패트릭 루이스는 RAG를 ‘범용 미세 조정 레시피’라고 칭했다. 이는 RAG가 거의 모든 LLM에서 모든 외부 리소스와 연결하는 데 사용...

생성 AI의 최근 발전을 더 현실적으로 이해하기 위해 법정의 모습을 생각해 볼 수 있다.
예를 들어, 판사는 법에 대한 일반적인 이해를 바탕으로 사건을 심리하고 판결한다. 의료 과실 소송이나 노동 분쟁과 같이 특별한 전문 지식이 필요한 사건의 경우, 판사는 법원 서기관에게 인용할 수 있는 판례와 구체적인 사례를 찾게 한다.
훌륭한 판사처럼 대형언어모델(LLM)은 다양한 사람의 질의에 응답할 수 있다. 하지만 출처가 정확한 신뢰할 수 있는 답변을 제공하려면, 조사를 수행할 조수가 필요하다.
바로 '검색 증강 생성(Retrieval Augmented Generation. 이하, RAG)'라고 하는 프로세스가 AI처럼 법원 서기관의 역할을 한다.
현재, 기업용 인공지능에 중점을 두고 LLM을 전문으로 하는 캐나다 다국적 AI 스타트업 '코히어(Cohere)'에서 RAG팀을 이끌고 있는 패트릭 루이스(Patrick Lewis)는 2020년 한 논문 '지식 집약적 NLP 작업을 위한 검색 증강 생성(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks-다운)'에서 RAG라는 용어를 처음 만들었다.
그는 수백 편의 논문과 수십 개의 상용 서비스에서 이 용어가 생성 AI의 미래를 대표한다고 여겨지는 방법군을 설명하는 것에 대해 유감을 표시했다.

패트릭 루이스는 지역 컨퍼런스에서 데이터베이스 개발자들과 자신의 아이디어를 공유한 싱가포르의 한 인터뷰 자리에서 "우리의 연구가 이렇게 널리 퍼질 줄 알았다면 이름에 더 많은 고민을 했을 것이다. 항상 더 멋진 이름을 계획했지만, 막상 논문을 쓸 때가 되자 아무도 더 좋은 아이디어를 내놓지 못했다”고 말했다.
그럼 RAG란 무엇인가?
RAG는 외부 소스에서 가져온 정보로 생성 AI 모델의 정확성과 신뢰성을 향상시키는 기술이다.
즉, LLM의 작동 방식에서 부족한 부분을 채워주는 기술이다. LLM은 내부적으로 신경망이며, 일반적으로 얼마나 많은 매개변수가 포함되어 있는지에 따라 측정된다. LLM의 매개변수는 기본적으로 인간이 단어를 사용해 문장을 구성하는 일반적인 패턴을 나타낸다.
‘매개변수화된 지식’이라고도 하는 이러한 심층적인 이해 덕분에, LLM은 일반적인 프롬프트에 빠른 속도로 응답하는 데 유용하다. 그러나 최신 주제나 특정 주제에 대해 더 깊이 알고 싶어하는 사용자에게는 적합하지 않다.
내부와 외부 리소스의 결합
패트릭 루이스와 동료들은 RAG 기술을 개발해 생성 AI 서비스를 외부 리소스, 특히 최신 기술 정보가 풍부한 리소스에 연결했다.
메타 AI 연구소(Meta AI Research), 유니버시티 칼리지 런던(University College London), 뉴욕대학교(New York University)의 공동 저자들이 참여한 논문(위 논문 참조)에서 RAG를 ‘범용 미세 조정 레시피’라고 칭했다. 이는 RAG가 거의 모든 LLM에서 모든 외부 리소스와 연결하는 데 사용할 수 있기 때문이다.
사용자 신뢰 구축
RAG는 연구 논문의 각주처럼 모델에 인용할 수 있는 소스를 제공한다. 따라서 사용자는 모든 출처를 확인할 수 있으며, 이는 사용자의 신뢰도를 강화한다. 또한, 이 기술은 모델이 사용자 쿼리의 모호함을 해소하는 데 도움이 된다. 즉, 모델이 잘못된 추측을 할 가능성인 환각 현상을 감소시킨다.
