샘플 공간을 먼저 추출하는 방법인 메타 샘플링(meta sampling)의 일종인 DRS(degree-based rejection sampling) 기법을 개발했다. 기존에는 어떤 확률적인 실험에서 가능한 모든 결과의 집합인 샘플 공간 공간(sample space) 에서 바로 값을 추출하기 전에 샘플 공간의 모든 값에 대한 확률을 미리 계산해야 했다.

2016년 3월, 인간과 인공지능 간 세기의 대결로 온 세상이 들썩였다.
방대한 양의 데이터를 학습한 인공지능 프로그램 ‘알파고’가 여러 경우의 수를 계산하는 바둑에서 인간을 이긴 것이다. 의료계와 금융계, 교육계 등 이미 우리 일상 곳곳에 스며든 인공지능이 꾸준하게 성장하고 발전하기 위해서는 인공지능을 학습시킬 양질의 데이터가 필요하다.
데이터는 ‘테이블(table)’이라는 그룹으로 분산되어 저장되어 있다.
인공지능이 테이블로 저장된 데이터를 학습하려면 ‘조인(join)’이라는 과정을 통해 하나의 거대한 테이블을 만들어야 하는데, 그 크기가 매우 커 저장이 어려울 뿐 아니라 조인하는 과정에서 오랜 시간이 걸린다. 테이블로부터 데이터를 빠르고, 균일하게 샘플링하는 기법에 대한 연구는 아직까지 풀리지 않는 난제로 남아있다.
여기에, 최근 POSTECH(포항공과대학교, 총장 김무환) 인공지능대학원 한욱신 교수, IT융합공학과 통합과정 김경민 박사과정 등의 연구팀은 여러 테이블로 저장된 데이터에 대한 최적의 샘플링 기법을 제안하여 빠르게 결과를 도출하는 데 성공했다.

