Grok-1은 다음 토큰 예측을 수행하도록 사전 훈련된 자동 회귀 트랜스포머(Transformer) 기반 모델로 초기 Grok-1의 컨텍스트 길이는 8,192개 토큰이며, 모델은 인간 모델과 초기 Grok-0 모델의 광범위한 피드백을 사용하여 미세 조정되었다.

인공지능이 "문명 파괴"를 일으킬 가능성과 이 분야에 대한 규제 초안을 작성할 시간을 확보하기 위해 구글과 마이크로소프트와 같은 회사 간의 기술 개발 경쟁을 중단해야 한다고 주장하며, 지난 몇 년 간 AI에 말도 많고 탈도 많았던 일론 머스크(Elon Musk)는 지난 7월 12일, AI 스타트업 'x.AI'를 공식 출범을 알렸다.
이후 약 4개월 만인 지난 2일 영국 블레츨리 파크(Bletchley Park)에서 열린 ’제1차 AI 안전성 정상회의(AI Safety Summit)에 참석, 리시 수낵 영국 총리와 대담에서 AI와 로봇에서 그 영향까지 광범위한 주제를 통해 "인공지능과 함께하는 미래는 풍요로운 시대가 될 것이며, 로봇(휴머노이드)이 좋은 친구가 될 것이지만 우려도 해야 한다"며, "AI는 역사상 가장 파괴적이지만 결국, 인간보다 더 똑똑한 휴머노이드가 탄생 될 것”이라고 우려를 나타냈다.
이어, 지난 3일 머스크는 자신의 엑스(X) 계정에 "내일 xAI가 첫 번째 AI를 선별된 그룹에 공개할 것"이라며, "이는 몇 가지 중요한 측면에서 그것은 현존하는 최고의 인공지능"이라고 밝히고 4일(현지시간) 자신의 X(트위터) 계정에 그의 첫 번째 작품인 대화형 생성 AI 챗봇인 '그록(Grok)'에 대한 출시와 정보를 일부 공개했다.

이날 머스크는 다른 AI 모델에 비해 Grok의 "엄청난 장점"은 X에 "실시간으로 액세스"할 수 있다는 점으로 다른 인공지능보다 많은 장점과 이점이 있으며 "풍자를 좋아하며" 응답에 "약간의 유머"를 갖도록 설계되었다고 머스크는 언급했다.
이날 xAI의 발표에 따르면 Grok을 구동하는 엔진은 설립후 지난 4개월 동안 개발한 개척 대형언어모델(LLM)인 Grok-1이다. 이 모델은 질의 응답, 정보 검색, 창의적 글쓰기 및 코딩 지원을 포함한 자연어 처리(NLP) 작업을 수행한다.
머스크에 따르면 xAI를 설립 발표한 후 330억 개의 매개변수의 프로토타입 LLM(Grok-0)을 학습했다. 이 초기 모델은 표준 LM 벤치마크에서 메타의 라마 2(LLaMA 2-70B) 기능에 근사하지만 학습 리소스는 절반만 사용한다. 지난 2개월 동안 훨씬 더 강력한 최첨단 언어 모델인 Grok-1으로 이어지는 추론 및 코딩 기능을 대폭 개선하여 MMLU(Massive Multitask Language Understanding)과 휴먼에벌(HumanEval) 코딩 작업에서 63.2%, 73%를 각각 달성했다고 밝혔다.
또한 Grok-1을 통해 달성한 기능 향상을 이해하기 위해 수학과 추론 능력을 측정하도록 설계된 ▷GSM8k: 중학교 수학 단어 문제(Cobbe 외. 2021), 연쇄 사고 프롬프트 사용. ▷MMLU: 다분야 객관식 문제(Hendrycks 외. 2021), 맥락에 맞는 5지선다형 예제 제공. ▷휴먼에벌: 파이썬 코드 완성 과제(Chen 외. 2021), 제로 샷으로 평가 ▷수학: LaTeX로 작성된 중학교 및 고등학교 수학 문제(Hendrycks 외. 2021), 고정된 4샷 프롬프트가 표시된다) 등 4 가지 표준 머신러닝 벤치마크를 사용하여 일련의 평가를 수행했다.
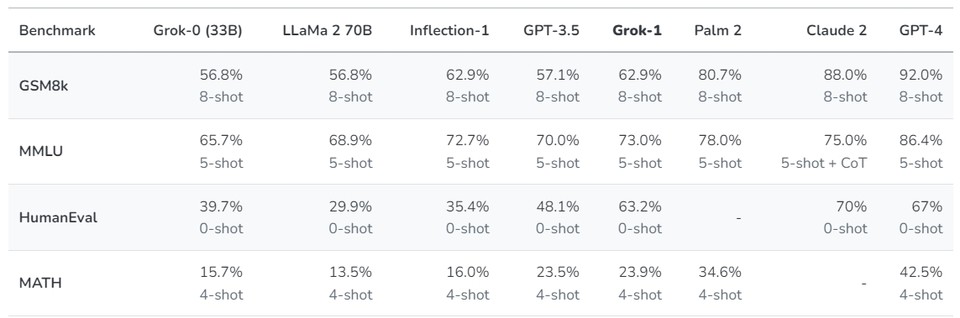
결과적으로 이러한 벤치마크에서 Grok-1은 ChatGPT-3.5와 Inflection-1을 포함한 동급의 다른 모든 모델을 능가하는 강력한 결과를 보여주었다. GPT-4와 같이 훨씬 더 많은 양의 훈련 데이터와 컴퓨팅 리소스로 훈련된 모델만 능가했다. 이는 xAI가 뛰어난 효율성으로 LLM을 훈련하는 데 있어 빠른 진전을 보이고 있음을 보여준 것으로 보인다.
특히, 이러한 벤치마크는 웹에서 쉽게 찾을 수 있다. 이에 xAI 모델이 실수로 이 벤치마크를 학습했을 가능성을 배제할 수 없기 때문에, 데이터 세트를 수집한 후 5월 말에 발표된 2023년 헝가리 전국 고등학교 수학 기말고사 성적에 대해 xAI 모델(그리고 Claude-2와 GPT-4)을 직접 채점해(아래 표 참조) 보았다.

