사용자 입력(프롬프트)에서 고품질의 사실적인 오디오 및 음악을 생성하는 이 AI 도구는 '뮤직젠(MusicGen)', '오디오젠(AudioGen)', '엔코덱(EnCodec)'의 세 가지 모델과 함께 번들로 제공되며 음악, 사운드, 압축 및 생성을 위해 작동한다.

최근 언어 모델을 비롯한 이미지, 비디오 등에 대한 생성 AI는 많은 관심을 받고 있지만, 오디오는 약간 뒤처져 있다. 일부 연구가 진행 중이지만 매우 복잡하고 개방적이지 않아서 많은 사람들이 쉽게 사용할 기회는 미비했다.
여기에, 메타(Meta)가 2일(현지시간), 악기로 한 음도 연주해보지 않고도 전문 작곡가와 같이 새로운 음악과 노래를 창작(작곡) 할 수 있으며, 또는 사실적인 음향 효과와 주변 환경적인 소음을 만들 수 있는 누구나 간단하고 편리하게 사용할 수 있는 오디오용 생성 AI 플랫폼 '오디오크래프트(AudioCraft)'를 오픈 소스로 공개했다.
오디오크래프트는 미디(MIDI) 또는 피아노 롤이 아닌 원시 오디오 신호에 대한 학습 후 텍스트 기반 사용자 입력(지시어·프롬프트)에서 고품질의 사실적인 오디오 및 음악을 생성하는 이 AI 도구는 '뮤직젠(MusicGen)', '오디오젠(AudioGen)', '엔코덱(EnCodec)'의 세 가지 모델과 함께 번들로 제공되며 음악, 사운드, 압축 및 생성을 위해 작동한다
먼저, 메타가 소유하고 특별히 라이선스가 부여된 음악으로 학습된 MusicGen은 텍스트 기반 사용자 입력에서 음악을 생성하며, 공개 음향 효과에 대해 사전 학습된 AudioGen은 텍스트 기반 사용자 입력에서 개 짖는 소리, 자동차 경적 소리 또는 나무 바닥 위의 발소리와 같은 생활 환경 소리 및 음향 효과 등의 오디오를 생성한다. 또한 개선된 버전의 EnCodec 디코더는 더 적은 아티팩트로 더 높은 품질의 음악을 생성할 수 있다.

모든 종류의 고음질 오디오를 생성하려면 다양한 규모의 복잡한 신호와 패턴을 모델링해야 한다. 또한 음악은 음표 모음부터 여러 악기로 구성된 음악 구조에 이르기까지 다양한 패턴으로 구성되어 있기 때문에 생성하기 가장 까다로운 오디오 유형이라고 할 수 있다.
AI로 일관성 있는 음악을 생성하는 것은 종종 MIDI 또는 피아노 롤과 같은 상징적 표현을 사용하여 해결되었다. 그러나 이러한 접근 방식은 음악에서 발견되는 표현적 뉘앙스와 문체 요소를 완전히 파악할 수 없다.
최근에는 자기 지도형 오디오 표현 학습(Self-supervised Audio Representation Learning 참고)과 여러 계층적 또는 계단식 모델을 활용하여 음악을 생성하고, 원시 오디오를 복잡한 시스템에 공급하여 신호의 구조를 포착하는 동시에 고품질 오디오를 생성하는 기술이 발전하고 있다.
이번 공개된 오디오크래프트 모델은 장기간 일관성 있는 고품질 오디오를 생성할 수 있으며, 자연스러운 인터페이스를 통해 쉽게 상호작용할 수 있다. 오디오크래프트는 이 분야의 이전 작업에 비해 오디오 생성 모델의 전반적인 설계를 간소화하여 메타가 지난 몇 년간 개발해 온 기존 모델을 활용하면서 한계를 뛰어넘어 자신만의 모델을 개발할 수 있는 완전한 레시피를 제공한다.
오디오크래프트는 음악과 사운드 생성 및 압축을 모두 한 곳에서 처리한다. 구축 및 재사용이 쉽기 때문에 더 나은 사운드 생성, 압축 알고리즘 또는 음악을 생성하려는 사용자는 동일한 코드 기반에서 모든 작업을 수행한다.
오디오 생성에 대한 간단한 접근 방식
원시 오디오 신호에서 오디오를 생성하는 것은 매우 긴 시퀀스를 모델링해야 하므로 쉽지 않다. 44.1kHz(음악 녹음 표준 품질)로 샘플링된 몇 분 분량의 일반적인 음악 트랙은 수백만 개의 타임스텝으로 구성된다. 이에 비해, 라마(Llama) 또는 라마 2와 같은 텍스트 기반 생성 모델에는 샘플당 수천 개의 타임스텝을 나타내는 하위 단어로 처리된 텍스트가 제공된다.