또한 이번 연구는 지난 18일부터 23일까지 미국 시애틀에서 개최된 세계적인 데이터베이스 학회인 ‘ACM PODS’에서 발표됐으며, 42년 학회 역사상 처음으로 한국 연구진의 논문이 학회에서 발표된 것도 큰 의의가 있다.
연구팀은 이번 연구에서 샘플 공간을 먼저 추출하는 방법인 메타 샘플링(meta sampling)의 일종인 DRS(degree-based rejection sampling) 기법을 개발했다. 기존에는 어떤 확률적인 실험에서 가능한 모든 결과의 집합인 샘플 공간 공간(sample space) 에서 바로 값을 추출하기 전에 샘플 공간의 모든 값에 대한 확률을 미리 계산해야 했다.
반면, 연구팀이 제안한 기법은 특정 값의 빈도(degree)에 기반한 단순한 확률 분포를 가진 샘플 공간을 먼저 추출하고, 그 샘플 공간에서 값을 뽑아낸다. 핵심 이론은 뽑힐 수 있는 임의의 값에 대해 적어도 하나의 샘플 공간이 기존 방법에서 복잡하게 계산한 확률보다 큰 확률을 부여한다는 점을 증명하여,
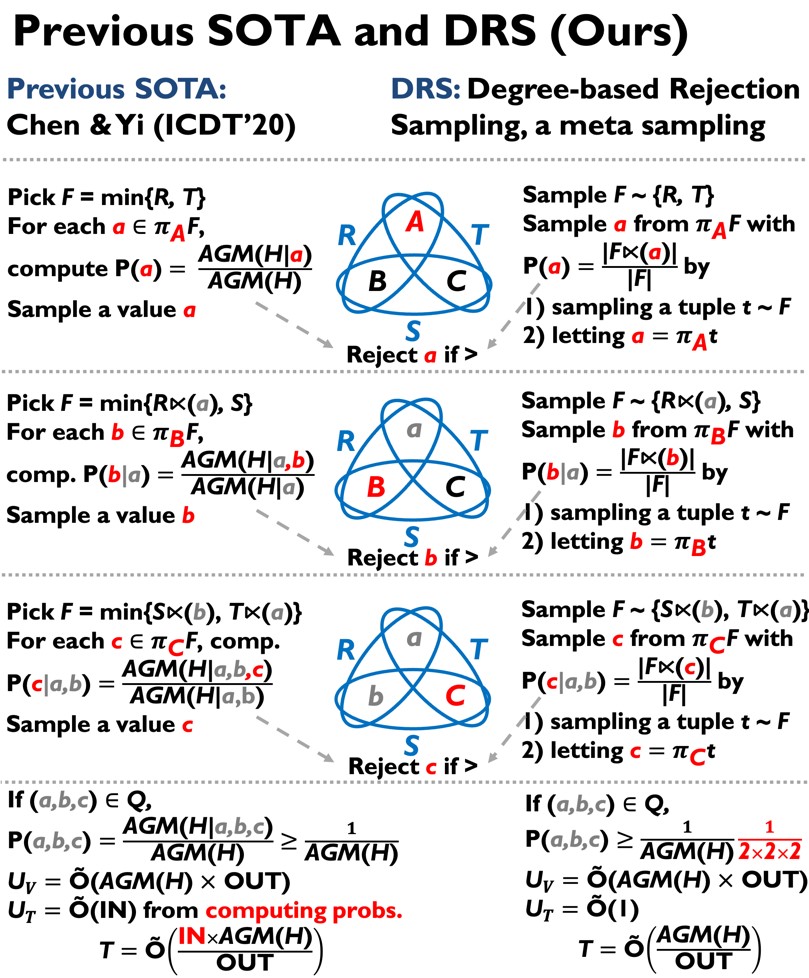
결국, 원하는 확률 분포에 따라 샘플링하기 힘들 경우 사용되는 기법 중 하나인 기각 샘플링(rejection sampling)을 통해 기존 방법과 같은 확률로 값을 뽑을 수 있다는 점이다. 이렇게 하면, 샘플 공간을 추출하는 확률이 상수값으로써 곱해질 뿐, 복잡한 확률을 계산하지 않고 빠르게 데이터를 샘플링할 수 있다.
또한, 테이블을 합치는 ‘조인’ 과정에서 데이터를 검색하거나 조작하기 위해 사용되는 명령문 쿼리(query)를 트리 형태로 분석하는 ‘일반적 하이퍼트리 분해(generalized hypertree decomposition, 이하 GHD)’를 통해 기법을 더 확장시켰다.
전체 쿼리를 하나의 조인 알고리즘으로 처리하면 쿼리에 조인 관계가 많을 경우, 알고리즘의 수행이 입력 크기에 대해 어떻게 증가하는지 나타내는 개념으로 복잡도가 낮을수록 효율적인 시간 복잡도(time complexity)가 크다.
GHD를 사용하면 전체 쿼리가 아닌 작은 쿼리에 대해 조인을 진행하고 이 결과들을 합쳐 시간 복잡도를 낮출 수 있다. 연구팀은 GHD를 DRS에 적용하여 DRS를 확장시켰으며, 특정 경우에 대해 DRS보다 낮은 복잡도를 보장하였다.

이번 연구를 이끈 한욱신 교수는 “이 기법은 데이터들의 계층적인 구조를 보여주는 트리(tree) 형태나 순환되는 관계를 보여주는 사이클(cycle) 형태에 상관없이 모든 쿼리에 적용할 수 있으며, 머신러닝을 위한 데이터 샘플링 과정에서 속도와 정확도를 향상시키는 데 기여할 것”이라는 기대를 전했다.
한편, 이번 연구는 제1저자로 김경민 박사과정과 포스텍 하재현, 아인트호벤 공과대학교(TU/e) 조지 플레처(George Fletche), 교신저자로 한욱신 교수의 '데이터베이스 조인에 대한 균일한 샘플링 및 결과 개수 예측에 대해 O(AGM/OUT) 시간 복잡도를 보장하는 방법(Guaranteeing the O(AGM/OUT) Runtime for Uniform Sampling and Size Estimation over Joins-다운)'란 제목으로 학회 중 지난 18일 발표됐다.