대화형 인공지능 바드, 챗GPT 등과 같이 유사한 AI 기술을 통해 로봇 작업에서 자연어를 사용해 로봇을 제어할 수 있는 '시각-언어-행동(vision-language-action, VLA)' 모델 'RT-2'

구글이 그동안 로봇 학습에서 제어까지 근간을 흔드는 새로운 인공지능(AI) '로봇 트랜스포머 2(Robotics Transformer 2. 이하, RT-2)' 모델을 발표했다.
구글 딥마인드(Google DeepMind)가 대화형 인공지능 바드(Bard), 챗GPT(ChatGPT) 등과 같이 유사한 AI 기술을 통해 로봇 작업에서 자연어를 사용해 로봇을 제어할 수 있는 세계 최초의 '시각-언어-행동(vision-language-action, VLA)' 모델 'RT-2'를 지난 28일(현지시간) 공개한 것이다.
이 획기적인 모델을 통해 로봇은 사용자 명령어에 웹에서 텍스트 및 이미지 데이터를 수집 및 해석하고 그에 맞는 작업을 실행한다. 즉, 웹 및 로봇 데이터에서 학습하고 이 지식을 로봇 제어를 위한 일반화된 지침으로 변환시키는 것으로 이제, 로봇이 주변 세계를 이해하는 방식에 혁신을 가져올 것으로 예상된다.
이 모델는 구글이 지난해 12월 오픈 소스로 공개한 로봇 데이터에서 볼 수 있는 작업과 물체의 조합을 학습하고 로봇 입력 및 출력 작업(카메라 이미지, 작업 지침 및 명령)을 토큰화하여 런타임에서 효율적으로 추론하는 이전 모델 '로봇 트랜스포머 1(Robotics Transformer, RT 1-코드 다운)'을 기반으로 한다.
특히, 이번 'RT-2' 개발에서는 사무실 및 주방 환경에서 17개월 동안 13대의 로봇으로 수집한 RT-1 로봇 데모 데이터를 사용했으며, 노출된 로봇 데이터 이상으로 향상된 일반화 능력과 의미론적, 시각적 이해력으로 새로운 명령을 해석하고 객체 범주에 대한 추론 또는 높은 수준의 설명과 같은 기본적인 추론으로 사용자 명령에 응답하는 능력이 포함됐다.

가령, 사고(思考)에 추론을 통합하면 RT-2가 즉석에서 망치를 사용할 수 있는 물체에서 '돌, 바위'를 식별하고 피곤한 사람에게 가장 좋은 음료로 '에너지 드링크'를 결정하는 등 다단계 의미론적 작업을 수행할 수 있다.
로봇 제어를 위해 RT-2는 하나 이상의 이미지를 입력으로 받아 일반적으로 자연어 텍스트를 나타내는 토큰 시퀀스를 생성하는 VLM(Vision-Language Model)을 기반으로 구축됐다. 이러한 VLM은 시각적 질문 응답, 이미지 캡션 또는 객체 인식과 같은 작업을 수행하기 위해 웹 규모의 데이터로 성공적으로 훈련(PaLI: 공동으로 확장된 다국어 언어 이미지 모델-다운)되었다.
