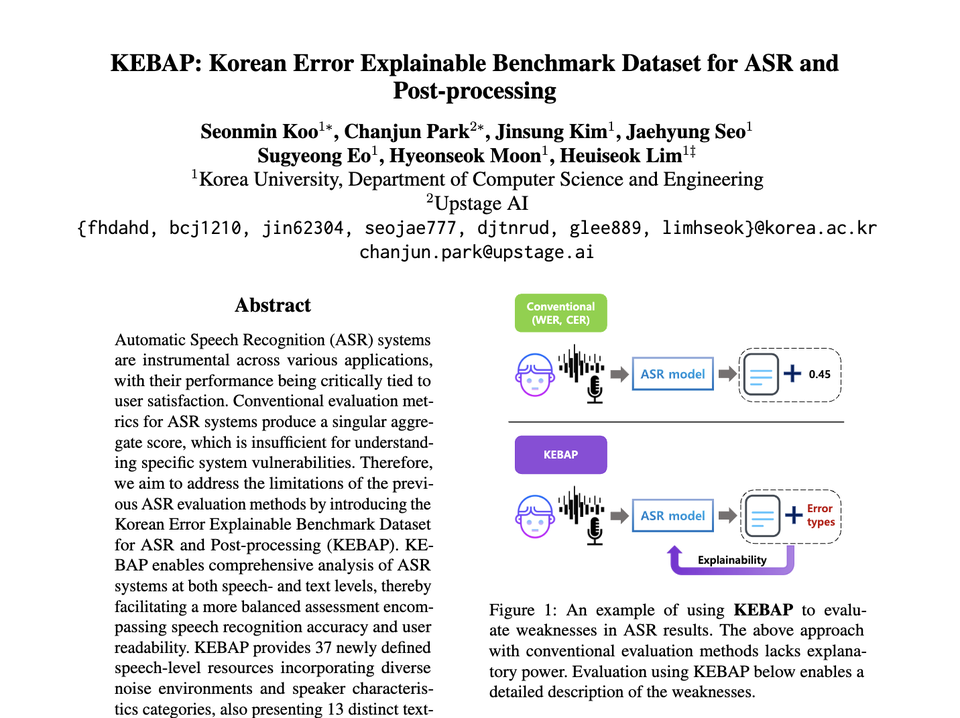
이를 통해 LLM에 대한 전반적인 흐름과 학문적인 지식에 대해 누구나 쉽고 빠르게 습득할 수 있기를..

챗GPT, 바드, 재미나이 등 대화형 생성 AI의 근간이 되는 '대형언어모델(LLM)'에 대해서 누구나 쉽게 입문 할 수 있도록 쉽고 넓게 중점을 둔 업스테이지 연구진이 '초거대 언어모델 연구 동향' 이라는 한국어로 된 LLM 서베이 논문이 한국정보과학회의 정보과학회誌 11월호를 통해 발표됐다.
이번 논문은 국내 대표 생성 AI 멀티모달 스타트업 업스테이지(대표 김성훈)의 이활석 CTO를 비롯한 박찬준 테크 리더, 이원성 테크리더, 김윤기, 김지후 AI 리서치 엔지니어가 공동으로 참여했다.

이번 LLM에 대한 전반적인 기술 서베이 논문을 한국어로 작성하게 된 이유로 박찬준 테크 리더는 "생성 AI가 일상화되면서 LLM에 대해서 많은 분들이 궁금해하시는데, 대부분의 자료가 영어로 어려움을 겪고 있습니다"라며, "이를 통해 LLM에 대한 전반적인 흐름과 학문적인 지식에 대해 누구나 쉽고 빠르게 습득할 수 있기를 바랍니다"라고 전했다.
특히, 업스테이지의 LLM인 ‘SOLAR(솔라)’는 지난 8월 허깅페이스가 운영하는 오픈 LLM 리더보드에서 챗GPT의 벤치마크 점수를 넘는 결과로 세계 1위를 차지했으며, 최근에는 오픈AI 챗GPT, 구글 팜, 메타 라마, 엔트로픽 클로드 등 4개사의 LLM만 기존에 리스트에 올라 고성능 모델의 기준이 된 Poe의 메인 모델에 솔라가 등록돼 또 한 번 글로벌 시장을 놀라게 했다.
업스테이지는 지난 6일부터 10일까지 싱가포르에서 개최되는 자연어 처리(NLP) 분야 세계 최고 수준의 가장 권위 있는 학회인 'EMNLP 2023'에 연구 논문 2편이 채택, 글로벌 톱 AI 기술력을 재확인했다.
또한 지난 6월 Data-Centric AI 분야에서 가장 권위 있는 워크숍인 ICML 2023-DMLR에서 논문 7편을 발표하며 국내 기업 최다 연구 성과를 달성한 바 있다. 업스테이지는 창립 3년 만에 국내외 AI 논문 100편 발표 및 구글 스콜라 랭킹 기준 NLP 분야 컨퍼런스 Top 7에서 모두 논문 채택을 달성하는 쾌거를 이뤘다.
이번 한국어 논문에서는 LLM에 대한 전반적인 동향을 다루고, ▷첫째로 초기의 언어모델부터 현재의 초거대 언어모델까지의 연구 및 발전 과정을 소개한다. ▷둘째로, 한국어 초거대 언어모델의 특징 및 최근 동향을 조명한다. ▷셋째로, 최신 초거대 언어모델 연구 동향을 심층적으로 살펴본다. ▷넷째로, 초거대 언어모델의 성능 평가 방식과 그 변화에 대해 논의한다.
▷마지막으로, 초거대 언어모델 연구와 활용에 있어 중요하게 여겨지는 윤리적 원칙과 관련된 최근의 동향을 소개한다. 본 논문을 통해 초거대 언어모델에 관한 전반적인 동향과 중요한 주제들에 대한 체계적인 이해를 제공하고, 이 분야의 연구자 및 관련 전문가들에게 유용한 통찰과 지침을 제시한다.
한편, 이번 논문 '초거대 언어모델 연구 동향'은 정보과학회지 제41권 제11호에 게재됐으며, 연구자 중심의 한국형 학술정보 포털, DBpia에 공개(다운)돼 있다.