윈도우 11 PC에서 실행되는 새로운 모델 지원 추가, 오픈AI 채팅 API용 텐서RT-LLM 래퍼, 라마2용 다이렉트ML 등 RTX 기반 성능 향상 포함
엔비디아가 텐서RT-LLM(TensorRT-LLM) 업데이트를 통해 인공지능(AI) 추론 성능을 향상하고 새로운 대규모 언어 모델 지원을 추가한다고 15일(현지시간) 밝혔다. 더불어 VRAM 8GB 이상 RTX GPU가 탑재된 데스크톱과 노트북에서 까다로운 AI 워크로드에 대한 보다 쉬운 액세스를 지원할 계획이다.
윈도우(Windows) 11 PC의 AI는 테크 분야에 있어 획기적인 전환점이다. 이는 게이머, 크리에이터, 스트리머, 직장인, 학생은 물론이고 일반 PC 사용자에게도 혁신적인 경험을 제공한다.
AI 탑재를 통해 1억 대가 넘는 윈도우 PC와 RTX GPU 기반 워크스테이션에서 사용자의 생산성을 전례 없이 향상시킬 수 있게 됐다. 또한 엔비디아 RTX 기술은 개발자가 컴퓨터 사용 방식을 변화시킬 AI 애플리케이션을 보다 쉽게 개발할 수 있도록 지원한다.
마이크로소프트 이그나이트(Microsoft Ignite)에서 발표된 새로운 최적화, 모델, 리소스는 개발자가 새로운 최종 사용자 경험을 더 빠르게 제공할 수 있도록 돕는다.
윈도우용 텐서RT-LLM은 곧 새로운 래퍼(Wrapper)를 통해 오픈AI(OpenAI)의 인기 채팅 API와 호환될 예정이다. 이를 통해 수백 개의 개발자 프로젝트와 애플리케이션을 클라우드가 아닌 RTX가 탑재된 PC에서 로컬로 실행할 수 있으며, 개인이나 고유 데이터를 윈도우 11 PC에 저장할 수 있다.
맞춤 생성형 AI는 프로젝트 유지에 많은 시간과 에너지를 소모한다. 특히 다양한 환경과 플랫폼에서 협업과 배포를 진행할 경우 프로세스가 매우 복잡하고 오랜 시간이 소요될 수 있다.
AI 워크벤치(AI Workbench)는 간편한 통합 툴킷으로, 개발자가 PC 또는 워크스테이션에서 사전 훈련된 생성형 AI 모델과 LLM을 빠르게 생성, 테스트, 사용자 지정할 수 있도록 지원한다. 더불어 AI 프로젝트 구성과 특정 사용 사례에 맞는 모델 조정을 위한 단일 플랫폼을 제공한다.
이를 통해 원활한 협업과 배포가 가능해지며, 개발자들은 비용 효율적이고 확장 가능한 생성형 AI 모델을 빠르게 개발할 수 있다. 얼리 액세스에 등록하면 빠르게 확장되는 이니셔티브에 가장 먼저 액세스하고 향후 업데이트를 받을 수 있다.
엔비디아와 마이크로소프트는 AI 개발자를 지원하기 위해 새로운 다이렉트ML(DirectML) 개선 사항을 출시한다. 이로써 가장 인기 있는 파운데이션 AI 모델 중 하나인 라마 2(Llama 2)를 가속해 성능에 대한 새로운 표준을 설정하고 공급업체 간 배포를 위한 더 많은 옵션을 제공한다.
지난 달 엔비디아는 LLM 추론 가속을 위한 라이브러리인 윈도우용 텐서RT-LLM을 발표했다.
