기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 한다. 이미지 분류 문제에서 최신 방법 대비 최대 20% 정확도 향상
최근 다양한 분야에서 인공지능(AI) 심층학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서 AI는 심층신경망을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다.
특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 고양이 사진에 `고양이'라고 정답을 적어줌), 이 과정은 일반적으로 수작업으로 진행되므로 엄청난 노동력과 시간적 비용이 소요된다. 따라서 훈련 데이터 구축 비용을 최소화하는 방법 개발이 요구되고 있다.
여기에, KAIST(총장 이광형)는 전산학부 이재길 교수 연구팀이 심층 학습 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다.
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다.
따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외(out-of-distribution) 데이터가 포함된다 (예를 들어, 동물 사진을 수집할 때 재규어 `자동차'가 포함됨). 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다.
모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습(active learning)이 큰 주목을 받고 있다.
그러나 정제와 레이블링을 별도로 진행하는 것은 데이터 검사 측면에서 중복적인 비용을 초래한다. 또한 아직 정제되지 않고 남아 있는 분포 외 데이터가 레이블링 단계에서 선택된다면 레이블링 노력을 낭비할 수 있다.
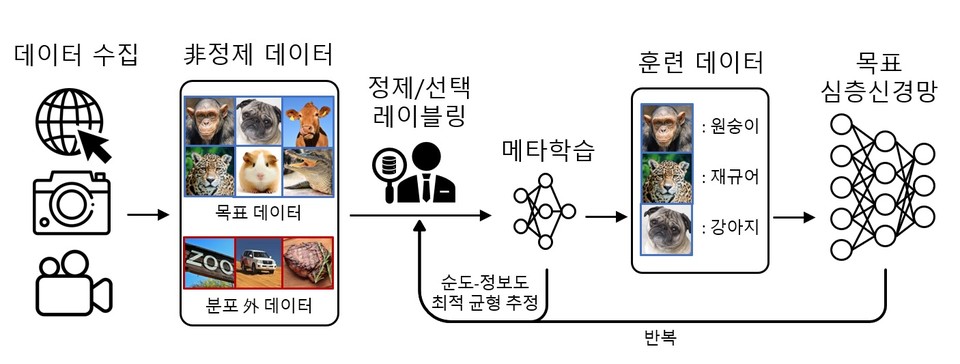
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
데이터의 정제 및 선택을 동시에 고려하기 위해서 구체적으로 가장 분포 외 데이터가 아닐 것 같은 데이터 중에서 가장 심층 학습 성능 향상에 도움이 될 데이터를 선택한다. 즉, 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도(purity) 지표와 정보도(informativeness) 지표의 최적 균형(trade-off)을 찾는다.
순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 간단하지 않다. 이 교수팀은 이러한 최적 균형이 정제 전 데이터의 분포 외 데이터 비율과 현재 심층신경망 훈련 정도에 따라 달라진다는 점을 발견했다.
이 교수팀은 이러한 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다. 연구팀은 추가된 모델을 훈련하기 위해 능동 학습에서 여러 단계에 걸쳐 데이터를 선별하는 과정을 활용했다.
즉, 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다. 이러한 방법은 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하였다는 점에서 메타학습(meta-learning)의 일종이라 볼 수 있다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과, 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다.
또한, `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 실세계 능동 학습에서의 순도-정보도 딜레마를 발견하고 해결한 획기적인 방법ˮ 이라면서 "다양한 데이터 분포 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
한편, KAIST 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 신유주 박사과정, 이영준 박사과정 학생이 제2, 제4 저자로 각각 참여한 이번 연구는 11월 28일부터 12월 9일까지 미국 루이지애나 뉴올리언스 모리얼 컨벤션 센터에서 열리는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS 2022)'에서 Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning'란 제목으로 발표될 예정이다.