자사 통이체인원에 720억개 파라미터 적용한 72B(Qwen-72B)와 엣지용 18억 개 파라미터 ‘큐원-1.8B(Qwen-1.8B)’과 오디오 자료 처리 가능한 ‘큐원-오디오’ 및 ‘큐원-오디오-챗’도 함께 공개

알리바바그룹이 자체 개발한 대형언어모델(LLM) ‘통이치엔원(Tongyi Qianwen)’의 720억 개 파라미터 버전 ‘큐원-72B(Qwen-72B)’와 18억 개 파라미터 버전인 ‘큐원-1.8B(Qwen-1.8B)’을 자사 인공지능(AI) 모델 커뮤니티 ‘모델스코프(ModelScope)’와 협업해 오픈소스로 공개했다.
누구나 연구와 상업적 목적을 위해 활용할 수 있는 사전 학습된 오디오 이해 모델 ‘큐원-오디오(Qwen-Audio)’ 및 대화형으로 미세 조정된 버전인 ‘큐원-오디오-챗(Qwen-Audio-Chat)’도 추가로 공개했다.
현재까지 알리바바 클라우드는 7B, 14B, 18B 및 72B 파라미터까지 다양한 크기의 LLM과 오디오 및 비주얼 판독 기능을 갖춘 멀티모달 LLM을 제작하는데 기여했다.
징런 저우(Jingren Zhou) 알리바바 클라우드 CTO는 "오픈소스 생태계를 구축하는 것은 LLM 및 인공지능 애플리케이션 개발에 매우 핵심적인 일이다"며, "알리바바 클라우드는 가장 개방적인 클라우드로서 모든 사람이 생성형 AI 역량을 활용할 수 있도록 하는 것을 목표로 한다”고 밝혔다.
이어 그는 “이러한 목표를 달성하기 위해 자사의 최첨단 기술을 공유하고 파트너들과 함께 오픈소스 커뮤니티의 발전을 촉진해 나갈 것이다”라고 덧붙였다.
‘큐원-72B’은 3조 개 이상의 토큰으로 사전 학습되어 주요 오픈소스 모델들을 10가지 벤치마크 부문에서 초월한다. 대표적으로 앞선 벤치마크 부문은 대규모 다중작업 언어이해(MMLU, Massive Multi-task Language Understanding), 코드 개발 역량 테스트인 휴먼이발(HumanEval) 및 수학 문제를 푸는 GSM8K 등이 있다.
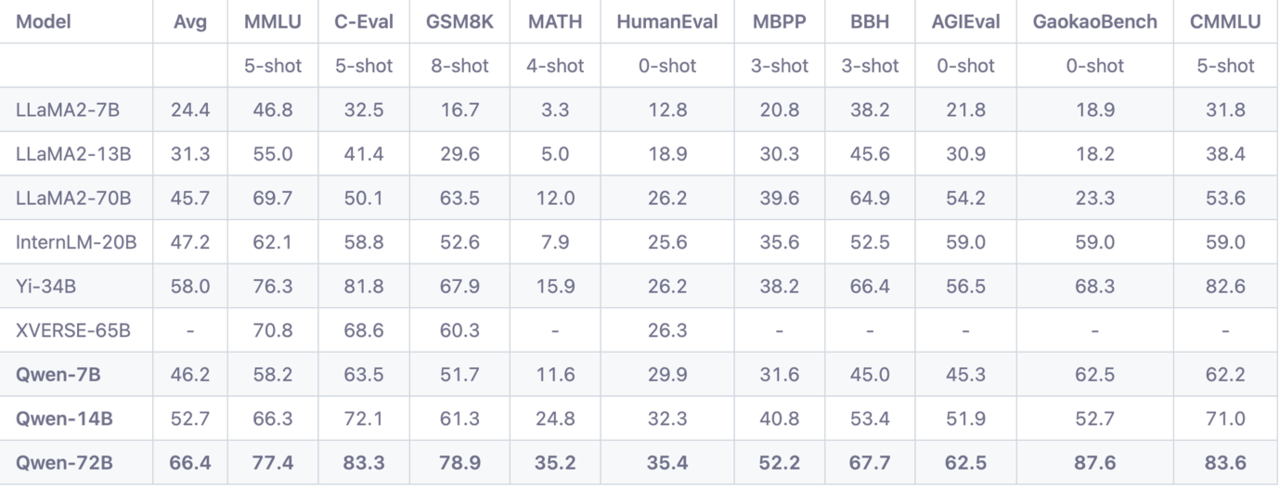
해당 모델 ‘큐원-72B’는 역할극인 롤 플레이, LLM이 특정 역할이나 페르소나를 취해 맥락에 보다 맞는 응답을 생성하는 능력을 드러내는 언어 스타일 이전(language style transfer) 등 다양하고 복잡한 작업을 처리하는 데 탁월한 성능을 보인다. 이러한 기능은 개인화된 챗봇과 같은 AI 애플리케이션에서 유용하게 사용될 수 있다.