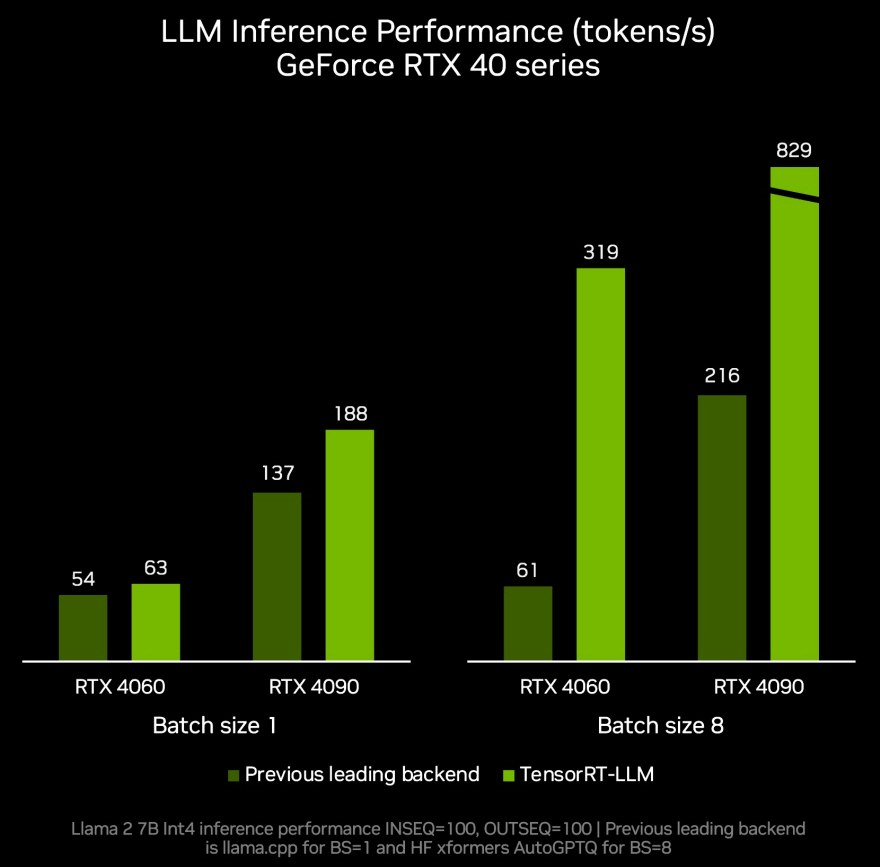
이달 말에 출시될 텐서RT-LLM v0.6.0에서는 추론 성능이 최대 5배 더 빨라지고, 새로운 미스트랄(Mistral) 7B와 네모트론(Nemotron)-3 8B를 비롯한 인기 LLM을 추가로 지원할 수 있다. 이러한 LLM 버전은 8GB 이상의 RAM이 탑재된 모든 지포스(GeForce) RTX 30 시리즈와 40 시리즈 GPU에서 실행되며, 휴대성이 가장 뛰어난 일부 윈도우 디바이스에서도 빠르고 정확한 로컬 LLM 기능을 이용할 수 있다.
전 세계의 개발자와 애호가들은 웹 콘텐츠 요약, 문서와 이메일 초안 작성, 데이터 분석과 시각화, 프레젠테이션 제작 등 다양한 애플리케이션에서 오픈AI의 챗(Chat)API를 사용하고 있다.
이러한 클라우드 기반 AI가 당면한 한 가지 과제는 사용자가 입력 데이터를 업로드해야 하므로 개인 또는 고유 데이터나 대규모 데이터 세트 작업에는 적합하지 않다는 점이다.
엔비디아는 이러한 문제를 해결하기 위해, 새로운 래퍼로 윈도우용 텐서RT-LLM에도 오픈AI의 챗API와 유사한 API 인터페이스를 지원할 예정이다. 이로써 모델과 애플리케이션 설계 시 RTX가 탑재된 PC 로컬 환경과 클라우드 환경 모두에서 유사한 워크플로우를 제공할 수 있다. 이제 코드를 한두 줄만 변경하면 수백 개의 AI 기반 개발자 프로젝트와 애플리케이션에서 신속한 로컬 AI의 이점을 누릴 수 있다. 사용자는 데이터 세트를 클라우드에 업로드할 걱정 없이 데이터를 PC에 저장할 수 있다.
가장 좋은 점은 이러한 프로젝트와 애플리케이션 중 상당수가 오픈 소스로 제공돼 개발자가 쉽게 기능을 활용하고 확장해 RTX 기반의 윈도우에서 생성형 AI 채택을 촉진할 수 있다는 것이다.
이 래퍼는 텐서RT-LLM에 최적화된 라마2, 미스트랄, NV LLM 등과 같은 모든 LLM과 호환된다. 또한 RTX에서 LLM으로 작업하기 위한 다른 개발자 리소스와 함께 깃허브(GitHub)에 참조 프로젝트로 공개되고 있다.
이제 개발자는 최첨단 AI 모델을 활용하고 크로스벤더(cross-vendor) API로 배포할 수 있다. 엔비디아와 마이크로소프트는 다이렉트ML API로 RTX에서 라마를 가속하기 위해 협력해 왔다. 이는 개발자 역량 강화를 위한 두 기업의 지속적인 노력의 일환이다.
공급업체 간 배포를 위한 최신 옵션은 지난달 발표된 가장 빠른 추론 성능에 대한 발표를 기반으로 하며, 그 어느 때보다 쉽게 PC에 AI 기능을 제공할 수 있도록 지원한다.
최신 최적화를 경험하기 위해서는 최신 ONNX 런타임(runtime)을 다운로드하고 마이크로소프트의 설치 지침을 따라야 한다. 더불어 11월 21일에 출시될 엔비디아의 최신 드라이버 설치가 필요하다.
이러한 새로운 최적화, 모델, 리소스를 통해 전 세계 1억 대의 RTX PC에 AI 기능과 애플리케이션의 개발과 배포를 가속할 수 있다. 아울러 이미 RTX GPU로 가속된 AI 기반 앱과 게임을 제공하는 400개 이상의 파트너와 함께하게 된다.
모델에 대한 접근성이 더욱 향상되고 개발자가 RTX 기반 윈도우 PC에 더 많은 AI 기반 기능을 제공하고 있다. 이러한 기술 활용할 수 있도록 사용자에게는 RTX GPU가 핵심적인 역할을 할 것이다.