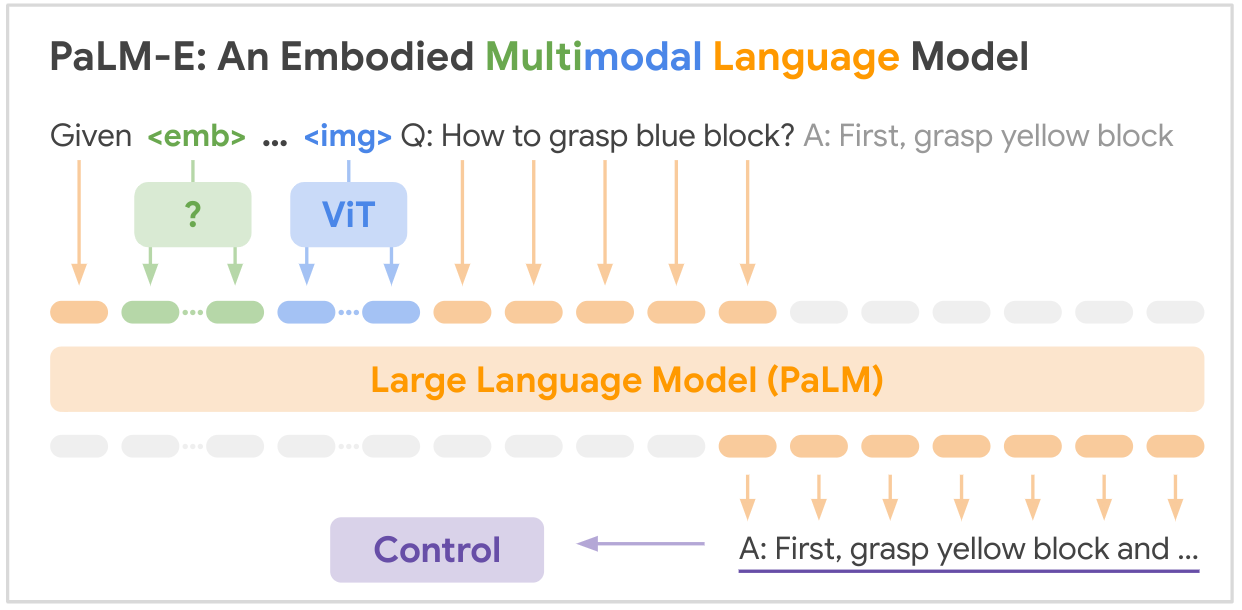
또 작업에서 RT-2의 백본 역할을 하도록 패스웨이(Pathways) 언어 및 이미지 모델(PaLI-XPaLI. 100개 이상의 언어로 언어, 이미지 학습 확장-참조)과 경로 언어 모델 구현(PaLM-E: 구현된 다중 모드 언어 모델-참고/논문)을 조정했다.
특히, 로봇을 제어하려면 동작을 출력하도록 로봇을 학습시켜야 한다. 언어 토큰과 유사하게 모델 출력에서 동작을 토큰으로 표현하고, 표준 자연어 토큰라이저(다운)에서 처리할 수 있는 문자열로 동작을 설명(아래 표에 표시된 것처럼)하여 이 문제를 해결한다.
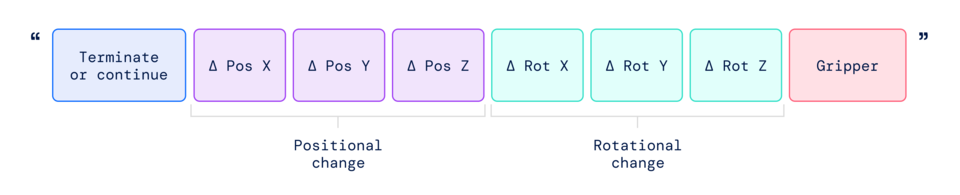
이 문자열은 후속 명령을 실행하지 않고 현재 에피소드를 계속할지 종료할지를 나타내는 플래그로 시작하여 엔드 이펙터의 위치 및 회전과 로봇 그리퍼(Gripper)의 원하는 확장을 변경하는 명령으로 이어진다.
또한 RT-1과 동일한 이산화된 버전의 로봇 동작을 사용하고, 이러한 모델의 입력 및 출력 공간을 변경할 필요가 없기 때문에 이를 문자열 표현으로 변환하면 로봇 데이터에 대한 VLM 모델을 훈련할 수 있다.