RAG의 또 다른 큰 장점은 비교적 쉽다는 것이다. 패트릭 루이스와 논문 공동 저자 3명의 메타 블로그(보기)에 따르면, 개발자는 단 5줄의 코드(보기)만으로 이 프로세스를 구현할 수 있다(아래는 생성 예).

따라서 추가 데이터 세트로 모델을 재훈련하는 것보다 더 빠르고 비용이 적게 든다. 또한 사용자가 새로운 소스를 즉시 핫스왑(hot-swap)할 수 있다.
사람들이 RAG를 사용하는 방법
사용자는 RAG를 통해 기본적으로 데이터 저장소와 대화할 수 있고, 새로운 경험을 하게 된다. 즉, RAG의 응용 분야는 사용 가능한 데이터 세트 수의 몇 배에 달한다.
예를 들어, 의료 지수로 보강된 생성형 AI 모델은 의사나 간호사를 위한 훌륭한 보조 도구가 될 수 있다. 재무 분석가는 시장 데이터에 연결된 비서의 도움을 받을 수 있다.
실제로 거의 모든 비즈니스에서 기술, 정책 매뉴얼, 동영상, 로그 등을 지식 베이스라는 리소스로 전환해 LLM을 향상시킬 수 있다. 이러한 리소스는 고객과 현장 지원, 직원 교육, 개발자 생산성 등의 분야에서 활용될 수 있다.
이러한 광범위한 잠재력 때문에 엔비디아를 비롯한 구글(Google), 마이크로소프트(Microsoft), 아마존웹서비스(AWS-보기), IBM(보기), 글린(Glean-보기), 오라클(Oracle-보기), 파인콘(Pinecone-보기), 엘라스틱(Elastic-보기) 등 글로벌 빅테크 기업들이 RAG를 채택하고 있다.
그 중에서 엔비디아의 사례를 살펴본다. 엔비디아는 사용자의 작업을 돕기 위해 RAG를 위한 레퍼런스 아키텍처(Reference Architecture-보기)를 개발했다. 여기에는 사용자가 이 새로운 방식으로 자체 애플리케이션을 만드는 데 필요한 요소와 샘플 챗봇이 포함된다.

이 워크플로우에서는 생성 AI 모델을 개발하고 맞춤화하기 위한 엔비디아 네모(NeMo) 프레임워크와 제작 단계에서 생성 AI 모델을 실행하기 위한 엔비디아 트리톤 추론 서버(Triton Inference Server), 엔비디아 텐서RT-LLM(TensorRT-LLM)과 같은 소프트웨어가 사용된다.
이 소프트웨어는 엔비디아 AI 엔터프라이즈(AI Enterprise)의 일부로 구성된다. 이는 비즈니스에 필요한 보안, 지원, 안정성을 갖춰 제작 준비가 된 AI의 개발과 배포를 가속화한다.
RAG 워크플로우를 위한 최상의 성능을 얻으려면 데이터를 이동하고 처리하는 데 방대한 양의 메모리와 컴퓨팅이 필요하다. 288GB의 고속 HBM3e 메모리와 8페타플롭(Petaflops)의 컴퓨팅 성능을 갖춘 엔비디아 GH200 그레이스 호퍼 슈퍼칩(GH200 Grace Hopper Superchip)은 CPU를 사용할 때보다 150배 빠른 속도를 제공할 수 있는 이상적인 제품이다.
RAG에 익숙해지면 다양한 기성 또는 맞춤형 LLM을 내부와 외부 지식 기반과 결합해 직원과 고객을 돕는 광범위한 보조 기능을 만들 수 있다.
RAG는 데이터 센터를 따로 요구하지 않는다. 엔비디아 소프트웨어 덕분에 사용자는 노트북에서도 액세스할 수 있는 모든 애플리케이션을 지원해 윈도우 PC(Windows PC)에서 LLM을 사용할 수 있다.
