트랜스포머는 라이브러리 상에서 오픈소스로 제공되고 있으며 주로 구글 텐서플로우를 사용하여 구현된다. 텐서플로우의 경우 아파치(Apache 2.0)의 라이선스 규정의 적용을 받는다.
필자, 김용덕은 아이피렉스 특허법률사무소 대표 변리사로 인공지능(AI), 스마트팩토리, 블록체인 등과 같이 4차 산업혁명 기술을 전문적으로 다루는 국내 유명 기업들(LG 전자, 삼성전자, 수아랩, 마키나락스, 샤오미 등)의 지식재산권 업무를 전담한 바 있다.
현재, 조달청에서 인공지능/IoT기술과 관련된 우수 제품 평가 위원으로 활동하고 있으며, 기술특례상장과 관련된 전문 평가 기관의 평가 위원으로 코스닥 상장 심사용 전문 평가 업무를 수행하고 있고, 인공지능 특허 심사 실무 가이드, 상표 유사 판단 이론 및 판례, 기술특례상장 바이블의 저자이다.<편집자 주>
“Attention is all you need”...
이는 인공지능(AI) 개발자라면 누구나 다 알고 있는 문장이다. 이는 2017년 6월에 발표된 구글 브레인, 구글 리서치 등 아시시 바스와니(Ashish Vaswani) 비롯한 8명의 연구원이 제안한 트랜스포머(Transformer-논문 다운) 모델에 관한 논문의 타이틀이다.
주요 시퀀스 변환 모델은 인코더-디코더 구성의 복잡한 순환 또는 컨벌루션 신경망을 기반으로 한다. 최고 성능의 모델은 어텐션 메커니즘을 통해 인코더와 디코더도 연결한다. 구글은 반복과 컨볼루션을 완전히 없애고 주의 메커니즘에만 기반한 새로운 간단한 네트워크 아키텍처인 '트랜스포머(Transformer)'를 제안했다.
'트랜스포머(Transformer)’모델은 오늘날 널리 사용되는 언어 모델의 중추이다. 처음에는 자연어 처리(NLP)를 위해 개발되었지만 여기에 구글은 2020년에 대규모 이미지 인식을 위한 트랜스포머(API 다운)를 발표(Transformers for Image Recognition at Scale-다운)했다. 이를 더해 트랜스포머 모델은 자연어 처리를 넘어 컴퓨터 비전, 약물 발견 등 전 산업에서 활용돼 AI 혁신을 가속하고 있다.

트랜스포머 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망을 의미한다. 어텐션(attention) 또는 셀프어텐션(self-attention)이라 불리며, 진화를 거듭하는 수학적 기법을 응용해 서로 떨어져 있는 데이터 요소들의 의미가 관계에 따라 미묘하게 달라지는 부분까지 감지한다.
최근 큰 이슈 몰이를 하고 있는 오픈AI의 GPT를 비롯한 대부분의 대형언어모델(LLM)과 고성능 자연어 처리 모델들도 마찬가지로 구글 리서치가개발하고 오픈소싱한 신경망 아키텍처인 트랜스포머를 기반으로 구축되었다.
엔비디아 창립자 겸 CEO인 젠슨 황(Jensen Huang)은 지난해 GTC 키노트 발표를 통해 트랜스포머가 “자기지도(self-supervised) 학습을 가능하게 하고, AI가 초고속으로 구동하게 만든다”고 설명했다. 트랜스포머 구조는 많은 단어(문장이나 단락)를 읽도록 훈련할 수 있는 모델을 만들어 내고, 그 단어들이 서로 어떻게 관련되는지에 주의를 기울이고, 그 다음에 어떤 단어가 나올지 예측한다.
또한 스탠퍼드대학교(Stanford University) 인간중심 인공지능연구소(Stanford Institute for Human-Centered Artificial Intelligence, HAI)연구진은 지난해 8월에 발표한 논문(On the Opportunities and Risks of Foundation Models-다운)에서 트랜스포머를 ‘파운데이션 모델’로 일컬은 바 있다.
불과 5년 전까지 가장 인기 있는 딥러닝 모델로 손꼽혔던 컨볼루션 신경망(Convolutional Neural Network. CNN)과 순환신경망(Recurrent neural network. RNN)은 현재, 트랜스포머가 대체하고 있다.
