
엔비디아 리서치(NVIDIA Research)와 존스홉킨스대학교(Johns Hopkins University) 공동 연구팀이 신경망을 사용해 예술, 게임 개발, 로보틱스 및 산업용 디지털 트윈 등에서 3D 장면을 재구성하는 새로운 인공지능(AI) 모델 '뉴럴란젤로(Neuralangelo)'을 개발했다.
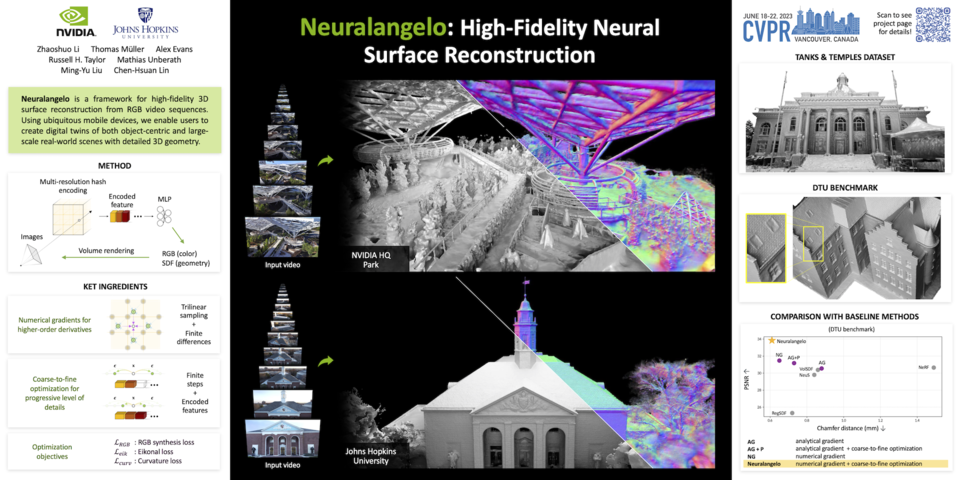
뉴럴란젤로는 RGB 비디오 캡처에서 고충실도 3D 표면 재구성을 위한 프레임워크다. 유비쿼터스 모바일 장치를 사용하여 매우 상세한 3D 지오메트리(Geometry)로 객체 중심 및 대규모 실제 장면의 디지털 트윈을 생성할 수 있다.

뉴럴란젤로는 미켈란젤로(Michelangelo)가 대리석 블록으로 실제와 같은 멋진 작품을 조각한 것처럼 복잡한 디테일과 텍스처를 가진 3D 구조를 생성한다. 이후 크리에이티브 전문가는 3D 객체를 디자인 애플리케이션으로 가져올 수 있다.
여기에서 크리에이티브 전문가는 해당 객체를 예술, 게임 개발, 로보틱스 및 산업용 디지털 트윈에 사용할 수 있도록 추가 편집할 수 있다.
또한 뉴럴란젤로 기능으로 지붕 널, 유리창, 매끄러운 대리석 등 복잡한 재료의 텍스처를 2D 비디오에서 3D 에셋으로 변환시킬 수 있다. 높은 충실도 덕분에 개발자와 크리에이티브 전문가는 스마트폰으로 캡처한 영상을 사용해 프로젝트에 사용할 수 있는 가상 객체를 더 수월하게 3D로 재구성한다.
엔비디아 리서치 연구 수석 디렉터인 류밍유(Ming-Yu Liu)는 "뉴럴란젤로가 제공하는 3D 재구성 기능은 크리에이터가 디지털 세계에서 현실 세계를 재현하는 데 큰 도움이 될 것이다. 개발자는 이 툴을 통해 작은 조각상이나 거대한 건물 등 세부적인 객체를 게임이나 산업용 디지털 트윈을 위한 가상 환경으로 가져올 수 있게 될 것"이라고 말했다.
연구팀은 데모에서 이 모델이 미켈란젤로의 다비드처럼 상징적인 물체부터 플랫베드 트럭처럼 흔한 물체까지 어떻게 재현할 수 있는지 선보였다. 또한 뉴럴란젤로는 건물 내부와 외부를 재구성할 수 있는데, 엔비디아 베이 에어리어(Bay Area) 캠퍼스에 있는 공원의 상세한 3D 모델을 통해 이를 시연했다.