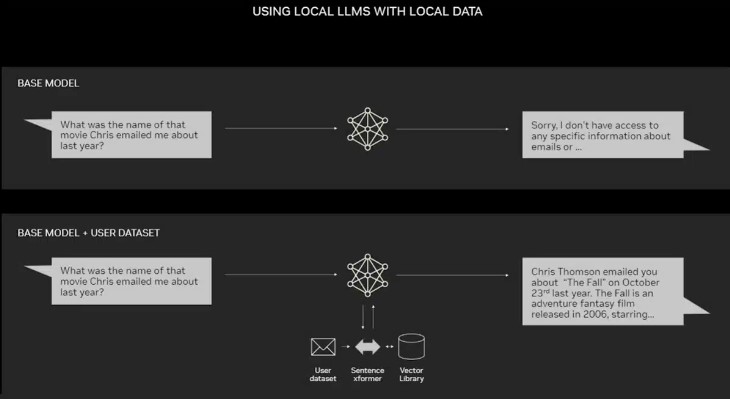
이제 엔비디아 RTX GPU가 탑재된 PC에서 일부 AI 모델을 실행할 수 있다. 사용자는 PC에서 RAG를 사용해 이메일, 메모, 기사 등 프라이빗 지식 소스에 연결하고 응답을 개선할 수 있다. 이를 통해 사용자는 데이터 소스, 프롬프트, 응답이 모두 비공개로 안전하게 유지된다는 확신을 가지게 된다.
최근 블로그에서 더 나은 결과를 빠르게 얻기 위해 윈도우용 텐서RT-LLM으로 가속화된 RAG의 사례(보기)를 확인할 수 있다.
RAG의 역사
이 기술의 근원은 적어도 1970년대 초로 거슬러 올라간다. 정보 검색 분야의 연구원들이 처음에는 야구와 같은 좁은 주제에서 자연어 처리(NLP)를 사용해 텍스트에 액세스하는 앱인 질문-응답 시스템이라는 프로토타입을 만들었던 시기이다.
이러한 종류의 텍스트 마이닝의 개념은 수년 동안 꾸준히 유지되어 왔다. 그러나 이를 구동하는 머신러닝 엔진은 크게 성장해 그 유용성과 인기가 높아졌다.
1990년대 중반, 현재 애스크닷컴(Ask.com)인 애스크지브스(Ask Jeeves) 서비스는 잘 차려입은 마스코트 캐릭터로 질문 응답을 대중화했다. IBM의 왓슨(Watson)은 2011년 게임 쇼인 제퍼디(Jeopardy!)에서 인간 챔피언 두 명을 가볍게 꺾으며 TV 스타로 떠올랐다.

오늘날 LLM은 질문 답변 시스템을 완전히 새로운 차원으로 발전시키고 있다.
런던 연구소에서 얻은 인사이트
RAG를 언급했을 2020년에 패트릭 루이스는 유니버시티 칼리지 런던에서 NLP 박사 학위를 취득하고 런던의 새로운 AI 연구소에서 메타를 위해 일하고 있었다. 연구팀은 LLM의 매개변수에 더 많은 지식을 담을 수 있는 방법을 찾고 있었고, 자체 개발한 벤치마크를 사용해 진행 상황을 측정하고 있었다.
연구팀은 이전의 방법을 기반으로 구글 연구원의 논문(REALM: 검색-증강 언어 모델 사전 훈련-다운)에서 영감을 얻었다. 패트릭 루이스는 "검색 인덱스가 중간에 있는 훈련된 시스템으로, 원하는 텍스트 출력을 학습하고 생성할 수 있다는 매력적인 비전을 갖고 있었다"고 말했다.

패트릭 루이스가 진행 중인 작업에 다른 메타 팀의 우수한 검색 시스템을 연결했을 때, 첫 번째 결과는 예상 외로 놀라웠다.
그는 "상사에게 결과를 보여 주었더니 아주 잘했다는 긍정적인 답변을 받았다. 이러한 워크플로우는 처음에 올바르게 설정하기 어려울 수 있어 이런 일은 자주 일어나지 않는다"고 말했다.