실제로 지난 3년간 아카이브(arXiv)에 게재된 AI 관련 논문의 70%에 트랜스포머가 등장한다. 2017년 전기전자학회(IEEE) 논문에 패턴 인식 분야의 최고 인기 모델로 RNN과 CNN이 보고됐다는 사실을 감안하면 이는 아주 전위적(前衛的)인 변화이다.
자연어 처리(NLP) 태스크에서 가장 중요한 것이 기계 번역이며 기계 번역의 발전 과정을 확인해 보면 1986년도 RNN이 제안되었고, 1997년도에 LSTM이 제안되었다. 그리고, 2014년도에 LSTM과 딥러닝 기반 기술을 활용하는 Seq2Seq가 등장했다.
다만, Seq2Seq는 고정된 크기의 context vector를 사용하는 방식으로 번역을 수행하는 방법을 제안하여 소스 문장을 전부 고정된 크기의 한 vector에 압축해야 할 필요가 있어 성능적인 한계가 존재했다.
이후에 attention 메커니즘이 제안된 논문이 나오면서 Seq2Seq 모델에 attention 메커니즘을 적용하여 성능을 더 끌어올릴 수 있었다. 그 이후 트랜스포머 논문에서는 RNN을 사용할 필요가 없다는 아이디어로 오직 attention 기법에 의존하는 아키텍처를 설계했더니 성능이 훨씬 좋아지는 것을 보여주었다.
즉, 트랜스포머 논문을 기점으로 더 이상 다양한 자연어 처리 태스크에 대해서 RNN 기반의 아키텍처를 거의 사용하지 않고 Attention 메커니즘을 더욱더 많이 사용하게 되었다. 그래서, Attention 메커니즘이 등장한 이후로는 입력 시퀀스 전체에서 정보를 추출하는 방향으로 연구 방향이 발전된 것이다.
트랜스포머는 어텐션(attention) 메커니즘을 사용하여 문장 간 의존성을 효과적으로 학습하며, 병렬 계산이 가능하므로 학습 속도와 효율성이 크게 향상된 모델이다. 최근 인공지능 개발 기업들을 만나보면 자연어 처리, 이미지 분석 등 다양한 분야에서 Self-attention 기반 모델을 활용하고 있는 것을 볼 수 있다.
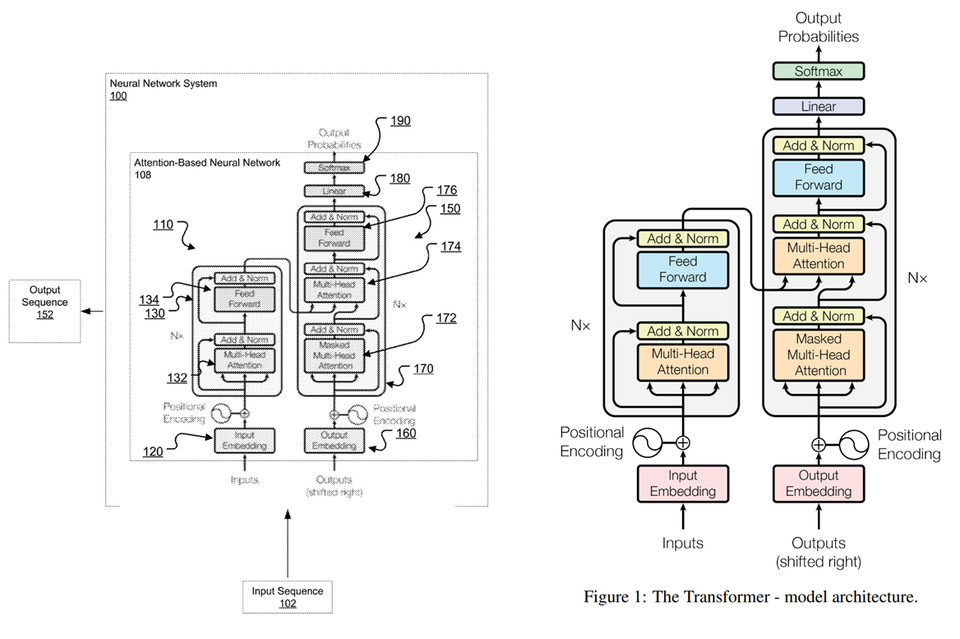
그런데 이렇게 많은 사람들이 사용하고 있는 트랜스포머 모델은 구글이 특허로 보호받고 있다. 논문에 있는 그림과 특허에 있는 도면을 보면 내용이 일치하는 것을 확인할 수 있으며, 논문의 내용과 특허의 내용이 대부분 일치하는 것을 볼 수 있다.
