이 모델은 웹과 앱, 공개 인터넷 및 기타 소스 등에서 2억 7천만 개의 동영상과 10억 개 이상의 텍스트-이미지 쌍에 대해 사전 학습하고, 해당 데이터를 텍스트 임베딩, 비주얼 토큰 및 오디오 토큰으로 전환하여 AI 모델을 조건화...
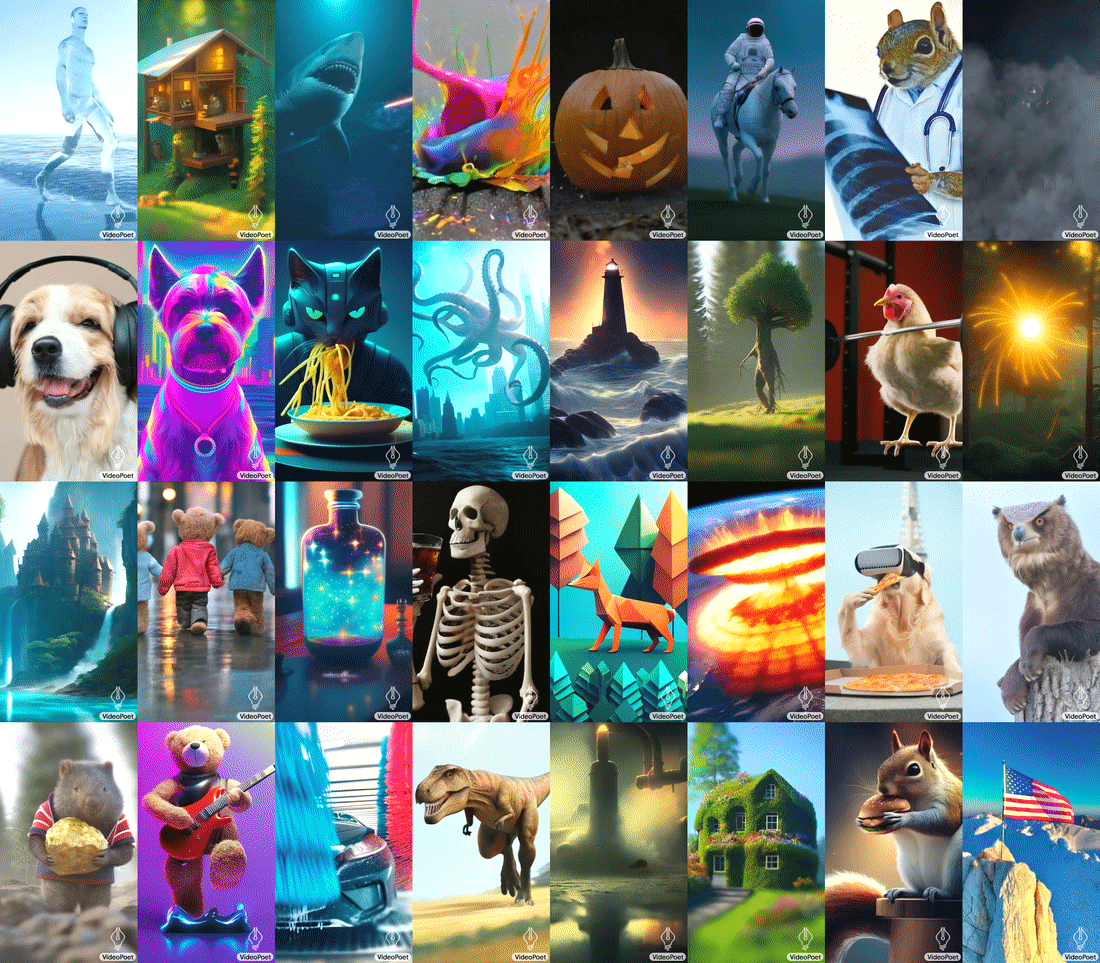
최근 놀라운 화질을 구현하는 동영상 생성 인공지능 모델이 등장하고 있으며, 다수의 경우 놀라운 화질을 선보이고 있다. 현재, 비디오 생성의 병목 현상 중 하나는 일관된 대형 모션을 생성하는 기능이다. 그러나 주요 모델조차도 작은 모션을 생성하거나 큰 모션을 생성할 때 눈에 띄는 아티팩트(Artifacts)가 나타나는 경우가 많다.
여기에 31명의 연구원으로 구성된 구글 리서치(Google Research) 연구팀이 비디오 생성에서 언어 모델의 적용을 탐색하기 위해 텍스트 대 비디오, 이미지 대 비디오, 비디오 스타일화 등 다양한 비디오 생성 작업을 수행할 수 있는 대형언어모델(LLM)인 '비디오시인(VideoPoet. 이하, 비디오포엣)'을 공개했다.
이 모델은 웹과 앱, 공개 인터넷 및 기타 소스 등에서 2억 7천만 개의 동영상과 10억 개 이상의 텍스트-이미지 쌍에 대해 사전 학습하고, 해당 데이터를 텍스트 임베딩, 비주얼 토큰 및 오디오 토큰으로 전환하여 AI 모델을 조건화(Conditioned) 했다.