패트릭 루이스는 또한 당시 뉴욕대학교와 페이스북(Facebook) AI 리서치에 각각 재직 중이던 팀원 에단 페레즈(Ethan Perez)와 도위 키에라(Douwe Kiela)의 공로를 인정했다.
엔비디아 GPU 클러스터에서 실행된 이 작업은 생성형 AI 모델을 더욱 정확하고 신뢰할 수 있게 만드는 방법을 보여줬다. 이후 이 연구는 수백 개의 논문에서 인용돼 개념을 확장했으며, 현재도 활발한 연구 분야로 자리 잡고 있다.
RAG의 작동 방식
사용자가 LLM에 질문을 하면 AI 모델은 기계가 읽을 수 있도록 쿼리를 숫자 형식으로 변환하는 다른 모델에 쿼리를 전송한다. 쿼리의 숫자 버전을 임베딩 또는 벡터라고 부른다.
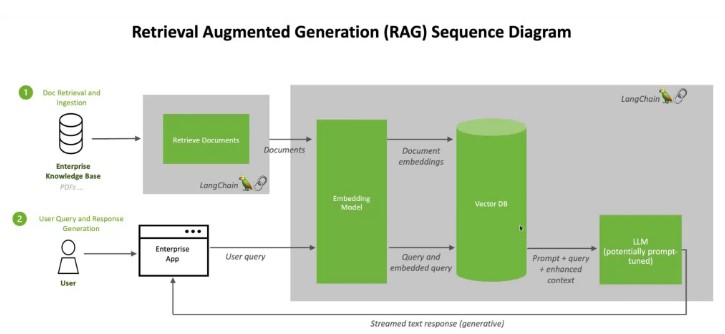
그런 다음 임베딩 모델은 이러한 숫자 값을 기계가 읽을 수 있는 지식 기반의 인덱스에서 벡터와 비교한다. 일치하는 항목이 하나 또는 여러 개 발견되면 관련 데이터를 검색해 사람이 읽을 수 있는 단어로 변환한 후 LLM에 다시 전송한다.
마지막으로 LLM은 검색된 단어와 쿼리에 대한 자체 응답을 결합해 임베딩 모델이 찾은 소스를 인용하고 사용자에게 최종 답변을 제시한다.
소스를 최신 상태로 유지
임베딩 모델은 백그라운드에서 새롭고 업데이트된 지식창고를 사용할 수 있게 되면 벡터 데이터베이스라고도 하는 기계 판독 가능 인덱스를 지속적으로 생성하고 업데이트한다.
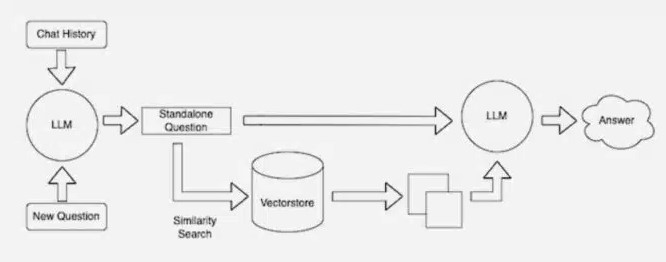
많은 개발자들은 오픈 소스 라이브러리인 랭체인(LangChain)이 LLM을 연결하고 모델과 지식 기반을 통합하는 데 특히 유용하다고 생각한다. 엔비디아는 RAG를 위한 레퍼런스 아키텍처에서 랭체인을 사용한다.
랭체인 커뮤니티는 RAG 프로세스에 대한 자체 설명을 제공하고 있다.
한편, 생성형 AI의 미래는 모든 종류의 LLM과 지식 베이스를 창의적으로 연결해 사용자가 확인할 수 있고, 신뢰도 높은 결과를 제공하는 새로운 종류의 조수를 만든다. 엔비디아 런치패드 랩(LaunchPad Lab-보기)에서 AI 챗봇으로 RAG를 직접 사용할 수 있다.(아래는 머신러닝 스티리트 토크의 패트릭 루이스 박사와 '검색 증강 생성'에 대한 인터뷰 영상이다)
(아래는 영상은 IBM의 검색 증강 생성(RAG)이란 무엇입니까?)