베트남, 인도네시아, 태국 등 현지 관심, 스타일, 법적 규정에 부합하는 LLM 출시로 다양한 언어 및 문화 환경 반영

알리바바그룹의 글로벌 AI 연구 이니셔티브인 다모 아카데미(DAMO Academy)는 130억 개 매개변수와 70억 개 매개변수 버전으로 제공되는 선구적인 거대 언어 모델(LLM) ‘SeaLLM(Southeast Asia LLM)’을 19일 오픈소스로 공개했다.
동남아시아의 언어적 다양성을 충족하기 위해 특별히 설계된 SeaLLM은 기술의 포용성 측면에서 압도적인 도약을 이뤘다.
SeaLLM의 두 모델은 베트남어, 인도네시아어, 태국어, 말레이어, 크메르어, 라오스어, 타갈로그어, 버마어 등 해당 지역에서 실제로 사용되는 현지 언어와 호환되어 최적화된 지원을 제공한다.
대화형 모델인 SeaLLM-챗(SeaLLM-chat)은 동남아시아의 각 시장 고유의 문화적 구조에 대한 적응성을 토대로 현지 관습, 스타일, 법적 프레임워크에 부합하는 맞춤형 조정이 가능해 동남아시아 시장에 진출하는 기업에게 매우 유용한 챗봇 지원 도구로 부상하고 있다.
리동 빙(Lidong Bing) 알리바바 다모 아카데미 언어 기술 연구소 소장은 "기술 격차를 해소하기 위한 지속적인 노력을 통해 개발한 AI모델 ‘SeaLLM’을 소개하게 되어 기쁘다”며 “현지 언어뿐만 아니라 동남아시아의 풍부한 문화를 수용하는 SeaLLM은 AI의 민주화를 앞당겨 디지털 영역에서 소외되어 온 커뮤니티에 힘을 실어줄 것이다”고 말했다.
알리바바의 다국어 인공지능 연구 분야 장기 파트너인 난양공과대학(Nanyang Technological University)의 루안 투안(Luu Anh Tuan) 컴퓨터과학 및 공학부(SCSE) 조교수는 "포용적인 기술발전을 위한 알리바바의 인상적인 행보는 다국어 LLM인 SeaLLM의 출시로 이정표에 도달했다”며 “이 이니셔티브는 영어, 중국어 이외의 언어를 사용하는 수백만 명의 사람들에게 새로운 기회를 제공할 수 있는 잠재력을 갖는다”고 말했다.
SeaLLM의 기본 모델은 동남아시아의 언어를 포함한 다양한 고품질 데이터 세트에 대한 사전 교육을 거쳐 현지 상황과 모국어 커뮤니케이션에 대한 미묘한 이해를 보장한다. 이 작업은 정교한 미세 조정 기술과 맞춤형 다국어 데이터 세트를 활용하는 SeaLLM 채팅 모델의 기초를 마련해 해당 모델을 기반으로 하는 챗봇 어시스턴트는 사회적 규범과 관습, 문체 선호도, 법적 고려 사항 등 해당 언어의 문화적 맥락을 이해하고 존중함에 따라 정확히 반영할 수 있다.
특히 SeaLLM의 주목할 만한 기술적 장점은 비라틴계 언어에 대한 효율성이 높다는 점이다. 버마어, 크메르어, 라오스어, 태국어 등 비라틴계 언어에 대해 ChatGPT 등의 모델보다 최대 9배 더 긴 텍스트를 해석하고 처리하거나, 동일한 길이의 텍스트에 대해 더 적은 수의 토큰을 사용하여 복잡한 작업을 실행하고, 운영 및 컴퓨팅 비용을 절감하고 환경 발자국을 감소시킨다.
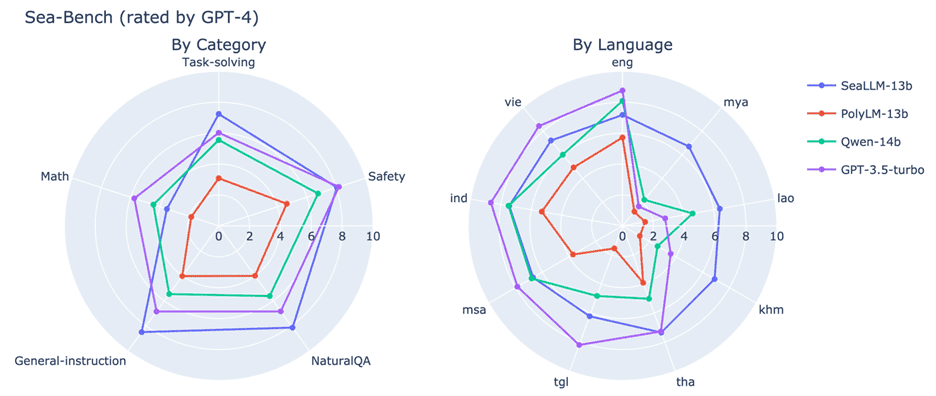
한편, 130억 개의 파라미터를 갖춘 SeaLLM-13B는 광범위한 언어, 지식 관련 및 안전 작업에서 동급의 오픈 소스 모델을 능가해 LLM 성능에 대한 새로운 기준을 제시한다. SeaLLM은 초등학교부터 대학 입시까지 시험지로 구성된 벤치마크인 M3Exam에서 동남아시아 언어로 된 과학, 화학, 물리학, 경제학 등의 다양한 과목을 심도 있게 이해해 동급 모델보다 뛰어난 성능을 보였다.
또한 라오스어, 크메르어 등 대화형 AI 시스템 학습을 위한 데이터가 제한적인 저자원 언어와 영어 간의 기계 번역 능력을 평가하는 플로레스(FLORES) 벤치마크에서도 SeaLLM은 기존 모델을 능가했으며, 베트남어, 인도네시아어 등 대부분의 고자원 언어에서는 최첨단(SOTA) 모델과 동등한 수준의 성능을 제공한다.
알리바바 다모 아카데미의 SeaLLM 시리즈는 일차원적인 AI의 발전이 아닌 보다 포용적인 디지털 미래를 향한 발걸음으로, 보다 자세한 기능과 영향력은 허깅 페이스(Hugging Face)의 프로젝트 페이지 혹은 기술 보고서에서 확인할 수 있다.
한편 이날 공개한 SeaLLM의 관련 논문 'SeaLLM- 동남아시아를 위한 대규모 언어 모델(SeaLLMs- Large Language Models for Southeast Asia-다운)'란 제목으로 아카이브에 발표됐다. 관련 코드는 현재, 깃허브(다운) 또는 허깅 페이스(다운)를 통해 연구 및 상업적 용도로 사용할 수 있다.