비디오 인페인팅 및 아웃페인팅, 비디오-오디오 등에서 한 가지 주목할 만한 점은 선도적인 비디오 생성 모델이 거의 전적으로 디퓨전(확산) 기반이라는 점이다(예: Imagen Video 참조). 반면 LLM은 언어, 코드 및 오디오(예 오디오PaLM 말하고 들을 수 있는 대규모 언어 모델-참조)를 포함한 다양한 양식에 걸친 탁월한 학습 능력으로 인해 사실상의 표준으로 널리 인정받고 있다.
이 분야의 다른 인공지능 모델과 달리 구글 AI 연구팀의 접근 방식은 각 작업을 전문으로 하는 별도로 훈련된 구성 요소에 의존하지 않고 단일 LLM 내에 여러 비디오 생성 기능을 원활하게 통합한다는 것이다.
비디오포엣의 다양한 기능은 입력 이미지를 애니메이션화하여 모션을 생성할 수 있으며(선택적으로 자르거나 마스킹한), 비디오를 편집하여 인페인팅 또는 아웃페인팅할 수 있다. 스타일화의 경우, 모션을 나타내는 깊이와 광학적 흐름을 나타내는 비디오를 가져와서 그 위에 콘텐츠를 페인팅하여 텍스트 안내 스타일을 생성한다(아래 그림 참조).
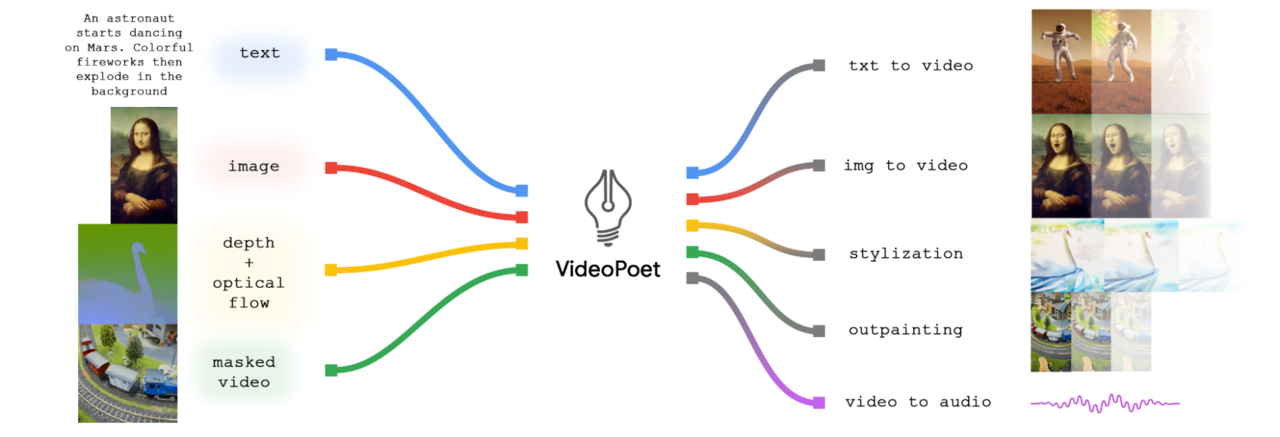
비디오 생성기로서의 언어 모델
훈련에 LLM을 사용하는 주요 이점 중 하나는 기존 LLM 학습 인프라에 도입된 확장 가능한 효율성 개선 사항을 재사용할 수 있다는 점이다. 하지만 LLM은 개별 토큰에서 작동하므로 비디오 생성이 어려울 수 있다.
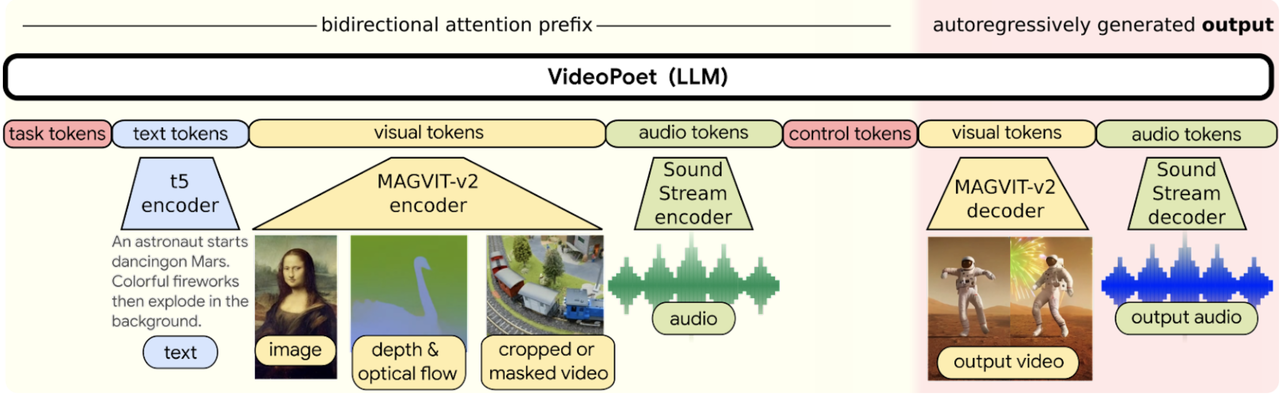
다행히도 비디오(확산을 능가하는 언어 모델: 토크나이저는 시각적 생성의 핵심-보기)와 오디오 클립(SoundStream: 엔드투엔드 신경 오디오 코덱-다운)을 불연속 토큰(즉, 정수 인덱스)의 시퀀스로 인코딩하는 역할을 하며 원래의 표현으로 다시 변환할 수 있는 비디오 및 오디오 토큰화 도구가 있다.
비디오포엣은 여러 토큰화 도구(비디오 및 이미지의 경우 MAGVIT V2, 오디오의 경우 SoundStream)를 사용하여 비디오, 이미지, 오디오 및 텍스트 양식에 걸쳐 학습하도록 자동 회귀 언어 모델(Autoregressive model)을 훈련한다. 모델이 특정 컨텍스트에 따라 조건부 토큰을 생성하면 토큰라이저 디코더를 통해 다시 보기 쉬운 표현으로 변환할 수 있다.
아래는 비디오포엣이 텍스트 생성된 영상 예