구글은 어떤 내용을 특허로 보호받고 있을까?
트랜스포머 모델과 관련하여 구글은 총 4개의 등록 특허와 2개의 출원 특허를 보유하고 있다. 등록 특허의 내용을 살펴보면 인코더와 관련된 특허(US11113602), 디코더와 관련된 특허(US 10719764), 인코더에 디코더가 결합된 모델 전체 구조와 관련된 특허(US10956819, US 10452978)가 존재하는 것을 확인할 수 있다.
인코더에 디코더가 결합된 모델 전체 구조와 관련된 특허는 인코더와 관련된 특허 및 디코더와 관련된 특허 내용이 결합된 것으로 인코더와 관련된 특허와 디코더와 관련된 특허만 검토해 본다.
인코더와 관련된 특허(US11113602)의 독립항에는 인풋 시퀀스를 입력 받아 인코딩된 표현(임베딩된 인풋)을 생성하고, 셀프 어텐션 매커니즘을 통해 쿼리, 키, 밸류를 결정해서 출력 값을 생성하는 내용이 기재되어 있다.
그리고, 종속항에는 인코더가 stack되어 이전 인코더의 출력이 다음 인코더의 입력으로 이용된다는 내용, Residual Connection 및 Nomalization layer와 관련된 내용, 위치 임베딩을 인코딩된 표현에 더한다는 내용 등이 포함되어 있다.
디코더와 관련된 특허(US10719164)의 독립항에는 어텐션 매커니즘을 통해 현재 출력 위치와 현재 출력 위치 이전 위치에 대한 입력에 대해서만(마스킹을 수행하는 것을 이와 같이 표현함) 쿼리, 키, 밸류를 결정해서 출력 값을 생성하는 내용이 기재되어 있다. 그리고, 종속항에는 인코더-디코더 어텐션의 동작과 관련된 내용, Residual Connection 및 Nomalization layer와 관련된 내용 등이 포함되어 있다.
트랜스포머 모델에 이용되는 핵심적인 내용들이 구글의 특허로 보호되고 있는 것을 볼 수 있다. 그럼 과연 트랜스포머 모델을 이용해서 서비스를 제공해도 괜찮은 것일까?

트랜스포머는 라이브러리 상에서 오픈소스로 제공되고 있으며 주로 텐서플로우를 사용하여 구현된다. 구글의 텐서플로우의 경우 아파치(Apache 2.0)의 라이선스 규정의 적용을 받는다. 아파치에서는 특허 출원이 된 소스 코드의 사용자에게 특허의 사용을 허가하고 있다.
그럼 Apache 2.0의 특허 허여(許與) 조항은?
위 내용을 살펴보면 원칙적으로 텐서플로우 라이브러리 상의 오픈소스에는 특허 라이선스를 부여한다. 따라서, 구글을 상대로 특허권을 행사하는 등의 적극적 액션을 취하는 경우가 아니라면 라이선스가 부여되기 때문에 트랜스포머 모델을 이용하여 서비스를 제공해도 문제가 발생할 가능성이 낮다.
최근에는 인공지능 기술에 대한 빠른 발전을 위해 많은 라이브러리에서 오픈 소스를 제공하고 있다. 따라서, 오픈 소스로 제공된 기술을 많은 사람들이 자유롭게 사용하고 있다. 하지만, 오픈 소스로 제공된 소스 코드를 이용하는 경우 항상 특허 침해로부터 안전한 것은 아니기 때문에 라이선스 규정을 잘 살펴보고, 현재 사용하고 있는 기술에 대응되는 특허 내용도 같이 살펴보는 것을 추천한다.