기업과 연구기관들은 큐원-72B 모델을 연구 목적으로 활용 시 코드, 모델 가중치 및 도큐멘테이션(설명서)를 무료로 활용할 수 있다. 상업적 용도의 경우, 월간 활성 사용자 수가 1억 명 미만인 기업에 한해서 무료로 사용할 수 있다.
또한, 알리바바 클라우드는 엣지에서 실행할 수 있는 18억 개의 파라미터로 구성된 LLM ‘큐원-1.8B’도 오픈소스화 했다. 경량 버전인 큐’원-1.8B’는 컴퓨터 리소스가 제한된 휴대폰과 같은 엔드 장치에서 추론을 가능하게 한다.
작은 규모의 LLM 모델은 컴퓨팅 리소스 요구사항이 적어 비용 효율적이며 배포가 용이한 대안을 찾는 경우 유용하다. 큐원-1.8B는 현재 연구 목적으로만 활용 가능하다.
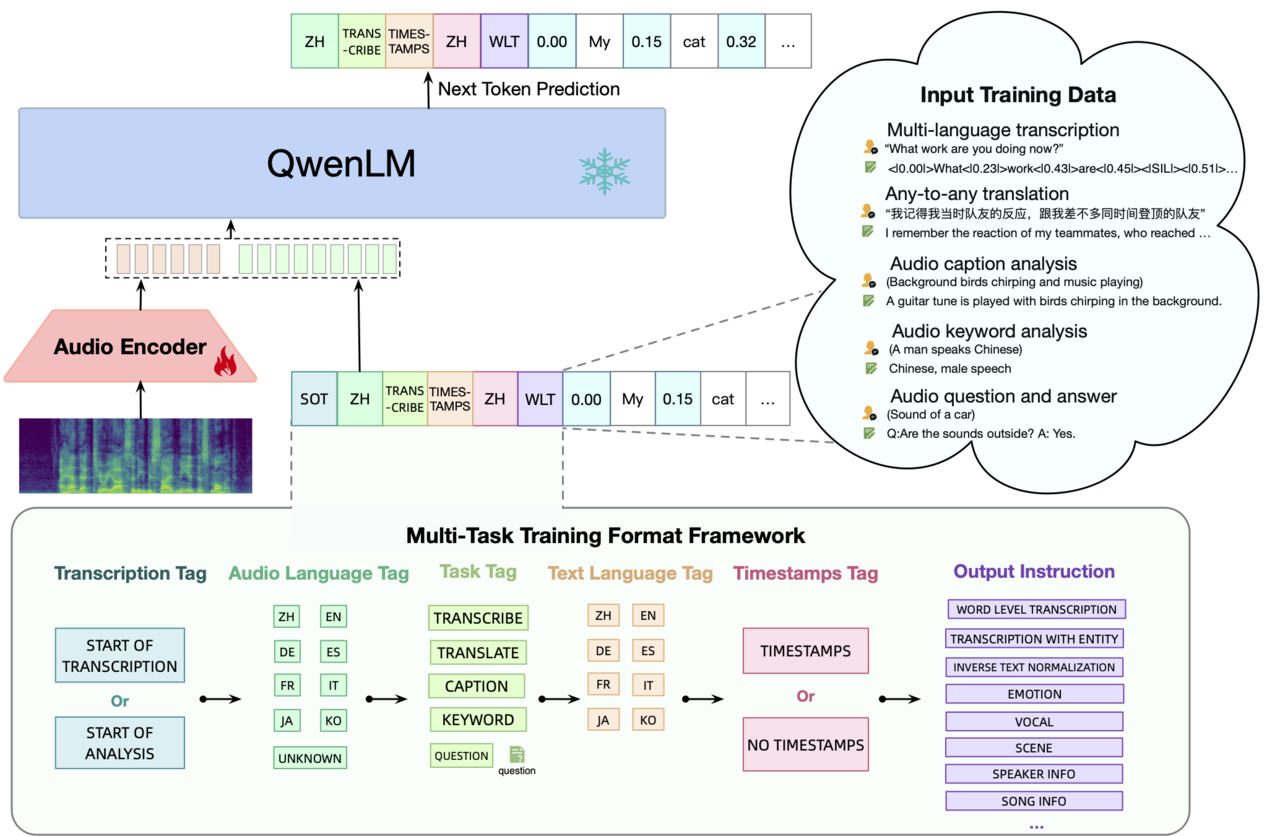
더 다양한 자료 입력 방식(input format)을 처리할 수 있는 LLM을 제공하기 위해, 알리바바 클라우드는 오디오 이해 성능이 강화된 모델인 ‘큐원-오디오(Qwen-Audio)’ 및 ‘큐원-오디오-챗(Qwen-Audio-Chat)’도 오픈소스로 공개했다.
‘큐원-오디오’는 사람의 음성, 자연음, 음악 등 다양한 형식의 텍스트와 오디오 투입 자료를 해석해 텍스트로 출력할 수 있다. 동 모델은 다국어 녹취록 작성(transcription), 음성 편집, 오디오 캡션 분석 등 30종류 이상의 오디오 처리 작업을 수행할 수 있다. 대화형 버전인 ‘큐원-오디오-챗’은 오디오를 기반으로 수차례의 질의응답을 지원하고, 사람의 감정과 톤을 감지하는 등 다양한 오디오 데이터를 처리할 수 있다.

