MIT와 MIT-IBM 왓슨 인공지능 랩 공동연구팀, 이 AI 시스템은 분자 특성을 예측하는 데 소량의 데이터만으로 물질‧약물 발견 및 재료 등 다양한 분야에서 개발 속도를 혁신적으로 높인다.
새로운 물질, 재료와 약물 등을 발견하려면 일반적으로 적게는 수년에서 많게는 수십 년이 걸리고 수백만 달러가 소요될 수 있는 작업과 많은 시행착오를 거친다. 이 프로세스를 간소화하기 위해 연구자들은 종종 머신러닝을 사용하여 분자 특성을 예측하고 실험실에서 합성하고 테스트하는 데 필요한 분자의 범위를 좁혀 나간다.
분자의 생물학적 또는 기계적 특성을 예측하도록 인공지능 머신러닝 모델을 학습시키려면 연구 및 개발자들은 수백만 개의 레이블이 지정된 분자 구조를 인식시켜야 한다. 이 과정을 학습이라고 한다. 그러나, 분자를 발견하는 데 드는 비용과 수백만 개의 구조를 수작업으로 라벨을 지정해야 하는 문제로 인해 대규모 학습 데이터 세트를 구축하기 어려운 경우가 많아 머신러닝 접근 방식은 그 효율성이 제한되는 경우가 많다.
여기에, MIT와 MIT-IBM 왓슨 인공지능 랩(MIT-IBM Watson AI Lab) 공동 연구팀은 분자 특성을 동시에 예측하고 이러한 대중적인 머신러닝 접근 방식보다 훨씬 더 효율적으로 새로운 분자를 생성할 수 있는 새로운 통합 프레임워크를 개발했다.
연구팀의 인공지능 시스템은 아주 적은 양의 데이터만으로도 분자 특성을 효과적으로 예측할 수 있다. 이 시스템은 빌딩 블록이 결합하여 유효한 분자를 생성하는 방법을 지시하는 규칙에 대한 근본적인 이해를 가지고 있다. 이러한 규칙은 분자 구조 간의 유사성을 포착하여 시스템이 새로운 분자를 생성하고 데이터 효율적인 방식으로 특성을 예측하는 데 큰 도움을 준다.
또한 이 시스템은 소규모 및 대규모 데이터 세트 모두에서 다른 머신러닝 접근 방식보다 성능이 매우 뛰어났으며, 샘플 수가 100개 미만인 데이터 세트가 주어졌을 때 분자 특성을 정확하게 예측하고 실행 가능한 분자를 생성할 수 있었다. 연구팀의 목표는 새로운 분자의 발견 속도를 높이기 위해 데이터 기반 방법을 사용하여 비용이 많이 드는 실험 없이도 예측을 수행할 수 있도록 모델을 훈련시키는 것이다.
분자의 언어를 학습하는 것
머신러닝 모델로 최상의 결과를 얻기 위해서는 연구자들이 발견하고자 하는 것과 유사한 특성을 가진 수백만 개의 분자로 훈련된 데이터 세트가 필요하다. 실제로 이러한 도메인별 데이터 세트는 일반적으로 매우 작다. 따라서 연구자들은 일반 분자의 대규모 데이터 세트에서 사전 훈련된 모델을 사용하여 훨씬 더 작은 목표 데이터 세트에 적용한다. 그러나 이러한 모델은 도메인별 지식을 많이 얻지 못했기 때문에 성능이 떨어지는 경향이 있다.
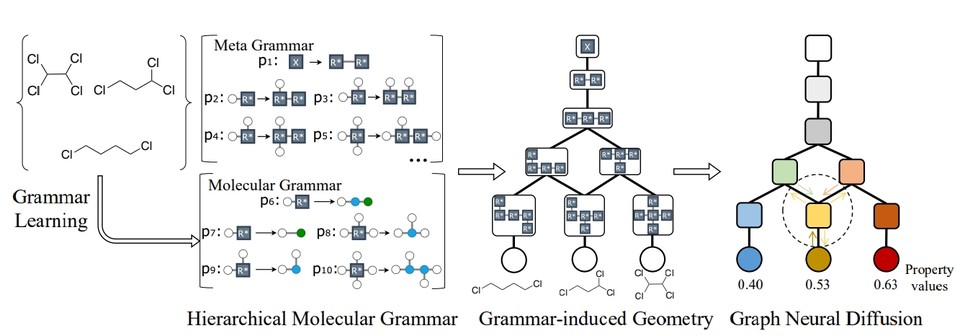
이에 연구팀은 다른 접근 방식으로 접근했다. 그들은 소규모의 도메인별 데이터 세트만을 사용하여 분자의 '언어'를 자동으로 학습하는 머신러닝 시스템(분자 문법이라고 함)을 만들었다. 이 문법을 사용하여 실행 가능한 분자를 구성하고 그 특성을 예측하는 것이다.