결과족으로 Grok은 C(59%)로 시험에 합격했고, 클로드-2는 같은 성적(55%)을, GPT-4는 68%로 B를 받았다. 이 평가를 위해 xAI는 어떠한 튜닝도 하지 않았다. 이 실험은 모델이 명시적으로 튜닝되지 않은 데이터 세트에 대한 '실제' 테스트였다.
딥러닝 연구의 최전선에서는 데이터 세트 및 학습 알고리즘과 마찬가지로 주의를 기울여 안정적인 인프라를 구축해야 한다. Grok을 만들기 위해 xAI는 Kubernetes, Rust 및 JAX를 기반으로 맞춤형 훈련 및 추론 스택을 구축했다.
Grok-1은 다음 토큰 예측을 수행하도록 사전 훈련된 자동 회귀 트랜스포머(Transformer) 기반 모델로 초기 Grok-1의 컨텍스트 길이는 8,192개 토큰이다. 모델은 인간 모델과 초기 Grok-0 모델의 광범위한 피드백을 사용하여 미세 조정되었다.
현재, 그록은 미국 내 제한된 수의 사용자에게 Grok 프로토타입을 시험해 보고 정식 출시 전에 기능을 개선하는 데 도움이 될 귀중한 피드백을 제공하고 있다. 사용자는 Grok 대기자 명단에 등록할 수 있으며(보기), 이 릴리스는 xAI의 첫 번째로 앞으로 흥미로운 로드맵을 갖고 있으며 앞으로 몇 달 안에 새로운 기능을 선보일 예정이라고 4일(현지시간) 밝혔다.
한편, 그록의 초기 베타 버전은 서비스가 종료되면 X(트위터) 프리미엄 플러스(Premium+) 일부로 제공되며, 사용료는 월 16달러(약 21,000원)로 책정됐다. 이는 월 20달러(약 26,000원)를 지불하는 오픈 AI의 유료 서비스인 챗GPT플러스(ChatGPT Plus)보다 4달러 싸지만 그 성능면에서는 아직 미지수(실전에서)다.