제미나이 1.5 프로'는 한번에 70만 개 이상의 단어, 3만 줄의 코드, 1시간 분량의 동영상, 11시간 분량의 음성에 해당하는 방대한 양의 정보를 한 번에 처리할 수 있다.한국을 비롯한 180개 이상의 국가 및 지역에서 38개 언어로 출시

구글이 15일(현지시간) 정교한 멀티모달 추론 기능을 갖춘 대화형 생성 인공지능(Generative AI) '제미나이'의 차세대 모델인 '제미나이 1.5(Gemini 1.5)'를 전격 출시했다.
이날 데미스 하사비스(Demis Hassabis) 구글 딥마인드(Google DeepMind) CEO는 "제미나이 1.5 프로는 획기적으로 향상된 성능을 제공한다"고 밝혔다.
이는 기반 모델 개발 및 인프라의 거의 모든 부분에 걸친 연구 및 엔지니어링 혁신을 기반으로 한 접근 방식의 한 단계 변화를 의미한다. 여기에는 새로운 '전문가 혼합(Mixture-of-Experts, MoE) 아키텍처를 통해 제미나이 1.5의 학습 및 서비스 효율을 높이는 것도 포함된다.
이날 출시된 제미나이 1.5의 첫 번째 모델은 '제미나이 1.5 프로(Gemini 1.5 Pro)'로 이는 다양한 작업에 걸쳐 확장하는 데 최적화된 중형 멀티모달 모델이며, 현재까지 가장 큰 모델인 제미나이 1.0 울트라(Ultra)와 유사한 성능을 발휘한다. 또한 긴 문맥 이해에 대한 획기적인 실험적 기능도 도입했다.
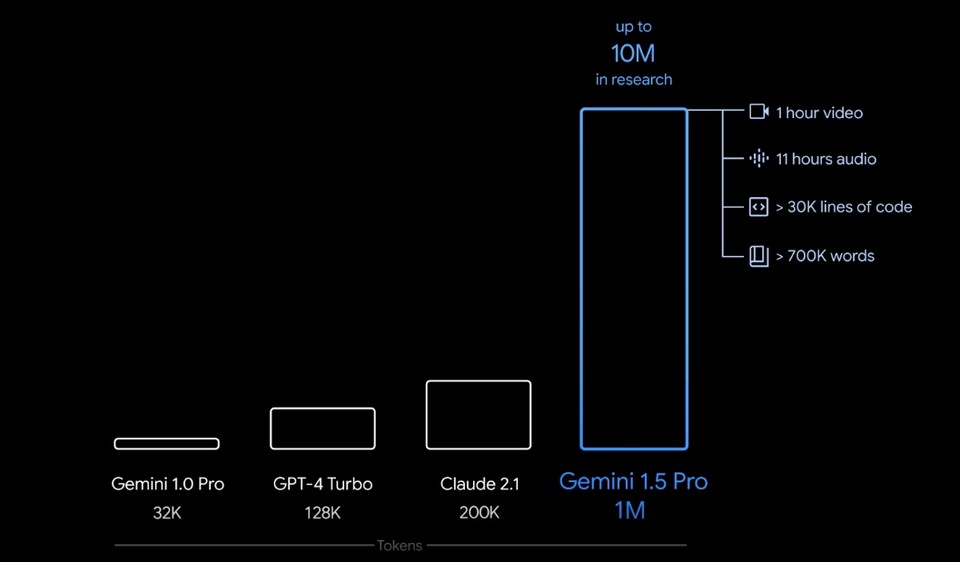
'제미나이 1.5 프로'는 128,000개의 토큰 컨텍스트 창이 기본으로 제공된다. 15일부터 제한된 개발자 그룹과 기업 고객은 비공개 미리 보기(보기)에서 등록할 수 있으며, AI 스튜디오(AI Studio-보기) 및 버텍스 AI(Vertex AI-보기)를 통해 최대 100만 개 토큰 컨텍스트 창을 통해 사용해 볼 수 있다.
구글 인공지능 스튜디오는 제미나이 모델을 구축하는 가장 빠른 방법이며 개발자가 애플리케이션에 제미나이 API를 쉽게 통합할 수 있도록 해주며 한국을 비롯한 180개 이상의 국가 및 지역에서 한국어를 포함한 38개 언어(보기)로 제공된다 .