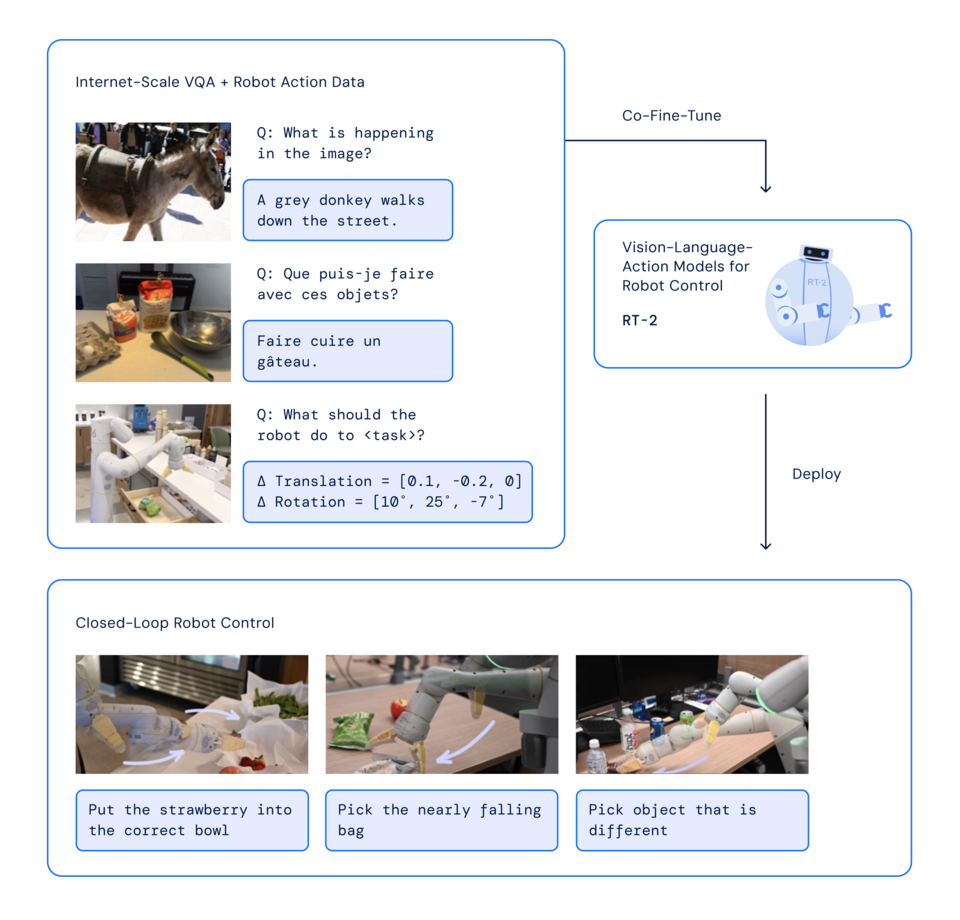
RT-2 모델은 6,000회 이상의 로봇 실험을 통해 일련의 정성적, 정량적 테스트를 수행했다. RT-2의 새로운 능력을 탐색하기 위해 먼저, 웹 스케일 데이터와 로봇의 경험 지식을 결합해야 하는 작업를 찾은 다음 '기호 이해', '추론', '인간 인식'이라는 세 가지 범주의 기술을 정의했다.
각 작업에는 시각적-의미론적 개념에 대한 이해와 이러한 개념을 작동하기 위해 로봇 제어를 수행하는 능력이 필요했다. 예를 들어, "테이블에서 떨어지려고 하는 가방을 집어" 또는 "바나나를 2 더하기 1의 합으로 이동해"와 같은 명령은 로봇 데이터에서 볼 수 없는 물체 또는 시나리오에 대한 조작과 작업을 수행하도록 요청하는 것으로, 로봇이 작동하려면 웹 기반 데이터에서 변환된 지식이 필요했다. 이는 대규모 시각적 데이터 세트에서 사전 훈련되었다.

결론적으로 RT-2는 VLM(시각 언어 모델)이 로봇 데이터와 VLM 사전 훈련을 결합하여 로봇을 프롬프트(지시어)를 통해 직접 제어할 수 있는 강력한 VLA(시각 언어 행동) 모델로 변환될 수 있음을 보여준 것으로 PaLM-E 및 PaLI-X를 기반으로 한 VLA의 두 가지 인스턴스화를 통해 기존의 VLM 모델에 대한 간단하고 효과적인 수정일 뿐만 아니라 실제 환경에서 다양한 작업을 수행하기 위해 추론하고, 문제를 해결하고, 정보를 해석할 수 있는 다양한 산업에서의 물리적 로봇을 구축할 가능성을 열어 준 것이다.
한편, 자세한 이 모델에 대한 기술적 내용은 논문 'RT-2: 웹 지식을 로봇 제어에 전달하는 비전-언어-행동 모델(RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control-다운)'을 참고하면 된다.