이 인간 시연에서 의미를 인식하는 학습(Semantics-Aware Learning)을 통해 복잡한 오프로드 환경을 이동하는 로봇의 능력을 향상시키기 위해 인공지능(AI) '계층적 학습 프레임워크(Hierarchical Learning Framework)'를 개발했다.
이 프레임워크는 로봇이 30분미만의 인간 데모 데이터를 사용하여 로봇의 속도와 보행을 조정하는 방법을 학습하고 다양한 오프로드 지형에서 안전하고 효율적으로 이동할 수 있다.
또한 로봇이 걸을 때 프레임워크는 의미 인식(Semantics-Aware)론에 기초하여 로봇의 속도와 걸음걸이(즉, 다리 움직임의 모양과 타이밍)를 포함한 이동 기술을 결정하며, 이를 통해 로봇은 바위, 조약돌, 풀, 진흙 등을 포함한 다양한 오프로드 지형에서도 안정적으로 보행할 수 있
다.
이는 지형 형태 및 장애물 위치와 같은 환경 기하학에 중점을 둔 이전의 접근 방식과 달리, 오프로드 환경에 유용한 일련의 정보를 제공하는 지형 유형 및 접촉 특성과 같은 환경에 중점을 두었다.
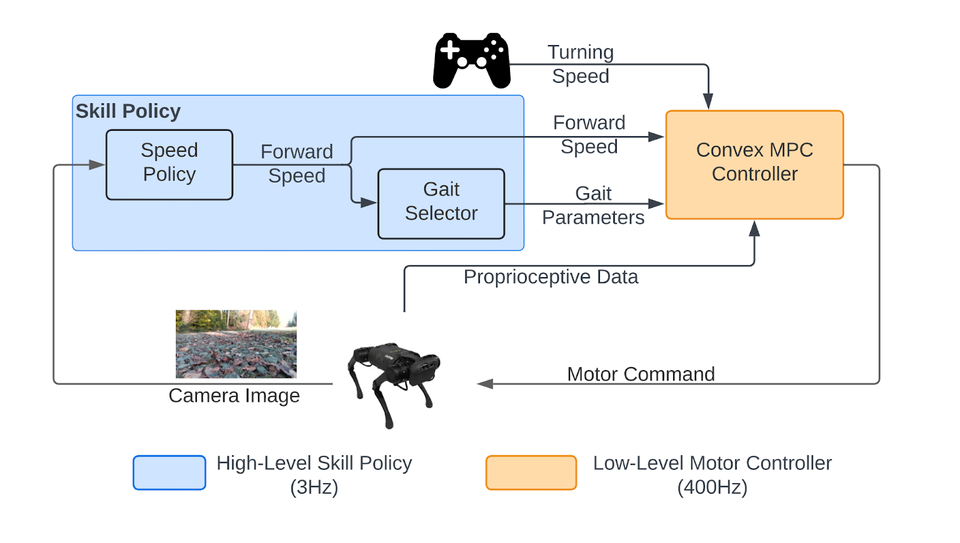
프레임워크는 높은 수준의 기술 전략과 낮은 수준의 모터 제어기로 구성된다. 카메라 이미지를 기반으로 이동 기술을 선택하고, 모터 제어기는 선택된 기술을 모터 명령으로 변환한다. 높은 수준의 기술 전략은 학습된 속도 정책과 휴리스틱(heuristic) 기반 보행 선택기로 구분된다.
기술을 결정하기 위해 속도 전략은 내장 카메라 RGB 이미지에서 로봇의 보행 및 속도를 결정하는 것으로 먼저, 지형 의미에서 속도를 계산한 다음 속도에 따라 보행을 결정한다. 에너지 효율성과 견고성을 위해 4족 보행 로봇은 일반적으로 각 속도에 대해 다른 보행을 선택하므로 전진 속도를 기반으로 원하는 보행을 계산하도록 보행 선택기를 설계했다.
낮은 수준의 볼록 모델 예측 제어(Model-Predictive Controller, MPC)는 원하는 이동 기술을 모터 토크 명령으로 변환하고 실제 하드웨어에서 실행된다. 연구팀은 표준 강화 학습 알고리즘에 비해 훈련 데이터가 더 적기 때문에 모방 학습(Imitation Learning. '모방 학습에 대한 알고리즘적 관점'-다운)을 사용하여 실제 세계에서 속도 전략(정책)을 직접 학습한다.