특히, '제미나이 1.5 프로'에서는 한번에 입력할 수 있는 데이터가 대폭 늘어난 것으로 70만 개 이상의 단어, 3만 줄의 코드, 1시간 분량의 동영상, 11시간 분량의 음성에 해당하는 방대한 양의 정보를 한 번에 처리할 수 있음을 의미한다. 구글은 자체 연구에서는 최대 천만 개의 토큰을 성공적으로 테스트했다고 밝혔다.
또한 '제미나이 1.5 프로'는 방대한 양의 정보에 대한 멀티 추론기능으로 주어진 프롬프트 내에서 많은 양의 콘텐츠를 원활하게 분석, 분류 및 요약할 수 있다. 예를 들어, 아폴로 11호의 달 탐사에서 나온 402페이지 분량의 녹취록이 주어지면, 문서 전반에서 발견된 대화, 사건 및 세부 정보에 대해 각 추론할 수 있다.
아울러, 더 나은 이해와 다중 추론능력으로 비디오를 포함한 다양한 양식에 대해 매우 정교한 이해 및 추론 작업을 수행할 수 있다. 예를 들어, 44분짜리 무성 영화인 버스터 키튼(Buster Keaton) 영화(보기)가 주어지면 모델은 다양한 줄거리와 사건을 정확하게 분석할 수 있으며 영화에서 쉽게 놓칠 수 있는 작은 세부 사항까지 추론할 수 있다.(멀티모달 프롬프트 '제미나이 1.5 프로' 데모 영상)
또한 더 긴 코드 블록에서 보다 관련성이 높은 문제 해결 작업을 수행할 수 있다. 100,000줄 이상의 코드가 포함된 프롬프트가 제공되면 예제를 통해 더 나은 추론을 할 수 있고 유용한 수정 사항을 제안하며, 코드의 다양한 부분이 어떻게 작동하는지에 대한 설명을 제공할 수 있다.
한편, 구글에 따르면 텍스트, 코드, 이미지, 오디오 및 비디오 평가의 포괄적인 패널에서 테스트했을 때, 대형언어모델(LLM)을 개발하는 데 사용되는 벤치마크의 87%에서 제미나이 1.5 프로가 '제미나이 1.0 프로' 보다 우수한 성능을 보였다고 한다. 또한 동일한 벤치마크에서 제미나이 1.0 울트라와 비교했을 때 대체로 비슷한 수준의 성능을 발휘한다.
제미나이 1.5 프로는 컨텍스트 창이 커짐에도 불구하고 높은 수준의 성능을 유지한다. 특정 사실이나 진술이 포함된 작은 텍스트 조각을 긴 텍스트 블록 안에 의도적으로 배치하는 NIAH(Needle In A Haystack-보기) 평가에서 최대 100만 토큰의 데이터 블록에서 99%의 확률로 포함된 텍스트를 찾아냈다.
제미나이 1.5 프로는 또한 인상적인 '문맥 내 학습(in-context learning)' 기술을 보여주는데, 이것은 추가적인 파인튜닝(미세조정) 없이 긴 프롬프트에서 주어진 정보로부터 새로운 기술을 학습할 수 있다는 것을 의미한다.
제미나이 1.5 프로는 이전에 본 적이 없는 정보에서 얼마나 잘 학습하는지 보여주는 MTOB(Machine Translation from One Book-다운/논문:A BENCHMARK FOR LEARNING TO TRANSLATE A NEW LANGUAGE FROM ONE GRAMMAR BOOK- 다운) 벤치마크에서 이 기술을 테스트했으며, 또 전 세계적으로 사용자가 200명 미만인 언어인 칼라망(Kalamang-보기)어 문법 매뉴얼(보기)이 프롬포트에 주어졌을 때, 이 모델은 동일한 콘텐츠를 통해 학습하는 사람과 비슷한 수준으로 영어를 칼라망어로 번역하는 방법을 학습했다.
한편, 제미나이 1.5 프로의 더 자세한 내용은 기술보고서 '제미나이 1.5: 수백만 개의 컨텍스트 토큰에 대한 멀티모달 이해 잠금 해제(Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context-다운)'을 참고하면 된다.