아래는 이미지-비디오의 경우, VideoPoet은 입력 이미지를 가져와 프롬프트로 애니메이션을 적용할 수 있다.

아래는 비디오 스타일화를 위해 몇 가지 추가 입력 텍스트와 함께 VideoPoet에 공급하기 전에 광학 흐름 및 깊이 정보를 예측한다.

특히, VideoPoet은 오디오도 생성할 수 있다. 여기서는 먼저 모델에서 2초 길이의 클립을 생성한 다음 텍스트 안내 없이 오디오를 예측한다. 이를 통해 단일 모델에서 비디오 및 오디오를 생성할 수 있다.
기본적으로 VideoPoet 모델은 짧은 형식 콘텐츠에 맞게 출력을 조정하기 위해 세로 방향으로 비디오를 생성한다. 그 기능을 선보이기 위해 구글 AI 연구팀은 VideoPoet에서 생성된 많은 짧은 클립으로 구성된 간단한 동영상을 제작했다(아래 영상).
여기서 대본을 위해 '바드(Bard-보기)'에게 장면별 분석과 그에 따른 프롬프트 목록을 포함하여 여행하는 너구리에 대한 짧은 이야기를 작성하도록 요청했다. 그런 다음 각 프롬프트에 대한 비디오 클립을 생성하고 결과 클립을 모두 연결하여 최종 비디오를 제작했다.
긴 영상에서는 비디오의 마지막 1초를 조건으로 하고 다음 1초를 예측함으로써 더 긴 비디오를 생성할 수 있다. 이를 반복적으로 연결함으로써 모델이 비디오를 잘 확장할 수 있을 뿐만 아니라 여러 번의 반복에도 불구하고 모든 개체의 모양을 충실하게 보존할 수 있다.
아래는 텍스트 입력에서 긴 비디오를 생성하는 VideoPoet의 두 가지 예다.


또한 VideoPoet에서 생성된 기존 비디오 클립을 대화식으로 편집하는 것도 가능하다. 입력 비디오를 제공하면 객체의 모션을 변경하여 다양한 작업을 수행할 수 있다. 개체 조작은 첫 번째 프레임이나 중간 프레임의 중앙에 집중될 수 있으므로 높은 수준의 편집 제어가 가능하다. 예를 들어, 입력 비디오에서 일부 클립을 무작위로 생성하고 원하는 다음 클립을 선택할 수 있다.

아울러, 입력 이미지에 모션을 적용하여 텍스트 프롬프트에 따라 원하는 상태로 콘텐츠를 편집할 수 있다.