알리바바 클라우드의 이러한 이니셔티브는 다양한 데이터 유형을 처리할 수 있는 멀티모달 LLM을 오픈소스 커뮤니티에 제공하려는 노력을 반영한다. 이미 앞서 올해초 시각 정보를 이해하고 시각적 작업을 수행하는 오픈소스 대형 비전 언어 모델 ‘큐원-VL(Qwen-VL)’과 큐원-VL의 채팅 버전 ‘큐원-VL-챗(Qwen-VL-Chat)’를 출시한 바 있다.

이제까지 큐원 7B, 14B, VL 및 대화형의 오픈소스 LLM 모델 포함한 알리바바 클라우드의 LLM 들은 지난 8월 이후 자사 오픈소스 AI 모델 커뮤니티인 ‘모델스코프’와 ‘허깅페이스’에서 총 150만 회 이상의 다운로드를 기록했다. 모델스코프는 280만 명 이상의 개발자가 활동하는 중국 최대의 AI 모델 커뮤니티로 성장했으며, 현재까지 1억 건 이상의 모델 다운로드를 기록했다.
한편, 알리바바가 오픈소스로 공개한 ‘큐원-72B’와 ‘큐원-1.B’에 대한 도구는 모델스코프, 허깅페이스(다운) 및 깃허브(다운)를 통해 다운받아 누구나 사용할 수 있으며, 더 자세한 내용은 ‘큐원-오디오’의 관련 논문 'Qwen-Audio: 통합된 대규모 오디오 언어 모델을 통해 범용 오디오 이해 향상(Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models-다운)'을 참고 하면되며, 또한 직접 체험해 볼 수(보기) 있다.