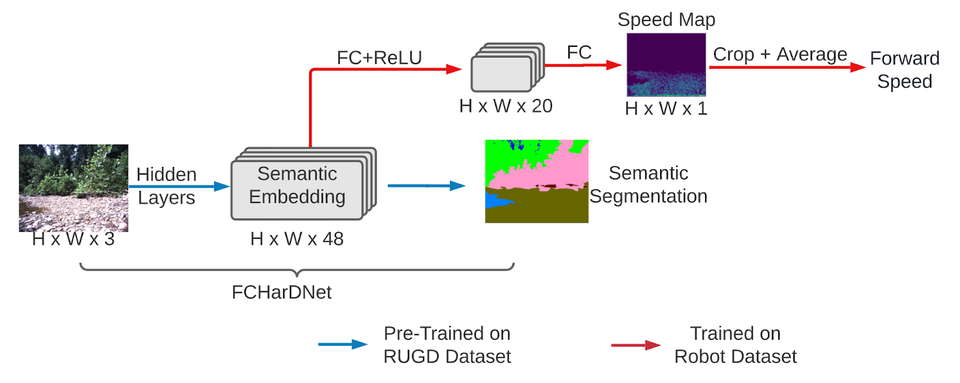
특히, 파이프라인의 중심 구성 요소인 속도 전략은 온보드 카메라의 RGB 이미지를 기반으로 로봇의 원하는 전진 속도를 출력한다. 많은 로봇 학습 작업이 시뮬레이션을 저비용 데이터 수집의 소스로 활용할 수 있지만 복잡하고 다양한 오프로드 환경에 대한 정확한 시뮬레이션이 아직 가능하지 않기 때문에 실제 세계에서 속도 전략을 훈련한 것이다.

현실 세계에서 학습은 시간이 많이 걸리고 잠재적으로 안전하지 않기 때문에 시스템의 데이터 효율성과 안전성을 개선하기 위해 두 가지 주요 설계 선택을 한다.
첫 번째는 인간의 시연에서 배우는 것이다. 표준 강화 학습 알고리즘은 일반적으로 에이전트가 환경에서 다양한 작업을 시도하고 받은 보상을 기반으로 선호도를 구축하는 탐색을 통해 학습한다. 러나 이러한 탐색은 특히, 오프로드 환경에서 잠재적으로 안전하지 않을 수 있으며, 로봇 고장은 로봇 하드웨어와 주변 환경 모두에 손상을 줄 수 있기 때문이다. 안전을 위해 연구팀은 인간의 데모에서 모방 학습을 사용하여 속도 전략을 훈련시켰다.
먼저, 인간 조작자에게 원격 조이스틱을 사용하여 로봇의 속도와 방향을 제어하는 다양한 오프로드 지형에서 로봇을 원격 조작했다. 그런 다음 표준지도 학습을 사용하여 조작된 속도 전략을 훈련하여 로봇은 조작자의 속도 명령을 예측하고, 다양한 지형에 대해 적절한 속도 선택을 학습할 수 있도록 했다.
두 번째 주요 설계 선택은 학습 방법이다. 심층신경망, 특히 고차원 시각적 입력을 포함하는 신경망은 일반적으로 훈련에 많은 데이터가 필요하다.
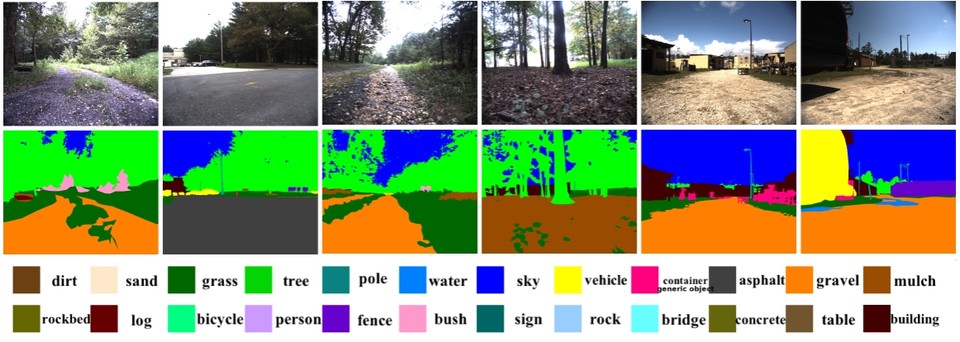
필요한 실제 훈련 데이터의 양을 줄이기 위해 먼저, 구조화되지 않은 환경에서 시각적 인식 및 자율 탐색을 위한 비디오 데이터 세트인 RUGD(Robot Unstructured Ground Driving-다운)에서 카메라 이미지의 모든 픽셀에 대한 의미 클래스(잔디, 진흙 등) 등 의미론적 세분화 모델(다운)을 사전 훈련했다.
그런 다음 의미론적 임베딩을 추출한다. 모델의 중간 레이어에서 이를 로봇 학습을 위한 기능으로 사용하며, 사전 훈련된 의미론적 임베딩을 통해 인간 조작자의 30분 미만의 실제 데이터를 사용하여 속도 정책을 효과적으로 훈련할 수 있으므로 필요한 노력의 양이 크게 줄었다.