특히, 3D 장면을 재구성하는 이전의 AI 모델은 반복적인 텍스처 패턴, 균일한 색상 및 강한 색상 변화를 정확하게 캡처하는 데 어려움을 겪었다. 뉴럴란젤로는 미세한 디테일을 캡처하는 데 도움이 되는 즉각적인 뉴럴 그래픽 프리미티브(primitives) 기술인 엔비디아 인스턴트 NeRF(Instant NeRF)을 채택했다.
뉴럴란젤로는 다양한 각도에서 촬영한 물체 또는 장면의 2D 비디오를 사용해 다양한 시점을 포착하는 여러 프레임을 선택한다. 마치 깊이, 크기 및 모양을 파악하기 위해 여러 측면에서 피사체를 고려하는 예술가 같다.
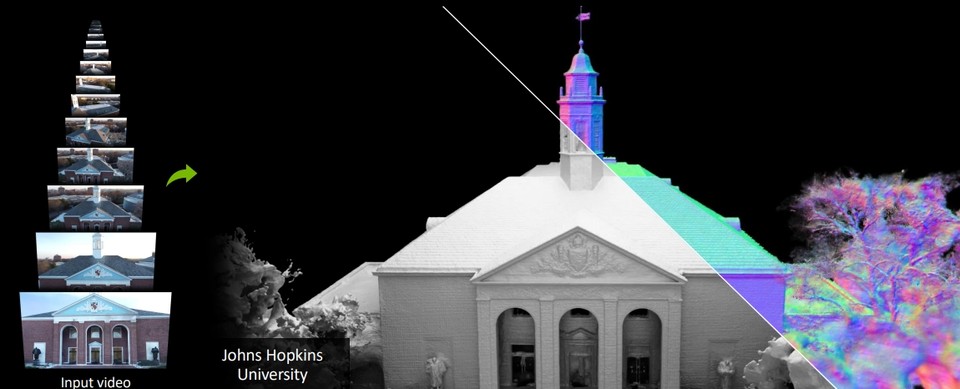
뉴랄란젤로의 AI는 각 프레임의 카메라 위치가 결정되면 조각가가 피사체의 모양을 깎기 시작하는 것처럼 장면의 대략적인 3D 묘사를 생성한다. 그런 다음, 조각가가 천이나 인물의 질감을 모방하기 위해 돌을 정성스럽게 다듬는 것처럼 모델이 렌더링을 최적화해 디테일을 선명하게 구성한다.
최종 결과물은 3D 객체나 대규모 장면인데, 가상 현실 애플리케이션, 디지털 트윈 또는 로보틱스에 사용할 수 있다.
이번 연구팀의 뉴럴란젤로 모델은 현지시간 18일부터 22일까지 캐나다 밴쿠버에서 열리는 컴퓨터 비전 및 패턴 인식 콘퍼런스(IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2023)에서 '뉴럴란젤로:고충실도 신경 표면 재구성(Neuralangelo: High-Fidelity Neural Surface Reconstruction-다운) 발표될 예정이다. 해당 논문은 이번 CVPR에서 채택, 발표될 엔비디아 리서치의 생성 AI 등 약 30개의 연구 프로젝트 중 하나이다. (아래는 2D 비디오 클립에서 3D 장면을 재구성하는 엔비디아 리서치의 뉴럴란젤로의 소개영상)
또한 이러한 프로젝트 중 하나로 조지아공과대학교(Georgia Institute of Technology)와 공동연구의 디프콜라주(DiffCollage: Parallel Generation of Large Content with Diffusion Models-다운)는 긴 가로 방향, 360도 파노라마, 루프 모션 이미지 등 대규모 콘텐츠를 생성하는 확산 방식이다.

디프콜라주는 표준 종횡비의 이미지로 구성된 훈련 데이터 세트를 입력하면 작은 이미지를 콜라주 조각처럼 큰 비주얼의 섹션으로 처리한다. 이를 통해 확산 모델은 동일한 크기의 이미지로 학습하지 않고도 일관성 있는 대형 콘텐츠를 생성할 수 있다.

이 기술은 텍스트 프롬프트를 비디오 시퀀스로 변환할 수도 있으며, 사람의 움직임을 캡처하는 사전 훈련된 확산 모델을 사용해 이를 구현할 수 있다.