
매개변수(Parameter)를 기존 대형언어모델(Large language models. 이하, LLM)에 비해 변수의 수가 60억(6B) 내지 100억(10B) 개로 줄여 학습을 위한 소요 비용이나 시간을 절감할 수 있으며, 미세조정(Fine-Tuning)으로 정확도를 높이고 다른 애플리케이션과 통합하기도 쉬운 모델을 '경량화 대형언어모델(smaller Large Language Model. 이하, sLLM)'이라고 한다.
특히, 특정 분야에서는 미세조정과 고품질의 데이터 학습을 통해 기존 LLM과 맞먹는 성능을 보여주는 것도 장점이다. 대표적으로 메타의 사전학습모델 ‘라마 2 7B(Llama 2 7B-다운), 구글의 온디바이스 작업을 위해 제작된 모델 '제미나이 나노(Gemini Nano-다운)', 영어와 코드 그리고 8k 컨텍스트 창을 지원하는 ‘미스트랄 7B(Mistral 7B-코드 다운/논문 다운)’ 등은 엣지에서 추론, 언어 이해, 수학, 코딩 등의 성능을 발휘한다.
특히 Mistral 7B는 논문을 통해 평가된 모든 벤치마크에서 라마 2 13B를 능가하고 추론, 수학 및 코드 생성에서는 라마 1 34B를 능가한다고 밝혔다.
여기에, 마이크로소프트는 지난해 12월 12일 ‘파이 2(Phi-2)’를 오픈 소스로 출시하고 이 모델은 ‘라마 2 모노’, ‘미스트랄 7B’, 구글 ‘제미나이 나노' 등 다른 모델과 추론, 언어 이해, 수학, 코딩 및 상식 능력을 비교하는 벤치마크에서 더 뛰어난 성능을 제공한다고 밝혔다.
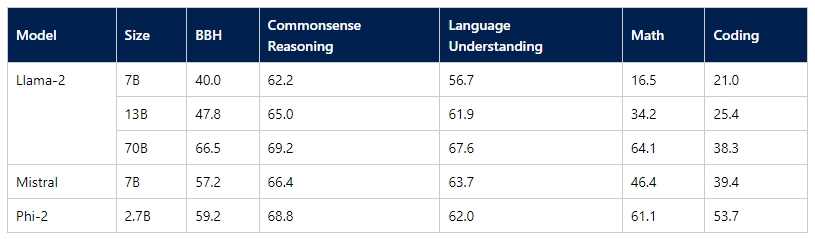

지난 11월, 다양한 AI 생성 텍스트로 구성된 추가 데이터에 대해 훈련받은 13억 매개변수의 '파이-1.5'에 이은 2.7B의 매개변수로 구성된 이 sLLM ‘파이-2는 전 세계 13B 미만의 매개변수를 사용하는 언어 모델 중에서 최고 성능을 제공하며, 최대 25배 더 큰 모델과 일치하거나 성능이 뛰어나다고 덧붙였다.
한편, 출시 당시 파이-2는 상업적 사용이 아닌 연구 목적으로만 사용할 수 있어 사용에 제약이 따랐으나 마이크로소프트 리서치(Microsoft Research)의 대규모 언어 모델의 새로운 인텔리전스 이해 및 개선을 위한 과학자 그룹 'AGI의 물리학(Physics of AGI)'의 구스타보 데 로사(Gustavo de Rosa) 박사는 6일(현지시간), 허깅 페이스(Hugging Face)를 통해 파이-2는 기존 'MS 라이센스'가 'MIT 라이센스'로 변경됐다며, 이제 누구나 등록을 통해 무료(다운)로 사용할 있다고 밝혔다.