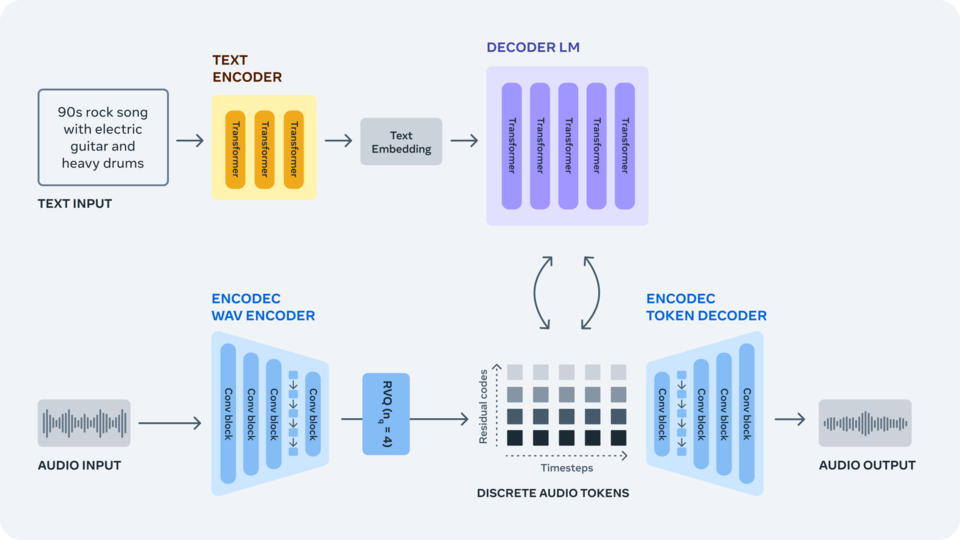
이 문제를 해결하기 위해 'EnCodec 신경 오디오 코덱(EnCodec neural audio codec- 다운)'을(관련 논문 고 충실도 신경 오디오 압축-다운) 사용하여 원시 신호에서 개별 오디오 토큰을 학습하여 음악 샘플에 대한 새로운 고정 '어휘'를 제공한다. 그런 다음, 이 개별 오디오 토큰에 대해 자동 회귀 언어 모델을 학습시켜 EnCodec의 디코더로 토큰을 오디오 공간으로 다시 변환할 때 새로운 토큰과 새로운 사운드 및 음악을 생성할 수 있는 것이다.
파형에서 오디오 토큰 학습하기
▶'엔코덱(EnCodec-논문, 코드 다운)'은 모든 종류의 오디오를 압축하고 원본 신호를 높은 충실도로 재구성하도록 특별히 훈련된 손실 신경 코덱이다. 이 코덱은 고정 어휘로 여러 병렬 오디오 토큰 스트림을 생성하는 잔여 벡터 양자화 병목 현상이 있는 자동 인코더로 구성된다. 서로 다른 스트림은 오디오 파형의 서로 다른 수준의 정보를 캡처하므로 모든 스트림에서 높은 충실도로 오디오를 재구성할 수 있다.
오디오 언어 모델 훈련
단일 자동 회귀 언어 모델을 사용하여 EnCodec의 오디오 토큰을 재귀적으로 모델링한다. 토큰 병렬 스트림의 내부 구조를 활용하는 간단한 접근 방식을 소개하고, 단일 모델과 우아한 토큰 인터리빙 패턴을 통해 오디오 시퀀스를 효율적으로 모델링하여 오디오의 장기적인 종속성을 동시에 포착하고 고품질 사운드를 생성한다.
텍스트 설명에서 오디오 생성
▶'오디오젠(AudioGen-논문 및 모델 다운)'을 통해 텍스트 오디오 생성 작업을 수행하도록 AI 모델을 훈련시키며, 텍스트 프롬프트로 "휘파람 소리", "사이렌 소리", "윙윙거리는 엔진이 접근하고 지나감", "해변에 어울리는 멜로디", "경쾌한 리듬의 팝 댄스 트랙", "우쿨렐레가 가미된 조화로운", "산뜻하고 여유로운" 등 음향 배경 및 장면에 대한 설명이 주어지면 모델은 사실적인 녹음 조건과 복잡한 장면 컨텍스트를 사용하여 설명에 해당하는 환경 사운드를 생성한다.
▶'뮤직젠(MusicGen-코드 다운)'은 음악 생성을 위해 특별히 맞춤화된 오디오 생성 모델이다. 음악 트랙은 환경 사운드보다 더 복잡하며, 새로운 음악 작품을 만들 때는 장기적인 구조에서 일관된 샘플을 생성하는 것이 특히 중요하다. MusicGen은 텍스트 설명 및 메타데이터와 함께 약 40만 개의 녹음을 학습했으며, 이는 메타가 소유하거나 이 용도로 특별히 라이선스를 취득한 20,000시간 분량의 음악에 해당한다.
한편, 메타는 이 연구를 바탕으로 고급 생성 AI 오디오 모델에 대한 연구를 계속하고 있으며, 이 AudioCraft 릴리스의 일부로 이산 표현 디코딩을 위한 확산 기반 접근 방식을 통해 합성 오디오의 품질을 높이는 새로운 접근 방식을 추가로 제공합니다. 우리는 오디오에 대한 생성 모델의 더 나은 제어 가능성을 계속 조사하고, 추가 컨디셔닝 방법을 탐색하고, 더 긴 범위의 종속성을 캡처할 수 있는 모델의 기능을 추진할 계획입니다. 마지막으로, 우리는 오디오에 대해 훈련된 그러한 모델의 한계와 편향을 계속 조사할 것입니다.
한편, 메타는 이 연구를 바탕으로 고급 생성 AI 오디오 모델에 대한 연구를 계속하고 있으며, 이번 AudioCraft 릴리스에서는 이산 표현 디코딩을 위한 확산 기반 접근 방식을 통해 합성 오디오의 품질을 향상시킬 수 있는 새로운 접근 방식을 추가로 제공한다.
또한 오디오 생성 모델의 제어 가능성을 개선하고, 추가적인 컨디셔닝 방법을 모색하며, 모델이 더 긴 범위의 종속성을 포착할 수 있도록 기능을 강화할 계획이며, 모델링 관점에서 속도와 효율성을 높이고 이러한 모델을 제어하는 방식을 개선하여 새로운 사용 사례와 가능성을 열어 현재, 모델을 지속적으로 개선하기 위해 노력하고 있다고 밝혔다.