보행 선택 및 모터 제어
파이프라인의 다음 구성 요소인 보행 선택기는 속도 전략의 속도 명령을 기반으로 적절한 보행을 계산한다. 연구에 따르면 동물들은 서로 다른 속도로 서로 다른 보행을 전환하며, 이 결과는 4족 보행 로봇에서 더욱 검증되었다.
연구팀은 각 속도에 대해 강력한 걸음걸이를 계산하도록 보행 선택기를 설계했다. 모든 속도에서 연구팀의 보행 선택기가 오프로드 지형에서 로봇의 탐색 성능을 더욱 향상시킨다는 것을 확인했다(자세한 내용은 아래 논문 참조).
마지막 구성 요소는 속도 및 보행 명령을 모터 토크로 변환하는 모터 컨트롤러이다. 이전 작업과 유사하게 스윙 및 다리 자세(Stance Legs)에 대해 별도의 제어 전략을 적용해 기술 학습과 운동 제어 작업을 분리하여 원하는 속도만 출력하면 되고 낮은 수준의 운동 제어를 학습할 필요가 없으므로 학습 프로세스가 크게 간소화됐다.
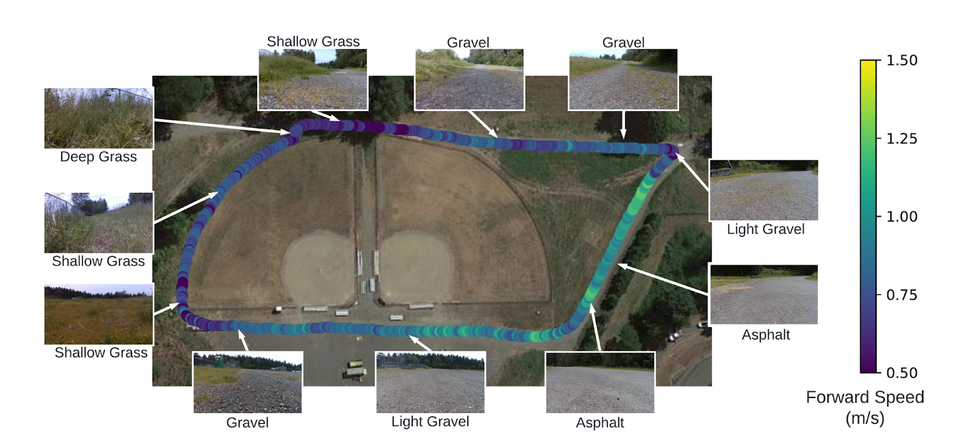
연구팀의 프레임워크는 테스트 주행에서 이러한 차이를 포착하고 큰 풀 속에서 느린 속도(0.5m/s), 자갈에서 중간 속도(1m/s), 아스팔트에서 고속(1.4m/s)과 같은 각 지형 유형에 적합한 기술을 선택했으며, 평균 속도 0.8m/s(즉, 시속 1.8마일 또는 2.9km)로 460m 길이의 주행로를 9.6분 만에 완료했다고 한다.
일반화 가능성을 테스트하기 위해 훈련 중에 볼 수 없는 여러 주행로에서도 로봇을 배치했다. 특히, 로봇은 지형 의미를 기반으로 이동 기술을 조정하며, 6km가 넘는 야외 산책로를 실패 없이 모두 통과했다.
이 같은 실제 환경에서 구글AI 연구팀은 로봇의 오프로드 이동을 위한 의미 인식 이동 기술을 학습하기 위한 계층적 프레임워크를 제시했으며, 30분 미만의 인간 데모 데이터를 사용하여 프레임워크는 인식된 환경의 의미를 기반으로 로봇의 속도와 보행을 조정하는 방법을 구현한 것이다.
한편, 연구팀의 이번 연구는 아카이브를 통해 ‘인간의 시연을 통해 의미 인식 이동 기술 학습(Learning Semantics-Aware Locomotion Skills from Human Demonstration-다운)’지난 6월 22일 공개됐다.
현재, 연구팀의 프레임워크는 로봇은 다양한 오프로드 지형에서 안전하고 효율적으로 걸을 수 있지만 표준 보행에 대한 이동 기술만 조정하고 간격이나 장애물이 있는 더 어려운 지형을 횡단하는 데 필수적일 수 있는 점프와 같은 보다 민첩한 동작을 지원하지 않는다는 것이다. 또 다른 한계는 프레임워크에서 원하는 경로를 따라 목표에 도달하기 위해서는 수동 조종 명령이 필요하다는 것이다.
연구팀을 이를 충족시키기 위해 연구 및 개발을 지속한다고 밝혔다.