일반적으로 언어 이론에서, 일련의 문법 규칙에 기초하여 단어, 문장 또는 단락을 생성한다. 분자 문법에서도 같은 방법으로 생각할 수 있다. 그것은 원자와 하부 구조를 결합하여 분자나 중합체(polymer)를 생성하는 방법을 지시하는 일련의 생산 규칙이다.

즉, 동일한 규칙을 사용하여 다수의 문장을 생성할 수 있는 언어 문법과 마찬가지로, 하나의 분자 문법은 방대한 수의 분자를 나타낼 수 있는 것이다. 유사한 구조를 가진 분자는 동일한 문법 생성 규칙을 사용하고, 시스템은 이러한 유사성을 이해하는 법을 학습한다.
구조적으로 유사한 분자는 종종 비슷한 특성을 갖기 때문에, 시스템은 분자 유사성에 대한 기본 지식을 사용하여 새로운 분자의 특성을 보다 효율적으로 예측한다. 이 문법을 모든 다른 분자에 대한 표현으로 사용하면 속성 예측 프로세스를 향상시키는 데 사용할 수 있다
또한, 이 시스템은 강화학습(RL)을 사용하여 분자 문법에 대한 생산 규칙을 학습한다. 이는 모델이 목표 달성에 더 가까워지는 행동에 대해 보상을 받는 시행착오 과정이다. 하지만 원자와 하부 구조를 결합하는 방법은 수십억 가지가 있을 수 있기 때문에 문법 생성 규칙을 학습하는 과정은 아주 작은 데이터 집합을 제외하고는 계산 비용이 너무 많이 든다.
이에 연구팀은 분자 문법을 두 부분으로 분리했다. 첫 번째 부분인 메타그래머(metagrammar)는 일반적이고 널리 적용 가능한 문법으로, 연구팀이 직접 설계하여 처음에 시스템에 제공한다. 그런 다음, 도메인 데이터 세트에서 훨씬 더 작은 분자별 문법만 학습하면 된다. 이러한 계층적 접근 방식은 학습 프로세스의 속도를 높였다.
큰 결과, 작은 데이터 세트
실험에서 연구팀의 새로운 AI 시스템은 실행 가능한 분자와 폴리머를 동시에 생성했으며, 도메인별 데이터 세트에 샘플이 수백 개에 불과한 경우에도 널리 사용되는 여러 머신러닝 접근 방식보다 더 정확하게 특성을 예측했다. 다른 방법도 비용이 많이 드는 사전 학습 단계가 필요했지만, 이 새로운 시스템은 이를 피할 수 있다.
특히, 이 기술은 물질이 고체에서 액체로 변하는 데 필요한 온도인 유리 전이 온도(Glass Transition Temperature)와 같은 폴리머의 물리적 특성을 예측하는 데 특히 효과적이었다. 이 정보를 수동으로 얻는 것은 실험에 매우 높은 온도와 압력이 필요하기 때문에 비용이 매우 많이 드는 경우가 많다.
이에 연구팀은 접근 방식을 더욱 발전시키기 위해 하나의 훈련 세트를 절반 이상 줄여 94개의 샘플로 줄였다. 그럼에도 불구하고 이 모델은 전체 데이터 세트를 사용하여 학습한 방법과 동등한 수준의 결과를 달성한 것이다.
이 문법 기반 표현은 매우 강력하다. 문법 자체가 매우 일반적인 표현이기 때문에 다양한 종류의 그래프 형식 데이터에 적용할 수 있으며 화학이나 재료 과학을 넘어 다양한 분야에도 적용할 수 있다. (참고 논문, '분자 생성을 위한 데이터 효율적인 그래프 문법 학습/Data-Efficient Graph Grammar Learning for Molecular Generation'-다운)
한편, 연구팀은 향후, 현재의 분자 문법을 확장하여 폴리머 사슬 간의 상호작용을 이해하는 데 핵심이 되는 분자와 고분자의 3D 기하학적 구조를 포함하고자 한다. 또한 학습한 문법 생성 규칙을 사용자에게 보여주고 잘못된 규칙을 수정하기 위한 피드백을 요청하여 시스템의 정확성을 높이는 인터페이스도 개발하고 있다.

연구팀의 AI 시스템의 연구 결과는 현지시간, 23일부터 29일까지 미국 하와이 컨벤션 센터에서 개최되는 인공지능·머신러닝 분야 글로벌 최고 학회인 제 40차 국제머신러닝학회(ICLR 2023, International Conference on Learning Representations)에서 '데이터 효율적 분자 특성 예측을 위한 문법 유도 기하학(Grammar-Induced Geometry for Data-Efficient Molecular Property Prediction-다운)'란 제목으로 발표될 예정이다.