구글 리서치 연구팀은 다양한 벤치마크를 통해 텍스트-투-비디오 생성에 대한 비디오포엣을 평가하여 다른 접근 방식과 결과를 비교했다. 중립적인 평가를 위해 특정 예시를 선택하지 않고 다양한 프롬프트에서 모든 모델을 실행하고 사람들에게 선호도를 평가하도록 요청했다. 아래 그림은 다음 질문에 대해 비디오포엣이 선호 옵션으로 선택된 비율을 녹색으로 강조 표시한 것이다.
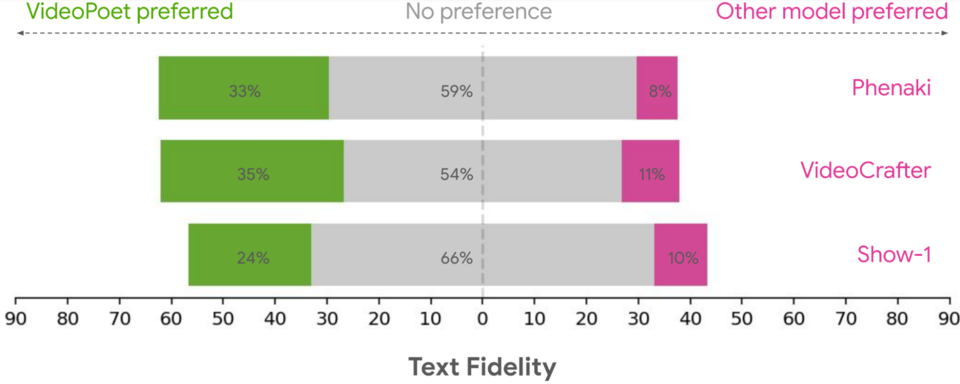
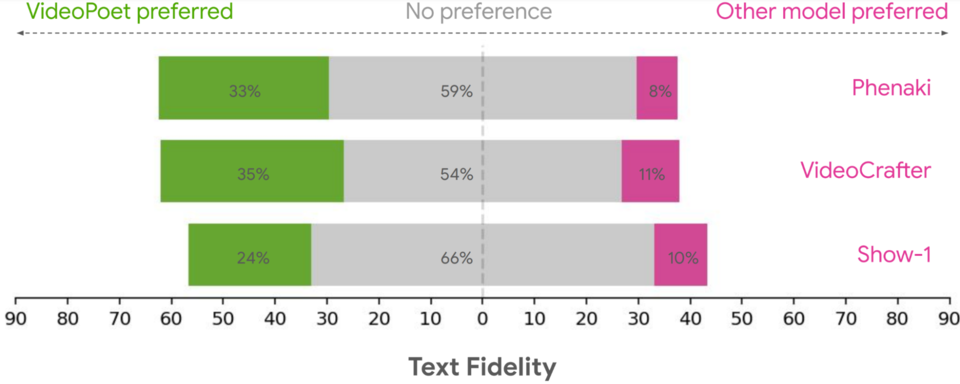
위의 내용을 바탕으로, 평균적으로 사람들은 VideoPoet에서 24–35%의 예제를 경쟁 모델보다 더 나은 프롬프트로 선택했다. 평가자들은 또한 다른 모델의 11–21%보다 더 흥미로운 움직임을 위해 VideoPoet에서 41–54%의 예제를 더 선호했다.
VideoPoet을 통해 우리는 다양한 작업, 특히 비디오 내에서 흥미롭고 고품질 모션을 생성하는 데 있어 LLM의 경쟁력 있는 비디오 생성 품질을 입증했습니다. 우리의 결과는 비디오 생성 분야에서 LLM의 유망한 잠재력을 시사합니다. 향후 방향을 위해 우리 프레임워크는 "모든 대 임의" 생성을 지원할 수 있어야 합니다. 예를 들어 텍스트에서 오디오로, 오디오에서 비디오로, 비디오 캡션으로 확장하는 것이 가능해야 합니다.
VideoPoet을 통해 구글 리서치 연구팀은 특히 비디오 내에서 흥미롭고 고품질의 모션을 제작하는 등 다양한 작업에서 LLM의 경쟁력 있는 비디오 생성 품질을 입증했다. 결과는 비디오 생성 분야에서 LLM의 유망한 잠재력을 시사한다.
한편, 이번 연구 및 결과는 'VideoPoet: 제로샷 비디오 생성을 위한 대규모 언어 모델(VideoPoet: A Large Language Model for Zero-Shot Video Generation-다운)'란 제목으로 지난 21일 아카이브를 통해 공개됐다. 모델에 대한 더 자세한 내용 또는 고품질의 더 많은 예제를 보려면 해당 웹 사이트(보기)를 참고하면 된다.